数据维度
文档 Document
- 所有可搜索数据的最小单元
- 序列化成JSON保存
- 每个文档生成Unique ID,可自动生成
- 包含一些元数据
索引 Index
- 同种文档的集合
- 设置Mapping
- 定义文档的字段名和字段类型
- 设置Setting
- 物理空间概念,Index中的数据分散在shard上,定义数据分布
- B树索引
- 倒排索引
关系型数据库的简单对应
| RDBMS | ES |
|---|---|
| Table | Index |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | DSL |
运维维度
高可用
- 服务可用 - 允许有节点停止服务
- 数据可用 - 部分节点丢失,不会丢失数据
可扩展
- 请求量/数据量的增长,将数据分布到所有节点上
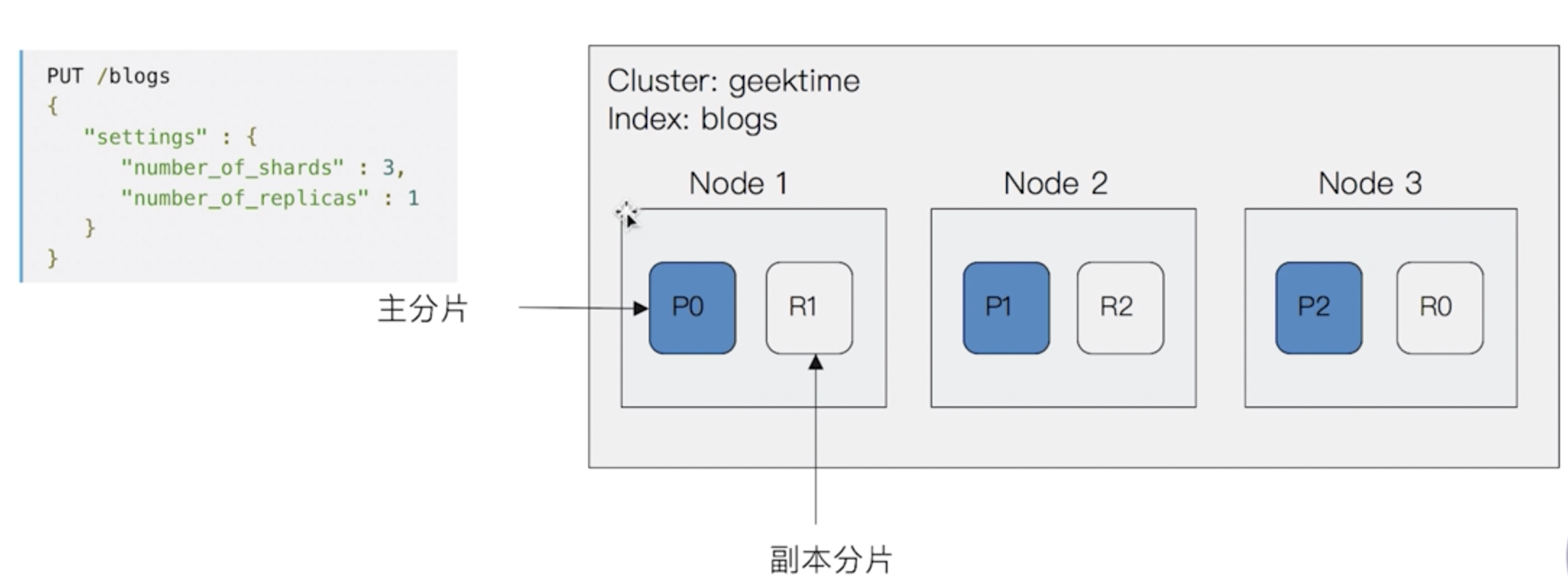
集群 Cluster
- 一群节点的集合
- 一个集群有多个节点,每个节点有多个分片
- 集群健康状况
- Green - 主副分片全部正常分配
- Yellow - 主分片全部正常,有副分片未能正常分配
- Red - 有主分片未能分配
节点 Node
- ES的实例,本质上是一个JAVA进程
- 一台机器上建议只运行一个实例
- 节点角色
- 每个节点启动后,默认是一个Master eligible节点
- Master eligible节点可参选,成为Master节点(默认是第一个节点启动)
- 每个节点保存了集群的状态,只有Master节点可以修改集群状态信息
- Data Node - 负责保存分片数据,数据拓展时新增Data Node
- Coordinating Node - 负责接收Client的请求,将请求分发并汇总结果,每个节点都默认起到了该职责
- Hot Node - 磁盘吞吐量很高的节点
- Warm Node - 存旧数据,机器旧的节点
- Machine Learning Node - 负责跑机器学习的Job,用来做异常检测
分片 Shard
