Mysql允许创建多个数据库
使用SHOW databases命令可以查看有
使用CREATE DATABASE <databaseName>命令可以创建数据库
使用USE <databaseName>命令进入到数据库里。
使用DROP DATABASE <databaseName>删除数据库
基本查询语法
MySQL使用关键字SELECT来进行查询,SELECT语句的基本语法格式如下。
- SELECT 查询内容——查询所有字段 SELECT FROM 表名,通配符表示所有字段。
- FROM 表名——指定是从哪张表中查询。
- WHERE 表达式——在MySQL的表查询时,往往并不是需要将所有内容全部查出,而是根据实际需求,查询所需数据
- GROUP BY 字段名——分组进行查询,GROUP BY 把符合条件的同一类分在一组, 一般GROUP BY是和聚合函数配合使用的,如按男生分组查询、按女生分组查询。
- _HAVING 表达式——_HAVING关键字都用于设置条件表达式对查询结果进行过滤,区别是HAVING后面可以跟聚合函数,而WHERE不能,通常HAVING关键字都与GROUP BY一起使用,表示对分组后的数据进行过滤。
- ORDEY BY 字段名——按某个字段进行排序,如淘宝宝贝可以按销量排序、按好评数排序、按价格排序等。
- LIMIT 记录数——查询的条数,可以限制每次查询多少条数据,进行分页查询。
注释:
constraint 外键代号foreign key (表内字段号) references 主表名(关联字段名) on delete cascade
- 查看数据表结构:desc
命令行:desc **tb_name**; ps:常用于验证建表结果
强大的表操作:
MySQL表操作是使用频率最高的操作。用户可以创建数据库表,查看数据库表,向数据库表里插入数据、更新数据、删除数据等,同时可以修改表结构、复制表、使用临时表。
在MySQL里,插入使用INSERT关键字、查询使用SELECT关键字、修改使用UPDATE关键字、删除使用DELETE关键字。
SQL语句格式:
在数据库上执行的大部分工作都由 SQL 语句完成。SQL 对大小写不敏感。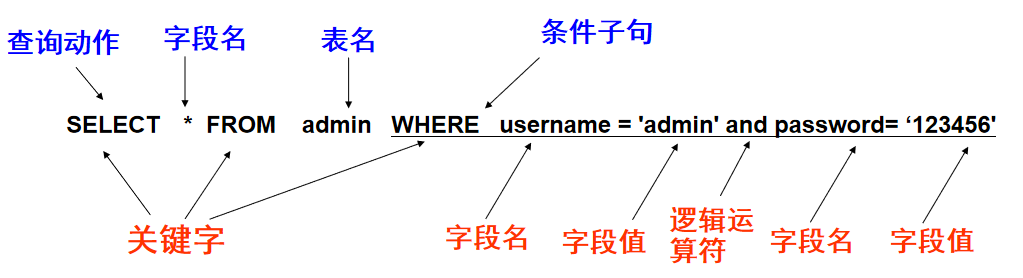
插入(insert)
将一条数据插入到数据库里,可以使用如下命令。INSERT INTO 表名(字段名,字段名) VALUES(值,值);
ps:(值要一 一对应)
或者可以不指明表的字段,但是值按字段的顺序插入:INSERT INTO 表名 VALUES(值,值);( 默认按顺序)
查询(select)
查询数据,可以使用如下命令。
SELECT FROM 表名;(代表所有)
或者查询指定字段,可以使用如下命令。
SELECT id FROM 表名;
使用WHERE条件语句按条件查询,把某一列或者几列作为查询条件,可以使用如下命令。SELECT * FROM 表名 WHERE id=10;SELECT * FROM 表名 WHERE id=10 and name='小明';
修改记录(updata)(alter)
在MySQL里修改使用关键字UPDATE,命令如下所示。UPDATE 表名 SET 字段=值,字段=值 WHERE 条件
UPDATE user SET name=’小明’,sex=’男’ WHERE id = 4;
也可以使用ALTER关键字ALTER TABLE 表名 <新列名><数据类型>
修改数据表类型:alter table <tb_name> modify <column_name> definition
修改数据库默认字符集(为utf8):alter database <db_name> default character set <utf8>;
增加数据列:alter table <tb_name> add <column_name> definition first [after <column_name>];
ps:first为最左添加,after则为在某一列之后添加,前后两个column_name不同需要注意。
删除主键约束:alter table <tb_name> drop primary key;
删除记录
在MySQL中删除列和数据可以使用DELETE关键字,命令如下所示。DELETE FROM 表名 WHERE 条件
e.g.DELETE FROM user WHERE id=4;
删除所有行:truncate table **<tb_name>**;
ps:delete 不带where子句是删除表内所有数据行。 truncate 操作后,自增字段重新计算,delete则不会。
删除表可用DROP关键字,命令如下:DROP TABLE **<tb_name>** ;
对查询结果排序(ORDEY BY)
在MySQL数据库中,使用ORDEY BY进行排序,使用关键字ASC进行升序排序(ascend),使用关键字DESC进行降序排序(descend),同时可以按一个字段或者多个字段进行排序。如果按多个字段进行排序,先进行第一个字段的排序,然后在结果集里面再进行第二个字段的排序。
