分代收集理论
- 弱分代假说(Weak Generational Hypothesis):绝大多数对象都是朝生夕灭的
- 强分代假说(Strong Generational Hypothesis):熬过越多次垃圾收集过程的对象就越难以消亡
- 跨代引用假说(Intergenerational Reference Hypothesis):跨代引用相对于同代引用来说仅占极少数

Serial收集器
JVM参数
-XX:+UseSerialGC
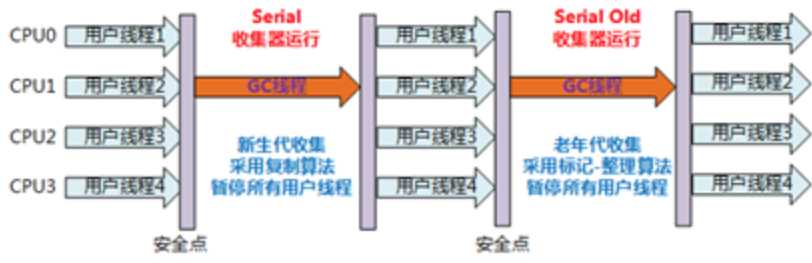
Serial(串行)垃圾收集器是最基本、发展历史最悠久的收集器;
JDK1.3.1前是HotSpot新生代收集的唯一选择;
- 针对新生代;
- 采用复制算法;
- 单线程收集;
- 进行垃圾收集时,必须暂停所有工作线程,直到完成;即会”Stop The World”;
应用场景
对于限定单个CPU的环境来说,Serial收集器没有线程交互(切换)开销,可以获得最高的单线程收集效率
在用户的桌面应用场景中,可用内存一般不大(几十M至一两百M),可以在较短时间内完成垃圾收集(几十MS至一百多MS),只要不频繁发生,这是可以接受的
Serial Old收集器
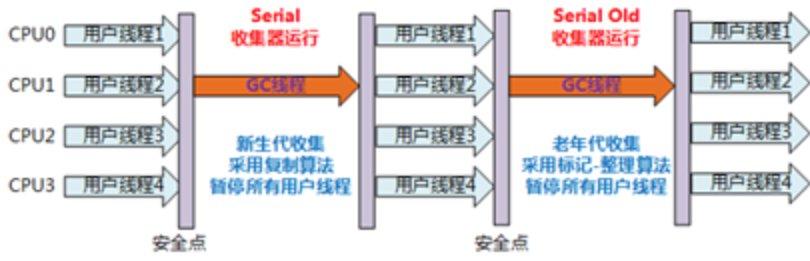
Serial Old是 Serial收集器的老年代版本
- 针对老年代
- 采用”标记-整理”算法(还有压缩,Mark-Sweep-Compact)
- 单线程收集
应用场景
主要用于Client模式;
作为CMS收集器的后备预案,在并发收集发生Concurrent Mode Failure时使用
ParNew收集器
JVM参数
-XX:+UseConcMarkSweepGC 指定使用CMS后,会默认使用ParNew作为新生代收集器
-XX:+UseParNewGC 强制指定使用ParNew
-XX:ParallelGCThreads 指定垃圾收集的线程数量,ParNew默认开启的收集线程与CPU的数量相同
ParNew/Serial Old组合收集器运行示意图如下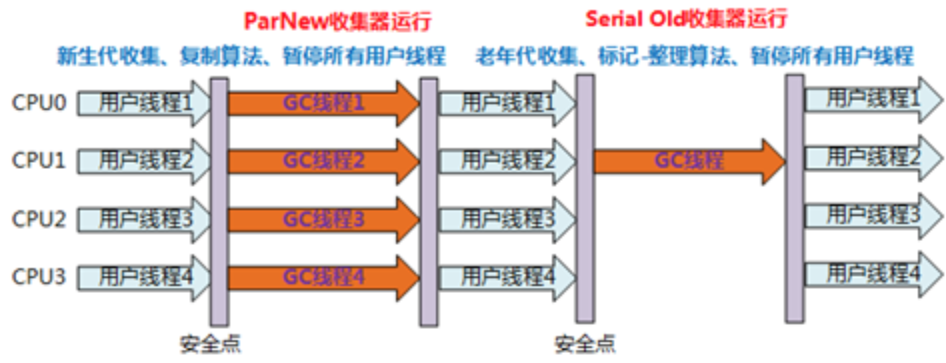
应用场景
在Server模式下,ParNew收集器是一个非常重要的收集器,因为除Serial外,目前只有它能与CMS收集器配合工作
但在单个CPU环境中,不会比Serail收集器有更好的效果,因为存在线程交互开销
Parallel Scavenge收集器
Parallel Scavenge垃圾收集器因为与吞吐量关系密切,也称为吞吐量收集器(Throughput Collector)
- 新生代收集器;
- 采用复制算法;
- 多线程收集;
应用场景
高吞吐量为目标,即减少垃圾收集时间,让用户代码获得更长的运行时间;
当应用程序运行在具有多个CPU上,对暂停时间没有特别高的要求时,即程序主要在后台进行计算,而不需要与用户进行太多交互;
例如,那些执行批量处理、订单处理、工资支付、科学计算的应用程序;
Parallel Old垃圾收集器是Parallel Scavenge收集器的老年代版本
Parallel Old收集器
JVM 参数
