分析

vmstat
vmstat 几秒看一次 一共看几次
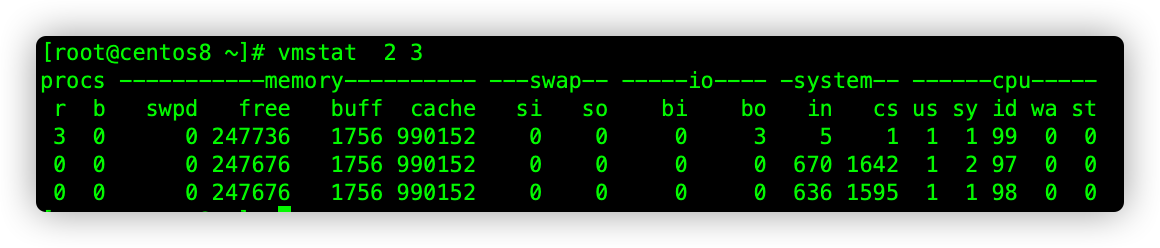
| 进程 procs |
r | 等待CPU处理的进程数 | 值超过cpu个数,出现CPU瓶颈。 |
|---|---|---|---|
| b | 等待磁盘读写而阻塞的进程数(IO) | ||
| 内存 | swpd | 正在使用的虚拟内存大小,单位k | |
| free | 空闲内存大小 | ||
| buff | 已用的buff大小,对块设备的读写进行缓冲 | ||
| cache | 已用的cache大小,文件系统的cache | ||
| swap | si | 每秒从交换区写入内存的大小,单位kb/s | |
| so | 每秒从内存写到交换区的大小 | ||
| IO | bi | 每秒读取的块数(读磁盘),单位block | 块设备的大小主要看Linux文件系统的配置是多少,一般为1024bytes |
| bo | 每秒写入的块数(写磁盘) | ||
| system | in | 每秒中断数,包括时钟中断 | 值越大,说明内核消耗的cpu时间会越多 |
| cs | 每秒上下文切换数 | ||
| CPU | us | 用户进程执行消耗CPU时间 | 长期超过50%,考虑优化程序算法 |
| sy | 系统进程消耗的CPU时间 | us+sy的参考值为80%,如果大于,说明CPU不足。 | |
| ld | 空闲时间(包括IO等待时间) | 一般来说 us+sy+id=100 | |
| wa | 等待IO时间 | wa过高时,说明io等待比较严重,可能为磁盘大量随机访问造成的,或者是磁盘的带宽出现瓶颈。 | |
