概要
对于小型定向爬虫,在确定爬取站点后,需要对目标进行详细的分析。分析的主要目的是捋清站点数据请求的逻辑,方便后续数据的重新组织存储到数据库或文件中。
爬虫分析结构
爬虫的本质是模拟人的行为去获取目标站点数据,我们可以直接对某一请求接口(URL)直接发起伪造请求获取数据,也可以模拟人的操作站点“一点一点”获取数据。不论是上面的哪一种,目标分析是必不可少的。
现如今,大多数的站点需要与人进行交互才能获取更多的数据。因此在对目标进行分析时,需要搞清楚什么样的操作会触发什么样的请求,这个过程描述为逻辑图中的两个步骤:请求接口的分析与请求逻辑的分析。
样例分析
以新浪微博为例,按照上面的逻辑,分析如下:
浏览器打开 https://m.weibo.cn/ 页面后进入调试页面。
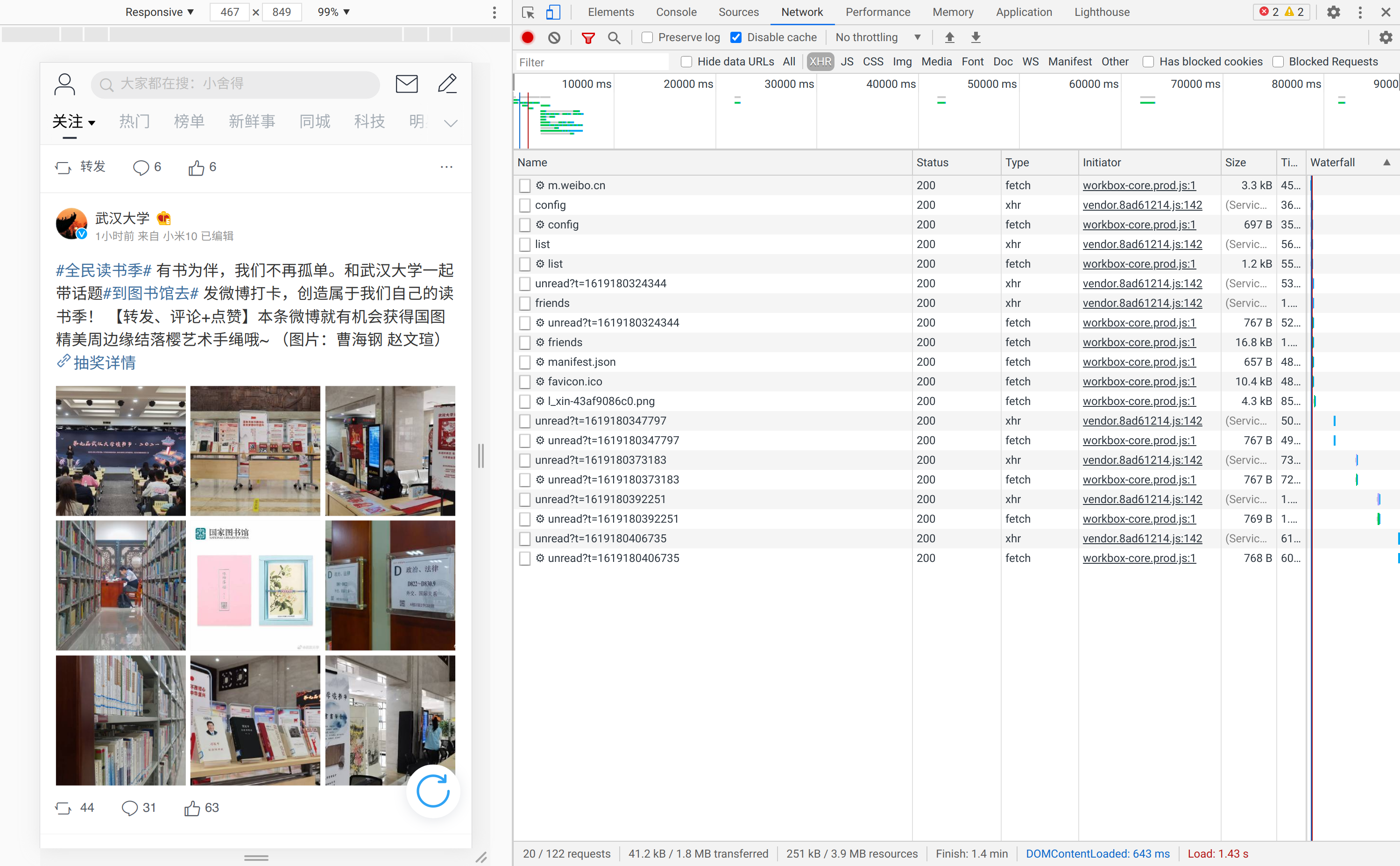
右边为所有的XHR(XML HTTP Request)请求,与人进行交互后触发的请求是我们分析的重点。