-XX:+UseParallelOldGC 指定使用Parallel Old收集器
- 针对老年代
- 采用”标记-整理”算法;
- 多线程收集
Parallel Scavenge/Parallel Old收集器运行示意图如下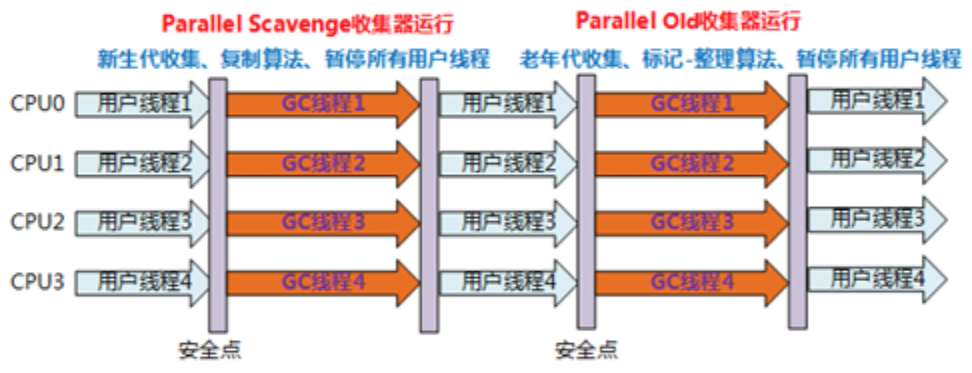
CMS(Concurrent Mark-Sweep)算法
CMS(Concurrent Mark-Sweep)是以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器。对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。CMS是用于对tenured generation的回收,也就是年老代的回收,目标是尽量减少应用的暂停时间,减少full gc发生的几率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代
CMS过程
- 初始标记(STW initial mark) *暂停应用
- 并发标记(Concurrent marking)
- 并发预清理(Concurrent precleaning)
- 重新标记(STW remark) * 暂停 应用
- 并发清理(Concurrent sweeping)
-
CMS 缺点
CMS回收器采用的基础算法是Mark-Sweep。所以CMS不会整理、压缩堆空间。这样就会有一个问题:经过CMS收集的堆会产生空间碎片。 CMS不对堆空间整理压缩节约了垃圾回收的停顿时间,但也带来的堆空间的浪费。为了解决堆空间浪费问题,CMS回收器不再采用简单的指针指向一块可用堆空 间来为下次对象分配使用。而是把一些未分配的空间汇总成一个列表,当JVM分配对象空间的时候,会搜索这个列表找到足够大的空间来hold住这个对象
- 需要更多的CPU资源。从上面的图可以看到,为了让应用程序不停顿,CMS线程和应用程序线程并发执行,这样就需要有更多的CPU,单纯靠线程切 换是不靠谱的。并且,重新标记阶段,为空保证STW快速完成,也要用到更多的甚至所有的CPU资源。当然,多核多CPU也是未来的趋势!
CMS的另一个缺点是它需要更大的堆空间。因为CMS标记阶段应用程序的线程还是在执行的,那么就会有堆空间继续分配的情况,为了保证在CMS回 收完堆之前还有空间分配给正在运行的应用程序,必须预留一部分空间。也就是说,CMS不会在老年代满的时候才开始收集。相反,它会尝试更早的开始收集,已 避免上面提到的情况:在回收完成之前,堆没有足够空间分配!默认当老年代使用68%的时候,CMS就开始行动了。 – XX:CMSInitiatingOccupancyFraction =n 来设置这个阀值。
G1(Garbage First)算法
在G1算法中,采用了另外一种完全不同的方式组织堆内存,堆内存被划分为多个大小相等的内存块(Region),每个Region是逻辑连续的一段内存,结构如下:
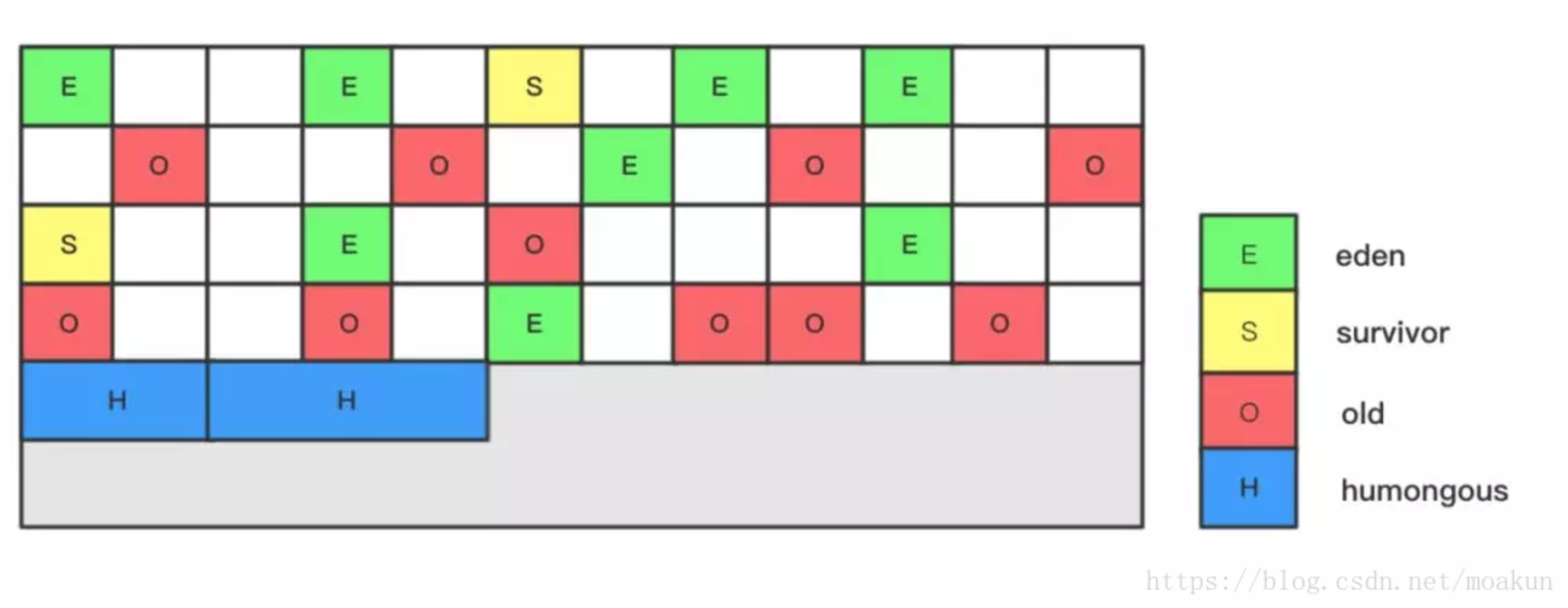