(1)ORDEY BY [column] ASC:按某一字段进行升序排序,ASC可以省略不写。SELECT * FROM user ORDEY BY id ASC;或SELECT * FROM user ORDEY BY id;
(2)ORDEY BY column DESC:按某一字段进行降序排序,DESC不可以省略不写。SELECT * FROM user ORDEY BY id DESC;
(3)ORDEY BY column1,column2 DESC:按多个字段进行降序排序。SELECT * FROM user ORDEY BY sex,age DESC;
对查询结果分组(GROUP BY)
GROUP BY对查询结果分组是将查询结果按照1个或多个字段进行分组,字段值相同的为一组,GROUP BY可以用于单个字段和多个字段。SELECT * FROM user GROUP BY sex;
group_concat(字段名)可以作为一个输出字段来使用,表示分组之后,根据分组结果,使用group_concat( )来放置每一组的某字段的值的集合。SELECT sex,group_concat(name) FROM user GROUP BY sex;
设置分组条件(HAVING)
HAVING 是用来设置分组条件的条件表达式,用来在分组查询后指定一些条件来输出查询结果,WHERE语句在聚合前先筛选记录,也就是说作用在GROUP BY和HAVING子句前,而 HAVING子句在聚合后对组记录进行筛选,HAVING只能用于GROUP BY。SELECT sex,group_concat (name) FROM user GROUP BY sex HAVING count(sex)>2
限制查询数量(LIMIT)
LIMIT用于限制查询的数量,常用于分页语句。LIMIT 子句可以被用于强制SELECT语句返回指定的记录数。LIMIT 接受一个或两个数字参数,参数必须是一个整数常量。
(1)如果只给定一个参数,则它表示返回最大的记录行数目。
#检索前6行记录SELECT * FROM user LIMIT 6;
(2)如果给定两个参数,则第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目,初始记录行的偏移量是0(而不是1)。
#从第3条数据开始,检索出5条数据SELECT * FROM user LIMIT 2,5;
条件查询过滤
条件查询过滤关键字为AND、OR、IN、NOT IN、IS NULL、IS NOT NULL、BETWEEN AND。按关键字可以进行条件查询过滤。
(1)AND(与)。用AND进行查询的时候,查询出来的数据要求条件都得满足。SELECT * FROM user WHERE age = 20 and name='kevin';
(2)OR(或)。用OR进行查询的时候,查询出来的数据只要求满足任意一个条件就可以查询出来。SELECT * FROM user WHERE age = 20 or name='kevin';
(3)IN(在范围内)。用IN进行查询的时候,查询出来的数据在这个范围内。SELECT * FROM user WHERE id in (3,5,7);
(4)NOT IN(不在范围内)。用NOT IN进行查询的时候,查询出来的数据不在这个范围内。SELECT * FROM user WHERE id not in(3,5,7);
(5)IS(为空)。用IS NULL进行查询的时候,用来查询某字段为空时用is null,而不能使用”=null”,因为MySQL中的null不等于任何其他值,也不等于另外一个null,优化器会把”=null”的查询过滤掉而不返回任何数据;查询某字段为非空时使用is not null。SELECT * FROM user WHERE name is null;SELECT * FROM user WHERE name is not null;
(6)BETWEEN AND(在……区间):用BETWEEN AND进行查询的时候,查询出来的数据在这个区间。SELECT * FROM user WHERE age between 10 and 20;
select * from orders where orderno BETWEEN 22456 and 24562; #闭区间
select * from orders where orderno >=22456 and orderno <=24562;
(×) select from orders where 22456<=orderno<=24562;
数据查询—聚集函数
Count() 计算元组个数,包括null
Count([distinct|all]<表达式>) 计算元组个数,包括null
Sum([distinct|all]<表达式>) 计算表达式和,不包括null
Avg([distinct|all]<表达式>) 计算机表达式平均值,不包括null
Max([distinct|all]<表达式>) 计算最大值,不包括null
Min([distinct|all]<表达式>) 计算最小值,不包括null
字符匹配——模糊查询过滤
模糊查询过滤使用关键字LIKE进行查询。
