跳表是基于链表的。

需要注意的是,跳表只能用于链表里面的元素是有序的情况下。
跳表的实现
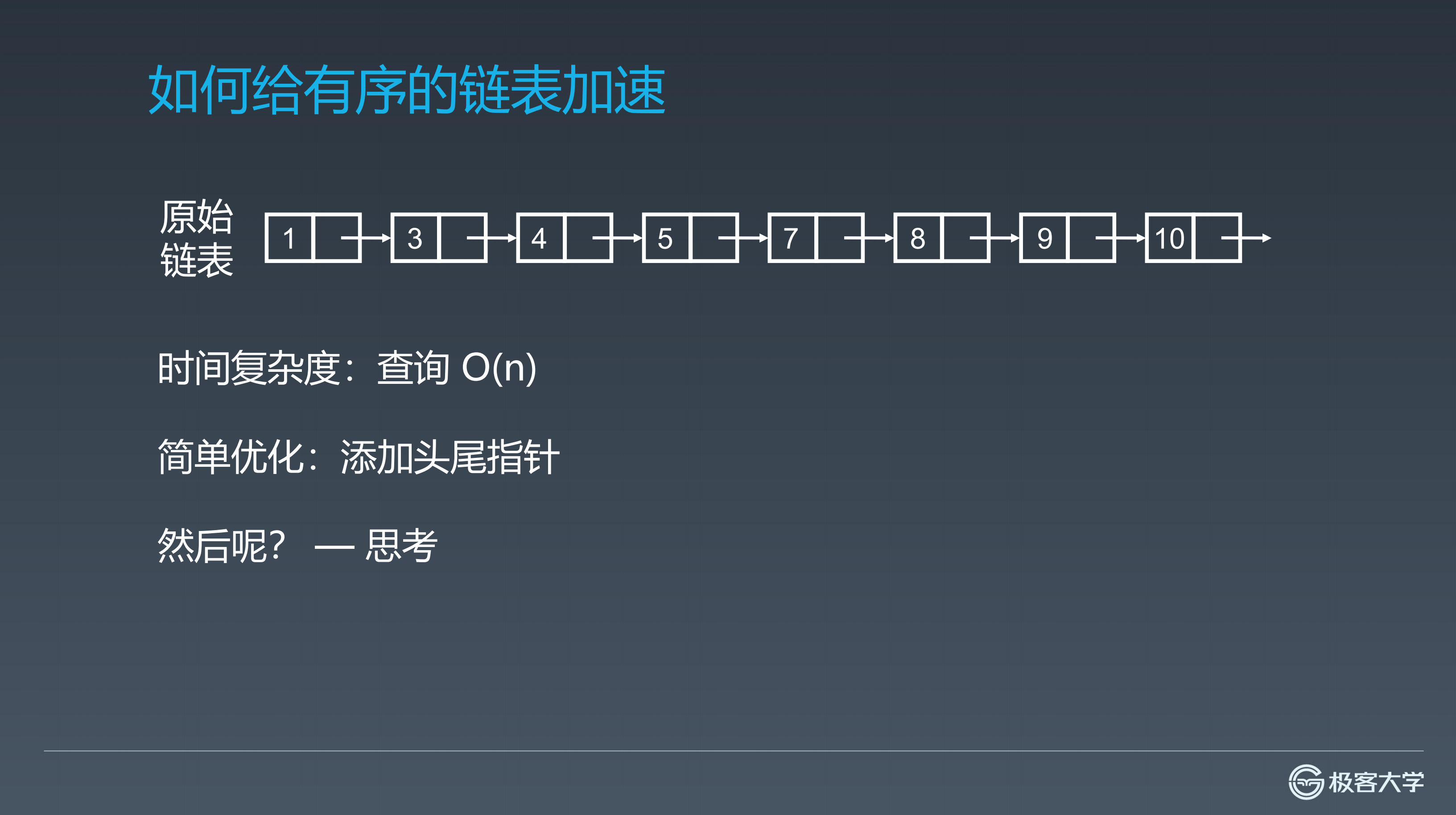
假设有一个链表,它的元素分别是1、3、4、5、7、8、9、10。它的查询时间复杂度是  ,那么如何进行优化能够降低链表查询的时间复杂度(给链表加速)?
,那么如何进行优化能够降低链表查询的时间复杂度(给链表加速)?