每个Region被标记了E、S、O和H,说明每个Region在运行时都充当了一种角色,其中H是以往算法中没有的,它代表Humongous,这表示这些Region存储的是巨型对象(humongous object,H-obj),当新建对象大小超过Region大小一半时,直接在新的一个或多个连续Region中分配,并标记为H。G1的GC模式
Young GC 回收的是所有年轻代的Region。当E区不能再分配新的对象时就会触发。E区的对象会移动到S区,当S区空间不够的时候,E区的对象会直接晋升到O区,同时S区的数据移动到新的S区,如果S区的部分对象到达一定年龄,会晋升到O区。Yung GC过程示意图如下:

Mixed GC
Mixed GC 翻译过来叫混合回收。之所以叫混合是因为回收所有的年轻代的Region+部分老年代的Region。
部分老年代是参数-XX:MaxGCPauseMillis,用来指定一个G1收集过程目标停顿时间,默认值200ms,当然这只是一个期望值。G1的强大之处在于他有一个停顿预测模型(Pause Prediction Model),他会有选择的挑选部分Region,去尽量满足停顿时间
Mixed GC的触发也是由一些参数控制。比如XX:InitiatingHeapOccupancyPercent表示老年代占整个堆大小的百分比,默认值是45%,达到该阈值就会触发一次Mixed GC。Mixed GC主要可以分为两个阶段:
全局并发标记(global concurrent marking)
全局并发标记又可以进一步细分成下面几个步骤:初始标记(initial mark,STW)。它标记了从GC Root开始直接可达的对象。初始标记阶段借用young GC的暂停,因而没有额外的、单独的暂停阶段。
- 并发标记(Concurrent Marking)。这个阶段从GC Root开始对heap中的对象标记,标记线程与应用程序线程并行执行,并且收集各个Region的存活对象信息。过程中还会扫描上文中提到的SATB write barrier所记录下的引用。
- 最终标记(Remark,STW)。标记那些在并发标记阶段发生变化的对象,将被回收。
清除垃圾(Cleanup,部分STW)。这个阶段如果发现完全没有活对象的region就会将其整体回收到可分配region列表中。 清除空Region。
拷贝存活对象(Evacuation)
Evacuation阶段是全暂停的。它负责把一部分region里的活对象拷贝到空region里去(并行拷贝),然后回收原本的region的空间。Evacuation阶段可以自由选择任意多个region来独立收集构成收集集合(collection set,简称CSet),该阶段并不evacuate所有有活对象的region,只选择收益高的少量region来evacuate,这种暂停的开销就可以(在一定范围内)可控
Full GC
G1的垃圾回收过程是和应用程序并发执行的,当Mixed GC的速度赶不上应用程序申请内存的速度的时候,Mixed G1就会降级到Full GC,使用的是Serial GC。Full GC会导致长时间的STW,应该要尽量避免。导致G1 Full GC的原因可能有两个:
Evacuation的时候没有足够的to-space来存放晋升的对象;
- 并发处理过程完成之前空间耗尽

若有收获,就点个赞吧
0 人点赞