| st | 衡量虚拟机CPU的指标,是指分配给本虚拟机的时间片被同一宿主机别的虚拟机使用。 | 一般st值高的话,说明宿主机的性能到了瓶颈。 |
mpstat
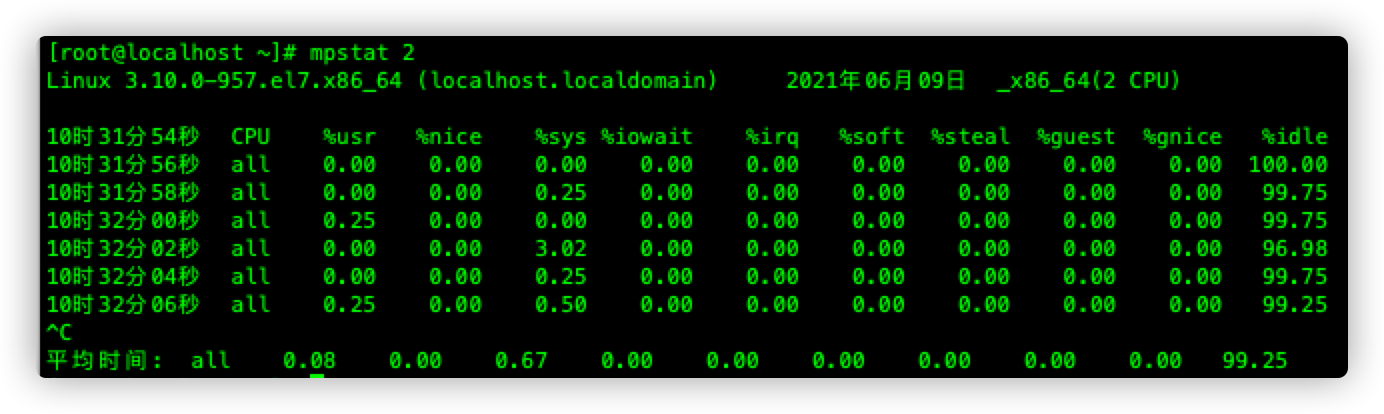
| %usr | 用户进程消耗的CPU百分比 |
|---|---|
| %nice | nice值为负的进程的CPU占用百分比 |
| %sys | 内核进程消耗的CPU百分比 |
| %iowait | IO等待时间 |
| %irq | 硬中断时间(由硬件本身引发的,用来通知系统硬件状态的变化) |
| %soft | 软中断时间 |
| %steal | 没理解 |
| %guest | CPU运行虚拟化的占比 |
| %gnice | CPU运行niced guest所花费的时间百分比 |
| %idle | CPU除去等待磁盘IO外的所有空闲时间 |
CPU架构
SMP(一致存储访问结构,也叫非对称多处理架构)
使众多CPU在单一系统进行运转。简述:多个CPU共用同一个内存系统。
缺点:由于每个CPU连接的是同一个存储总线,所以,加CPU不一定能达到 1+1 = 2的效果
NUMA(非同一内存访问结构)
多处理器多内存的架构,内存访问时间取决于处理器的内存位置。处理器访问自己的本地存储器的速度比非本地存储器快。简述:每个CPU都有自己的内存系统,架构上像是多台服务器捆版在一起。
缺点:对于跨CPU的运算非常慢,所以在使用NUMA架构的时候尽量不要进行跨CPU的运算。
MPP(对称多处理架构)
在一台计算机上汇集了一组处理器,各个处理器之间共享内存子系统和总线结构。
对CPU的要求很高:
1.CPU必须内置APIC单元(高级可编程中断控制器,是Intel多处理规范的核心)