一般来说,一维数据要加速的话,经常采用的方法就是升维,也就是变成二维。因为多一层维度之后,就会有多一层信息在里面。多一层的信息就帮助你可以很快地得到一维里面你必须挨个走才能走到的元素。
我们看下面的例子:
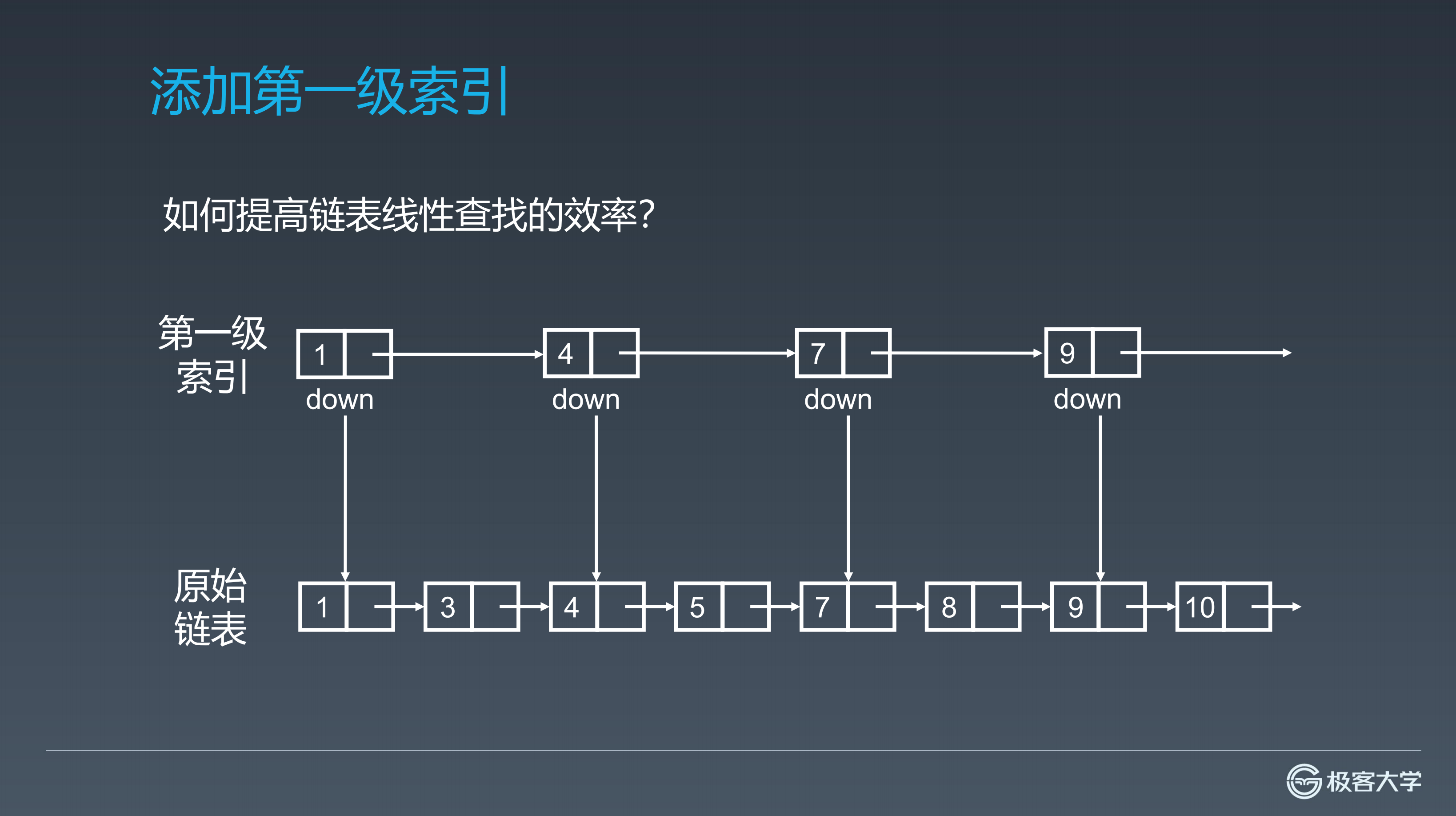
在原始链表的基础上,增加一个维度(第一级索引)。第一级索引所指向的并不是元素的 next ,而是元素的 next.next ,我们理解为 next+1 即可。