创建索引index时指定,一个分片是一个Lucene的实例
- 主分片,Primary Shard
- 用于解决数据水平拓展的问题,可以将数据分布到集群内的所有节点之上
- 一个分片是一个运行的Lucene实例
- 主分片数在索引创建时指定,不可后续修改
- 副分片,Replica Shard
- 用于解决数据高可用的问题
- 副本分片数,可动态调整,增加副本数可变相增加性能
CRUD操作
create
- PUT index/_create/id - 指定Id
-
read
-
update
POST index/_update/id - 文档必须已经存在,只对相应字段做增量修改
index
PUT index/type/id - 指定id文档不存在就创建,否则删除旧文档,创建新文档,版本信息+1
delete
-
批量操作
Bulk API
- mget
- msearch
倒排索引
正排索引 - 目录
-
倒排索引 - 索引页
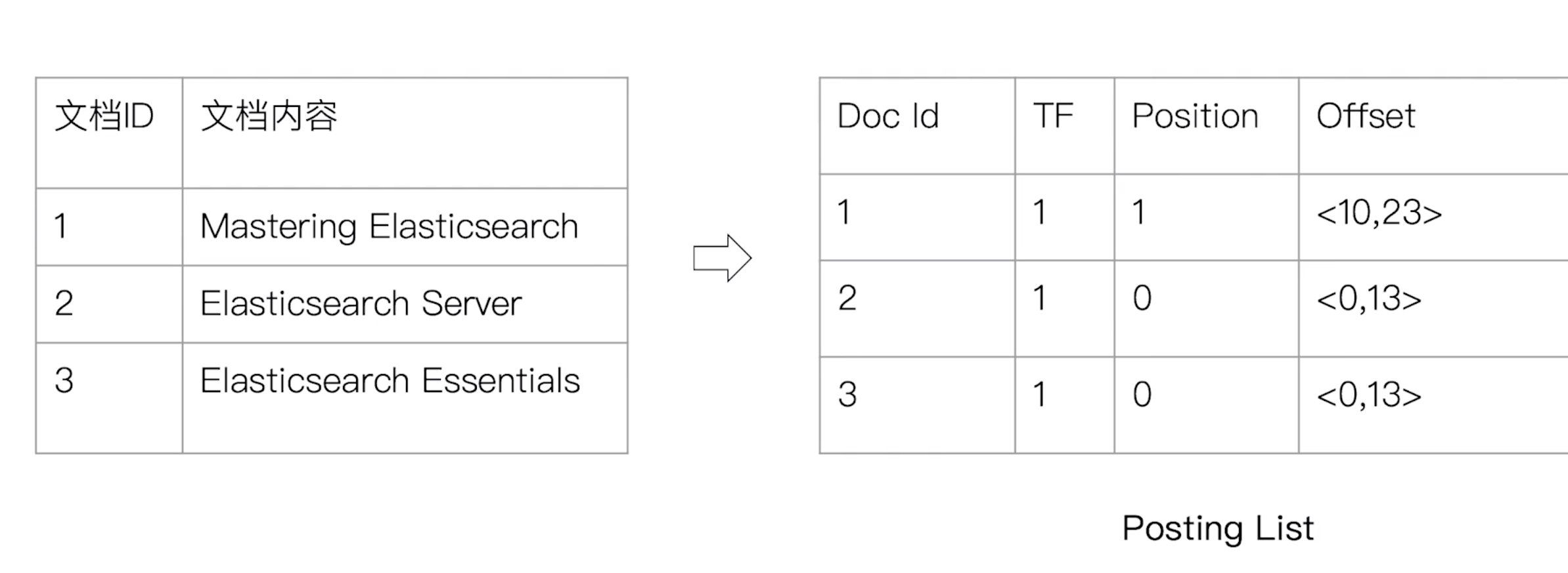
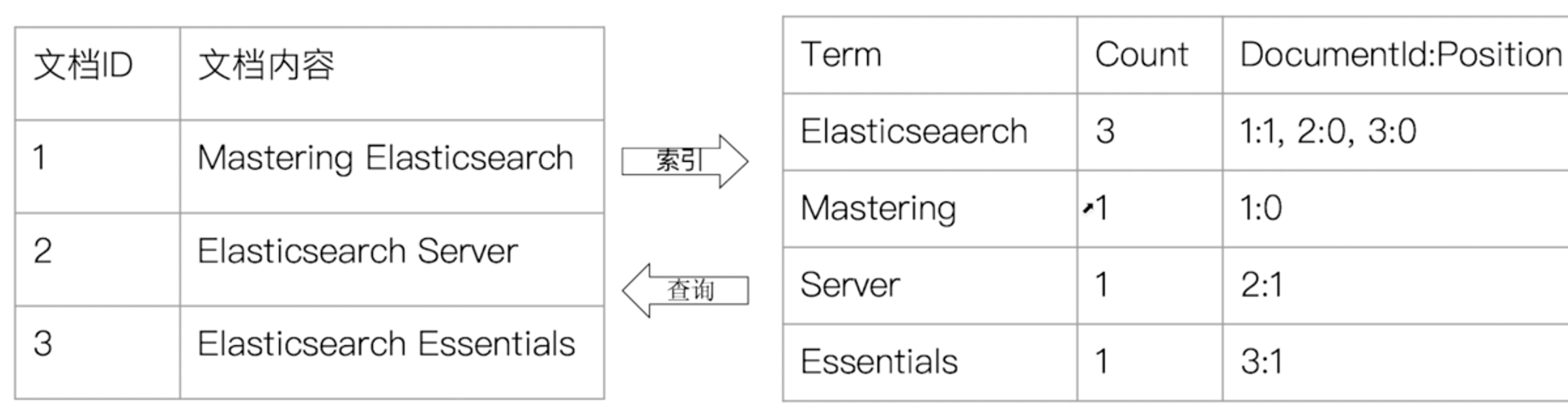
概念:单词 -> 文档id
- 组成
- 单词词典 - Term Dictionary
- 记录所有文档的单词,记录单词到倒排列表的关联关系
- 较大,通过B+树或哈希拉链法实现,满足高性能的插入和查询
- 倒排列表 - Posting List
- 记录了单词对应的文档的结合
- 由倒排索引项(Posting)组成
- 文档ID,词频(TF),位置(Position),偏移(Offset)
- 单词词典 - Term Dictionary
倒排索引的实现
分词 - Analysis
- Analysis - 文本分析,把全文本转换一系列单词(term/token)的过程
- Analysis是通过Analyzer来实现的
分词器 - Analyzer
- 组成
- Character Filters - 针对原始文本处理,例如去除html
- HTML strip
- Mapping - 字符串替换