2.相同的产品型号
3.完全相同的运行频率
4.尽量选择相同生产批次的CPU,避免不同的生产批次CPU发生一颗CPU负载过高,另一颗负载很低的问题。
调优办法
横向扩展
增加服务器数量,将服务器架构集群化。
纵向扩展
从CPU架构入手,一般使用NUMA
微调
进程优先级
通过设置进程的nice值来调整CPU的资源分配,nice(-20~19)越小,进程的权重越大。
指令
renice -20 pid
example 将http的进程一键设置为-20
ps -ef|grep httpd|grep -v grep|awk ‘{print $2}’|xargs renice -20
CPU亲和性
为进程分配固定的CPU
taskset -c cpu某一个核(双核的话就是0,1) 进程启动命令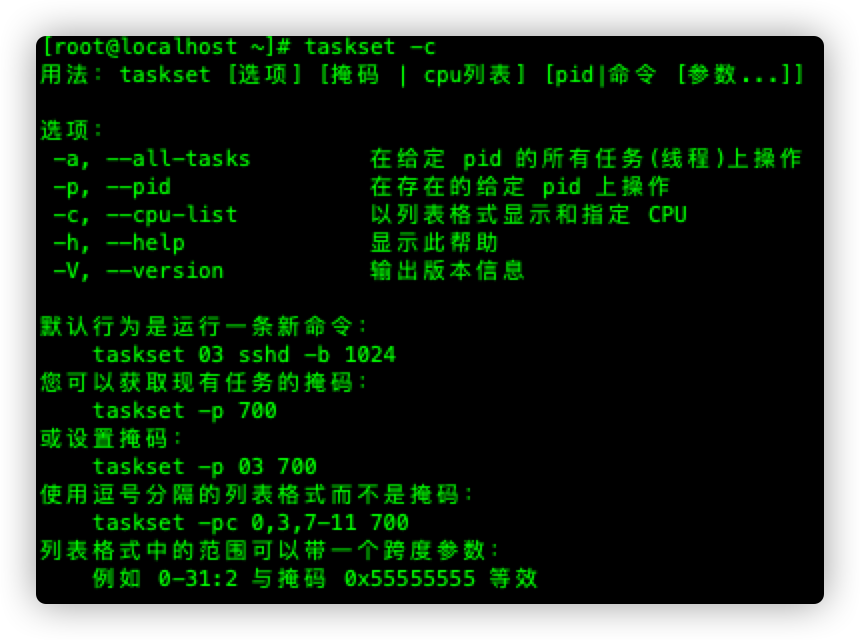
example taskset -c 0 /etc/httpd
云计算
将传统的物理机房,改变为云计算的方式,能够通过线上的方式增加性能,比如分布式,集群等等。
云计算,解决了传统模式下需要横向扩展与纵向扩展的难题,提高了服务器性能升级的效率。
定义中断的亲和性
将中断集中在CPU的某一个核上,避免由于中断影响进程的运行。
查看中断分布情况 cat /proc/interrupts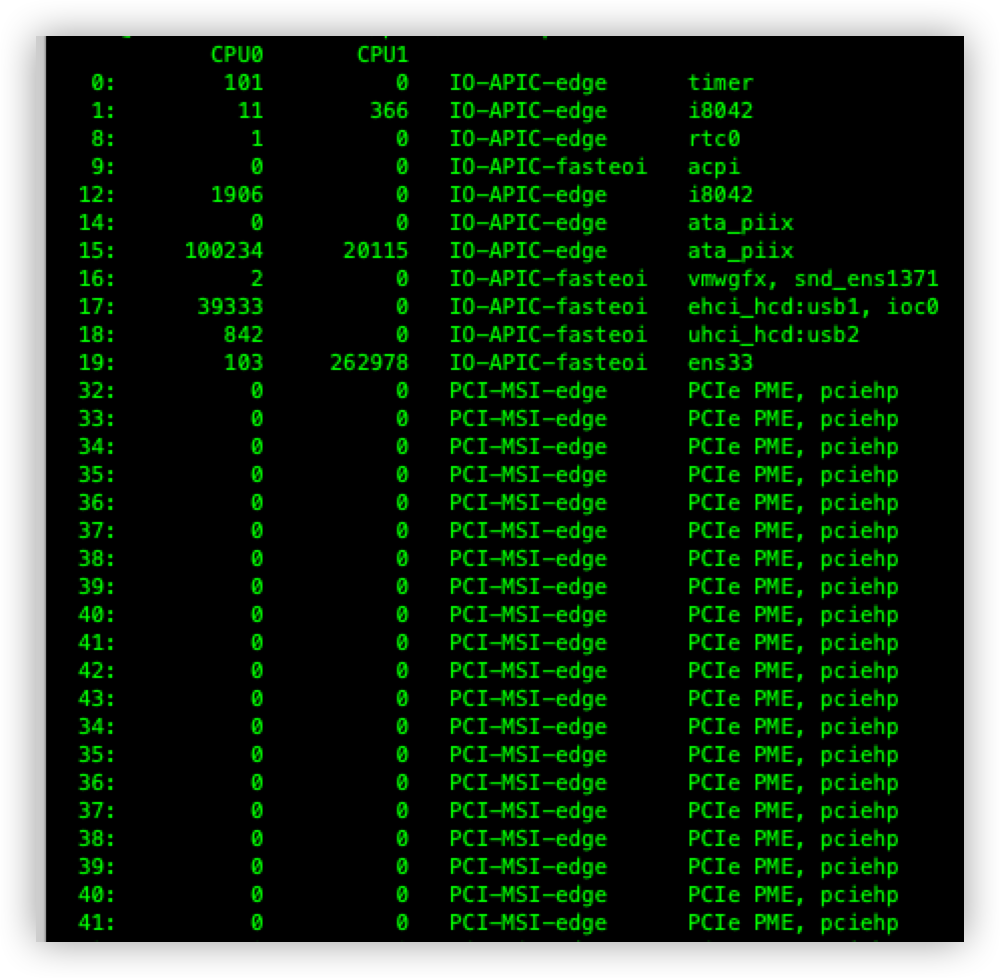
指令 echo 核id /proc/irq/irq的id/smp_affinity
example : echo 2 /proc/irq/19/smp_affinity
OSPF+LVS
一种通过虚拟路由实现的LVS高可用集群

若有收获,就点个赞吧
0 人点赞