通配符:% 百分号代表任意长度的字符串 下划线代表任意单个字符
(1)LIKE ‘张%’:使用LIKE查询该字段以“张”开头的数据。SELECT * FROM user where name like '张%';
(2)LIKE ‘ %明’:使用LIKE查询该字段以“明”结尾的数据。SELECT * FROM user where name like '%明';
(3)LIKE ‘ %明%’:使用LIKE查询该字段包含“明”的数据。SELECT * FROM user where name like '%明%';
(3)LIKE ‘ 明%’:使用LIKE查询该字段第二个字为“明”的数据。SELECT * FROM user where name like _'明%';
当原本的被查询字符中含有% 或 ,就需要使用Escape‘<换码字符>’来对通配符进行转义
`SELECT * FROM user where name like ‘DB\%i__’escape’\’;(代表\为转移字符,后面的字符全为普通字符)<br />**字段控制查询过滤 **<br />字段控制查询过滤可以使用DISTINCT去除重复过滤,使用AS设置别名。<br />(1)DISTINCT:去除重复的列值。<br />SELECT distinct age FROM user;<br />(2)AS:可以设置列的别名,也可以省略AS来设置关键字。<br />SELECT name as 姓名 FROM user;<br />或者<br />SELECT name 姓名 FROM user;<br />select distinct name (as) 姓名 FROM user;<br />**正则表达式查询过滤 **<br />正则表达式用来匹配文本中的特殊字符串或字符集合。将正则表达式与一个文本串进行比较,查询出满足正则表达式的数据。所有种类的程序设计语言、文本编辑器、操作系统等都支持正则表达式;MySQL用WHERE子句对正则表达式提供了初步的支持,使用REGEXP关键字指定正则表达式的字符匹配模式,允许指定用正则表达式过滤SELECT检索出的数据。<br />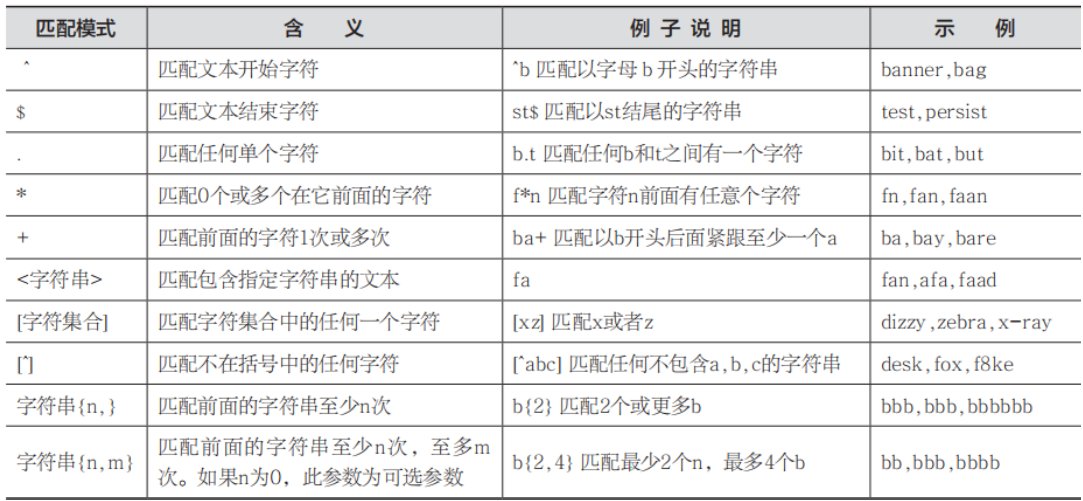<br />SELECT name FROM person_tbl WHERE name REGEXP ‘^st’; <br />SELECT name FROM person_tbl WHERE name REGEXP ‘ok$’<br />SELECT name FROM person_tbl WHERE name REGEXP ‘mar’;<br />SELECT name FROM person_tbl WHERE name REGEXP ‘^st|ok$’;<br />**联合查询 **<br />联合查询是将多次查询结果合并起来进行拼接,其字段不会增加,要求两次查询的列数必须一致,列的类型可以不一样<br />多次SQL语句取出的列名可以不一致,此时以第一个SQL语句的列名为准;<br />使用关键字UNION进行联合查询,会去掉重复的行,<br />使用关键字UNION all进行联合查询,不会去掉重复的行;<br />ORDEY BY不能直接使用,需要对查询语句使用括号才行;<br />要ORDER BY生效,就必须搭配LIMIT,LIMIT使用限定的最大数即可,推荐放到所有子句之后,即对最终合并的结果来排序或筛选。<br />SELECT column_name FROM table1<br />UNION (all)<br />SELECT column_name FROM table2 <br />联合查询经常用于查询同一个表,但是需求不同, 如查询学生信息、男生身高升序、女生身高降序;进行多表查询,多个表的结构是完全一样的,保存的数据(结构)也是一样的。<br />**UNION**<br />UNION 命令只会选取不同的值。<br />SELECT E_Name FROM Employees_China UNION ALL SELECT E_Name FROM Employees_USA <br />导出某个数据库:<br />mysqldump -u root -p dbName > sqlFilePath<br />导出多个数据库:<br />mysqldump -u root -p –add-drop-database –databases dbName1 dbName2… > sqlFilePath -add-drop-database : 该选项表示在创建数据库的时候先执行删除数据库操作 <br />–database : 该选项后面跟着要导出的多个数据库,以空格分隔<br />导出某个数据库的某个表:<br />mysqldump -u root -p dbName tableName > sqlFilePath<br />只导出数据库结构,不带数据:<br />mysqldump -u root -p -d dbName > sqlFilePath`
-d : 只备份结构,不备份数据。也可以使用”–no-data”代替”-d”,效果一样。

若有收获,就点个赞吧
0 人点赞