- Pattern replace
- Tokenizer - 按照规则切分为单词,有内置的分词器,也有插件形式引入的
- standard - 默认,按词切分,转换小写
- simple- 按照非字母切分,非字母的都去除,转小写
- whitespace - 按空格切分
- stop - simple + stop filter(去除the, a, is等)
- keyword - 不需要分词时使用
- pattern - 正则表达式分词
- [language] - 指定不同语言
- icu
- 安装plugin - analysis-icu
- Token Filters - 将切分的单词进行二次加工、小写、删除stopwords,增加同义词
- Lowercase
- stop
- synonym
- Character Filters - 针对原始文本处理,例如去除html
Mapping
概念
- 类似数据库中schema的定义,定义索引中字段的名称、数据类型、倒排索引的相关配置
- mapping会把json文档映射成Lucene所需要的扁平格式
-
数据类型
简单类型
- Text / Keyword
- Date
- Integer / Floating
- Boolean
- IPV4 & IPV6
- 复杂类型
- 对象类型
- 嵌套类型
特殊类型
写入文档时,若索引不存在,则自动创建索引,但是不一定对
- dynamic在创建时可设置
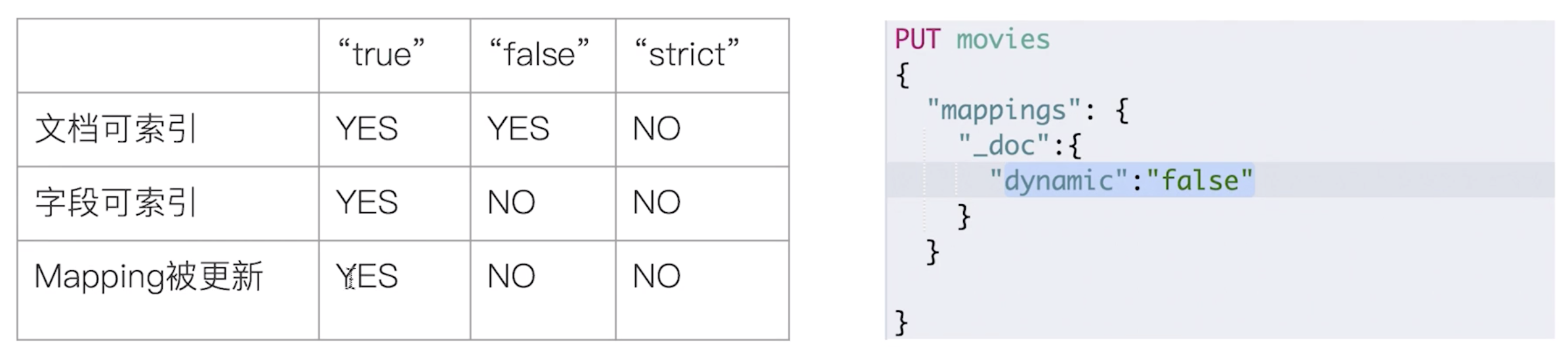
- strict时数据写入直接报错
多字段类型
- keyword不做分词,比如”Apple Store”
- text会被分词
Setting
setting中自定义分词器
PUT my_index{settings: {ayalysis: {analyzer: {my_custom_analyzer: {type: "custom",char_filter: [],tokenizer: "",filter: [],}}}

若有收获,就点个赞吧
0 人点赞