假设要找7这个元素,它会首先在第一级索引中先寻找有没有7这个元素,如果有则表示已经查询到7这个元素。假设要找8这个元素,在第一级索引中,找到8是存在与7和9之前的元素中,因此会从7向下走到原始链表去挨个元素地找8。
加了一级索引之后搜索的步长从原来1变成2,搜索速度也就是比原来快一点。那么速度还能不能加快呢?同理,我们还可以在第一级索引的基础之上,去构建第二级的索引,步长相当于第一的两倍,这样的话速度就更快了。
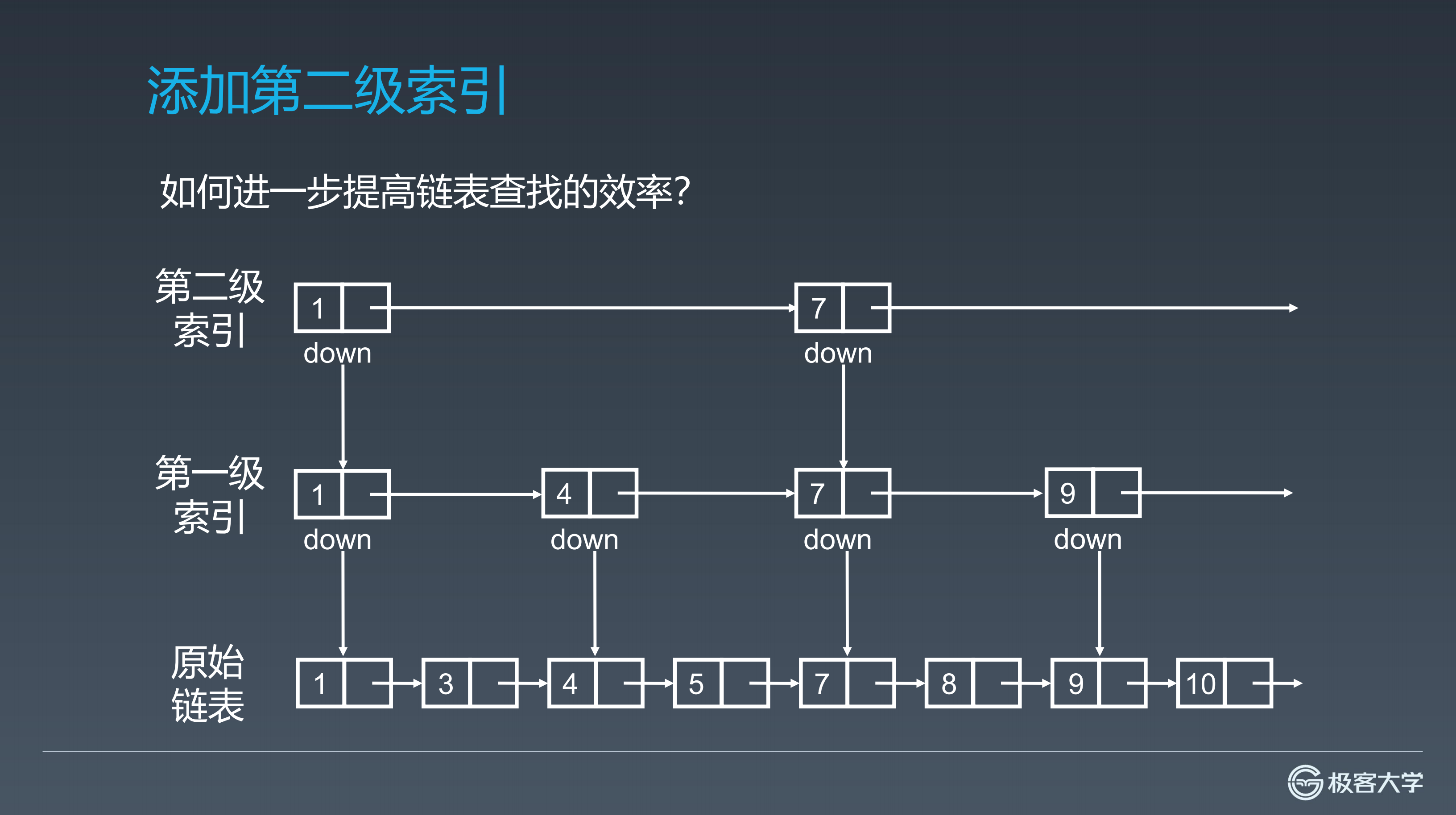
以此类推,添加多级的索引来增加搜索速度。


若有收获,就点个赞吧
0 人点赞