我们以人工智能关键词的页面进行详细分析。输入人工智能然后搜索,会得到如下的页面: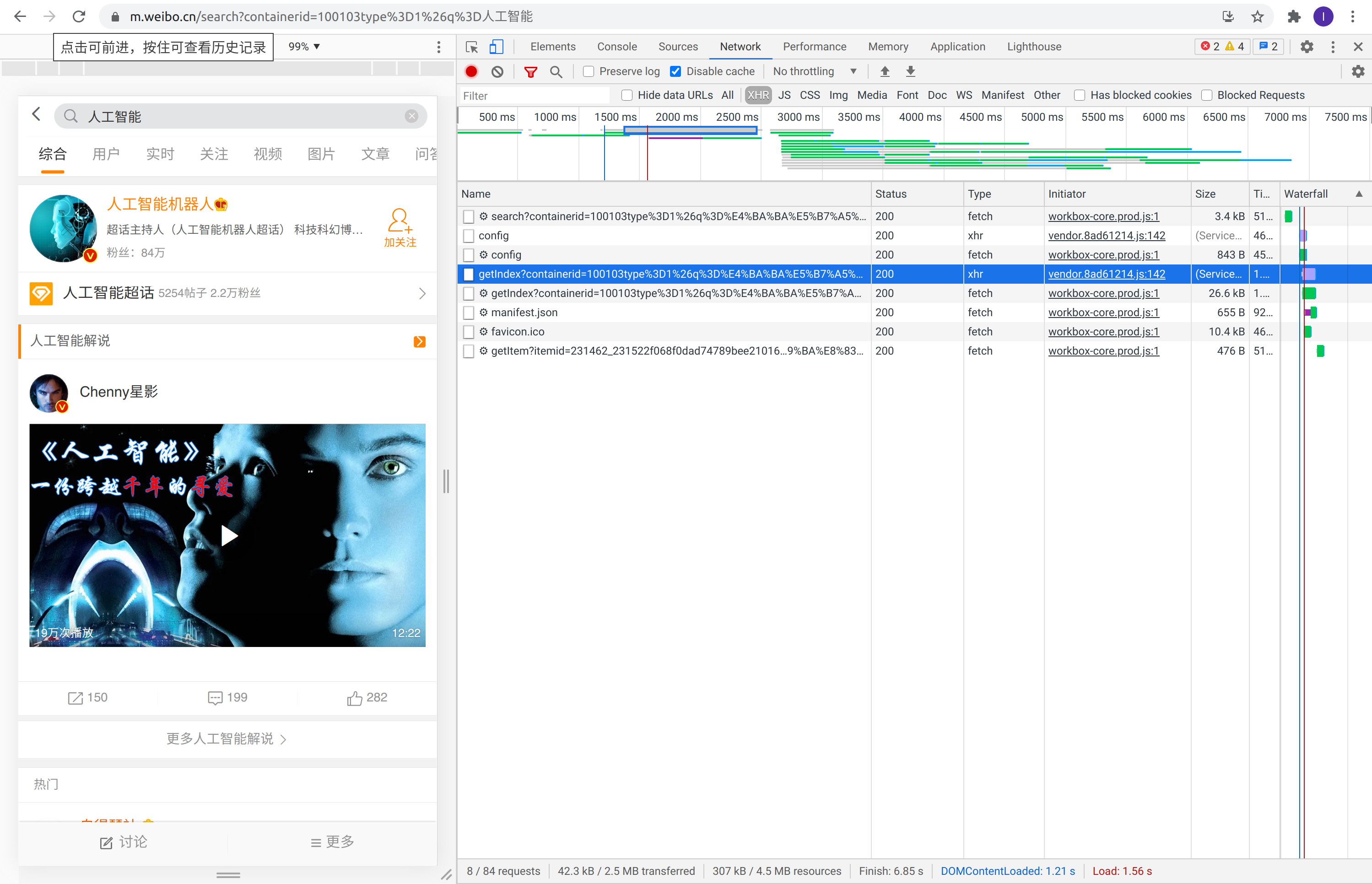
搜索关键词为人工智能的请求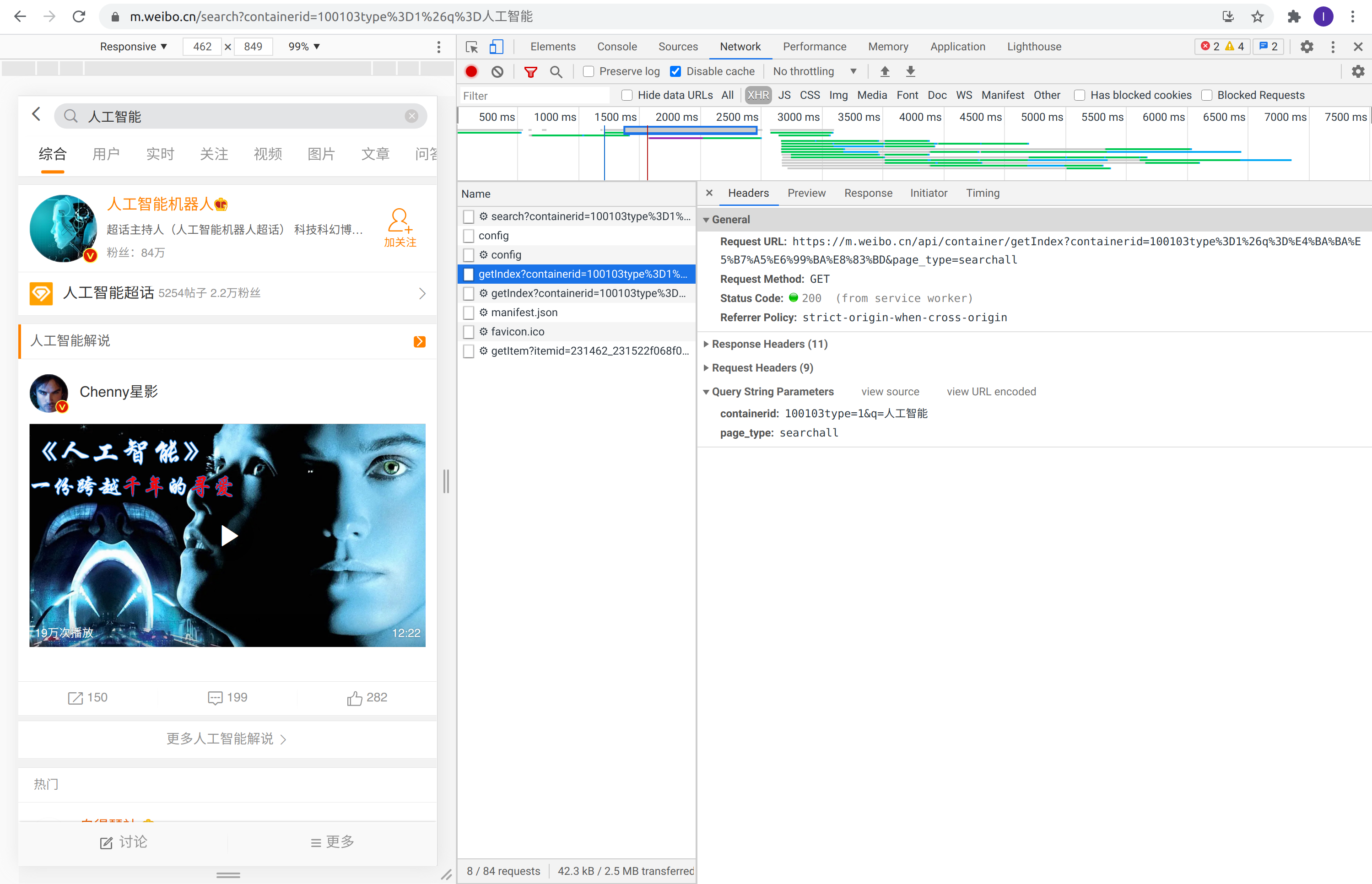
请求接口为 getIndex 的详细情况
可以看出在 HTTP 请求的 Headers 中,请求的参数(Query String Parameters)中有两个字段,第一个为搜索的关键词第二个为搜索的类型。要想爬取更多的含有人工智能的页面,需要继续往下滑动页面,下滑之后的请求如下图所示: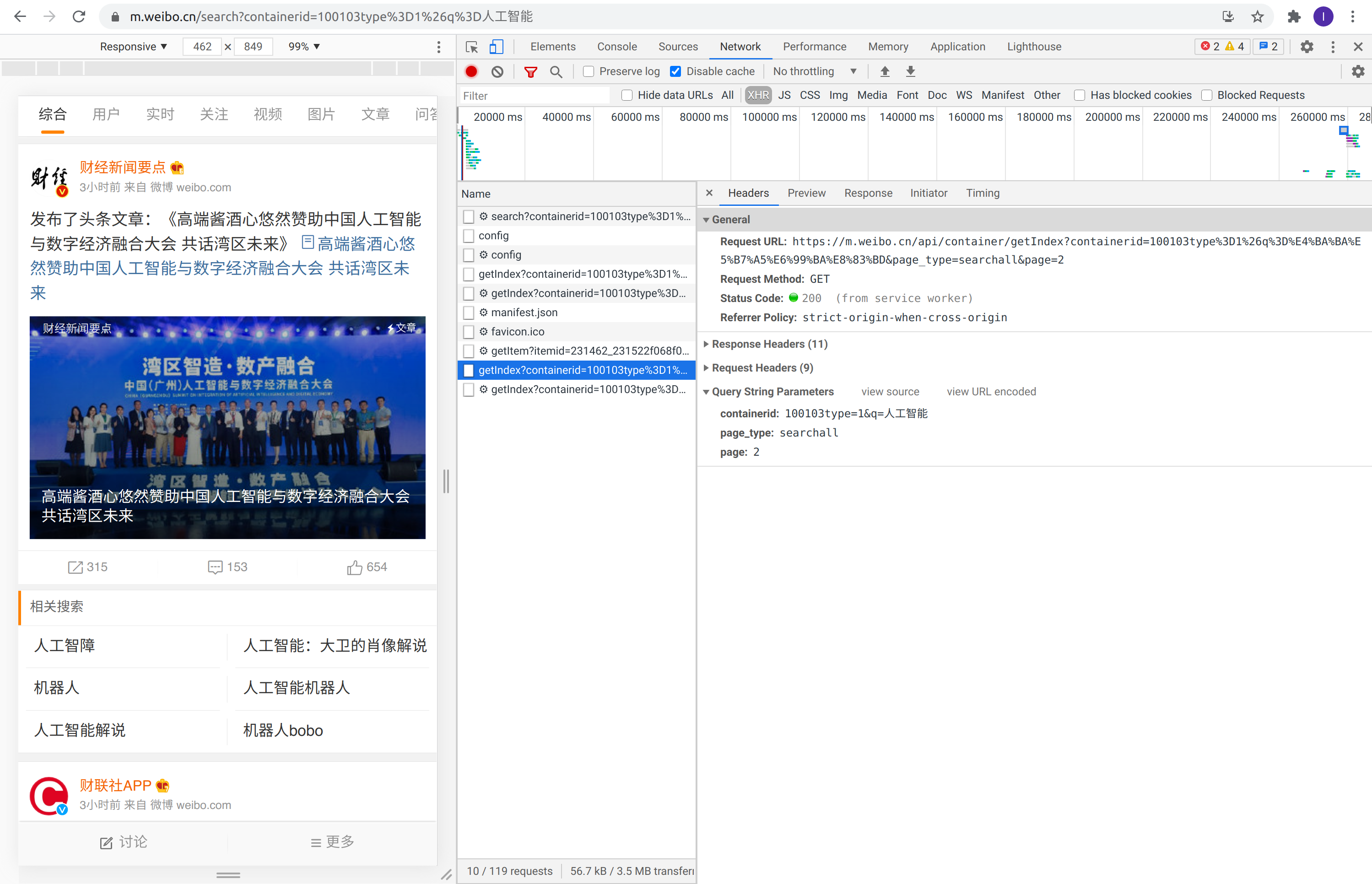
第二页数据的请求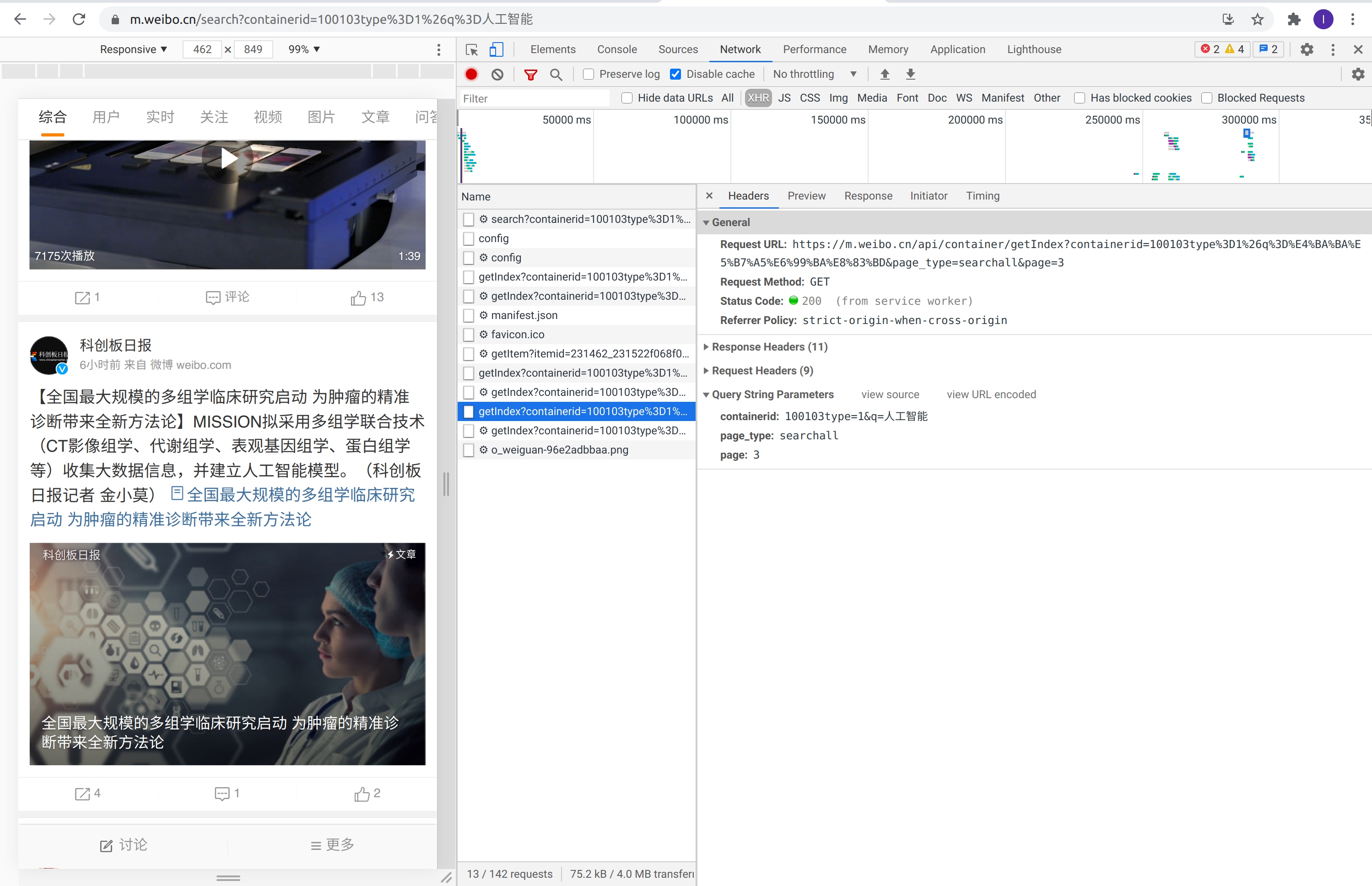
第三页数据的请求
由此可见,交互后不同页的接口数据请求逻辑为:
向url为[https://m.weibo.cn/api/container/getIndex?](https://m.weibo.cn/api/container/getIndex?)发起请求,请求的参数为containerid=100103type%3D1%26q%3D%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&page_type=searchall&page=3,。其中发生变化的是page=2、page=3…
接下来,我们看看第一页请求的数据是什么样子的。
翻回到第一页,查看 HTTP 请求的 Preview,如下图所示: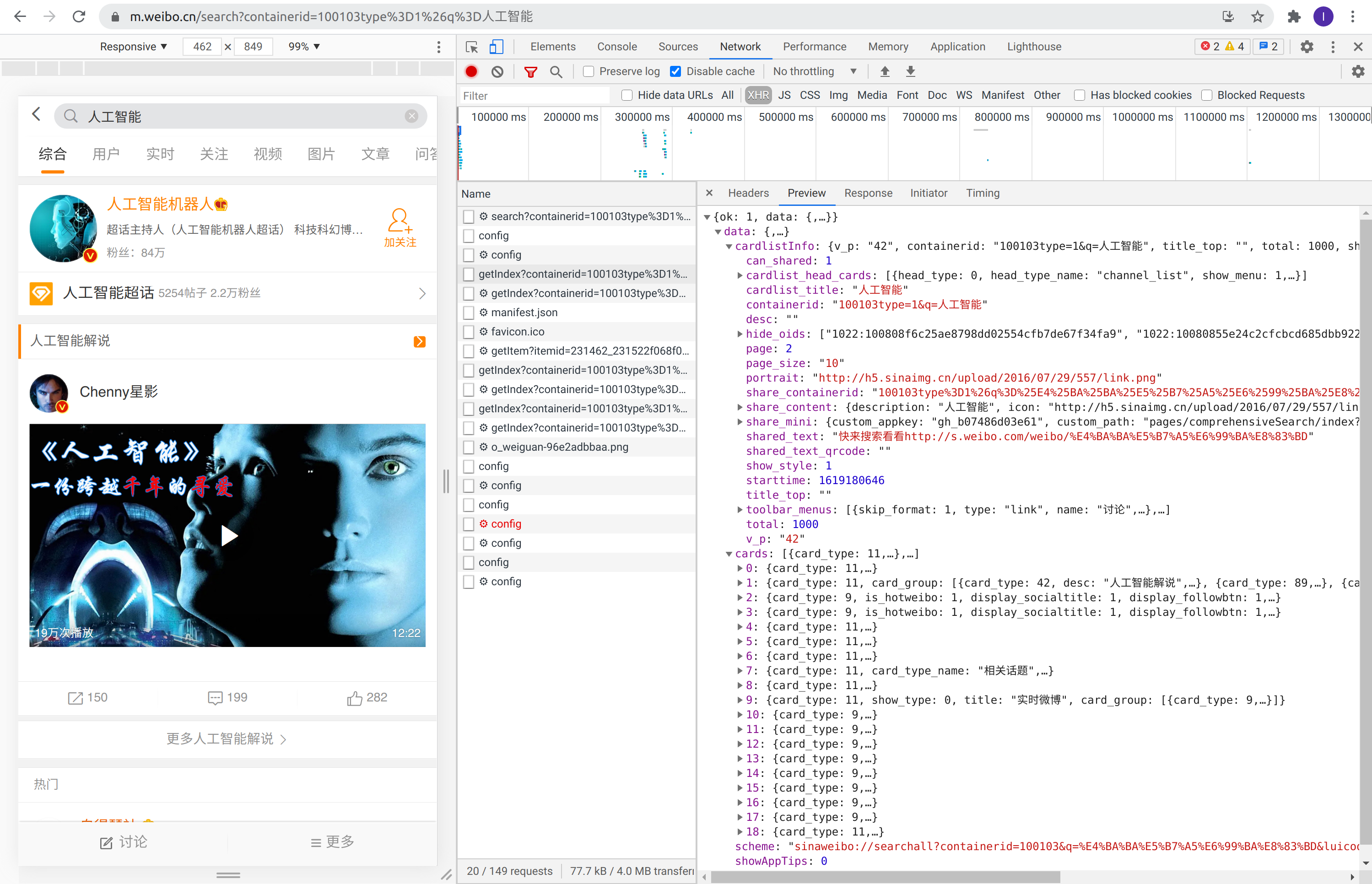
HTTP 响应中的数据组织形式
可以看出,返回的数据是 json 格式,不同的 key 对应着不同的 value。通过分析我们可以知道其各个 key 所表达的含义如下表所示:
微博接口数据字段含义
自此,以微博为例的接口分析第一部分结束。

若有收获,就点个赞吧
0 人点赞
