ABSTRACT 摘要
This paper shows how to construct knowledge graphs (KGs) from pre-trained language models (e.g., BERT, GPT-2/3), without human supervision.
本文展示了如何从预先训练的语言模型中构建知识图谱 (KGs) (例如,BERT,GPT-2/3),无需人工监督。
Popular KGs (e.g, Wikidata, NELL) are built in either a supervised or semi-supervised manner, requiring humans to create knowledge.
流行的KGs (例如,Wikidata,NELL) 是以监督或半监督的方式构建的,要求人类创造知识。
Recent deep language models automatically acquire knowledge from large-scale corpora via pre-training.
最近的深度语言模型通过预训练自动从大型语料库中获取知识。
The stored knowledge has enabled the language models to improve downstream NLP tasks, e.g., answering questions, and writing code and articles.
存储的知识使语言模型能够改进下游NLP任务,例如回答问题、编写代码和文章。
In this paper, we propose an unsupervised method to cast the knowledge contained within language models into KGs.
在本文中,我们提出了一种无监督的方法,将语言模型中包含的知识转换为KGs。
We show that KGs are constructed with a single forward pass of the pretrained language models (without fine-tuning) over the corpora.
我们表明,KGs是用预先训练的语言模型的单个前向通过 (没有微调) 构建的。
We demonstrate the quality of the constructed KGs by comparing to two KGs (Wikidata, TACKBP) created by humans.
我们通过与人类创造的两个知识图谱 (维基数据,塔克布) 进行比较,证明了所构建的知识图谱的质量。
Our KGs also provide open factual knowledge that is new in the existing KGs.
我们的KGs还提供现有KGs中新的公开事实知识。
Our code and KGs will be made publicly available.
我们的代码和知识图谱将公开提供。
1 INTRODUCTION 介绍
Knowledge graphs (KGs) are an important resource for both humans and machines.
知识图 (KGs) 是人类和机器的重要资源。
Factual knowledgein KGs is injected into AI applications to imitate important skills possessed by humans, e.g., reasoning and understanding.
KGs的事实知识被注入到人工智能应用中,以模仿人类拥有的重要技能,例如推理和理解。
KG construction is mainly supervised, requiring humans to handwrite every fact, such as Freebase (Bollacker et al., 2008) and Wikidata.
KG结构主要受到监督,要求人类手写每一个事实,如Freebase (Bollacker等人,2008) 和Wikidata。
KGs can also be constructed in a semi-supervised way, in which a semi-automatic extractor is used to obtain the facts from web corpora (e.g., NELL (Carlson et al., 2010) and Knowledge Vault (Dong et al., 2014)).
KGs也可以以半监督的方式构建,其中半自动提取器用于从web语料库中获取事实 (例如g.,内尔 (卡尔森等人,2010) 和知识库 (董等人,2014))。
Humans however still need to interact with the extractor to improve the quality of the discovered facts.
然而,人类仍然需要与提取器相互作用,以提高发现事实的质量。
Therefore, human supervision, which is often expensive, is required in constructing KGs.
因此,建造KGs需要人工监督,这通常是昂贵的。
Recent progress in language models (LMs), such as BERT (Devlin et al., 2018) and GPT-2/3 (Radfordet al., 2019; Brown et al., 2020), has led to superior results even outperforming humans in a wide range of tasks, e.g., sentence classification (Wang et al., 2018), question answering (Brown et al., 2020).
进展语言模型 (LMs),如BERT (德夫林等人,2018) 和GPT-2/3 (Radford等人,2019; Brown等人,2020),已经导致了甚至在广泛的任务中超过人类的卓越的结果,例如,句子分类 (王等人,2018),问题回答 (Brown等人,2020)。
Pre-trained LMs are also capable to write poetry, music, and code, while such tasks often require we human to spend a significant amount of time in learning the relevant knowledge to work well.
预先训练的语言模型也能够写诗、音乐和代码,而这样的任务通常需要我们人类花费大量的时间来学习相关知识才能很好地工作。
In fact, these pre-trained LMs automatically acquire factual knowledge from large-scale corpora (e.g., BookCorpus (Zhu et al., 2015), Common Crawl (Brown et al., 2020)) via pre-training.
事实上,这些预先训练的LMs自动从大规模语料库中获取事实知识 (例如g.,图书语料库 (朱等人,2015),普通爬行 (布朗等人,2020)) 通过预训练。
The learned knowledge in pre-trained LMs is the key to the current success.
在预先训练的语言模型中学到的知识是当前成功的关键。
We therefore consider the following question: instead of using the manually created knowledge, can we use the knowledge stored in pre-trained LMs to construct KGs?
因此,我们考虑以下问题: 我们是否可以使用预先训练的LMs中存储的知识来构建KGs,而不是使用手动创建的知识?
In this paper, we design an unsupervised approach called MAMA that successfully recovers thefactual knowledge stored in LMs to build KGs from scratch.
在本文中,我们设计了一种称为MAMA的无监督方法,该方法成功地恢复了LMs中存储的事实知识,从而从头开始构建KGs。
MAMA constructs a KG with a single forward pass of a pre-trained LM (without fine-tuning) over a textual corpus.
MAMA在文本语料库上构造了一个带有预训练LM (无微调) 的单个前向通过的KG。
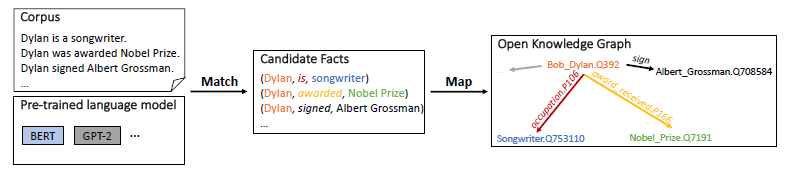
Figure 1: Overview of the proposed approach MAMA. MAMA constructs an open knowledge graph (KG)with a single forward pass of the pre-trained language model (LM) (without fine-tuning) over the corpus. Given the input: a textual corpus containing passages and sentences, e.g., English Wikipedia, and a pre-trained LM, e.g., BERT, GPT-2/3, MAMA (1) generates a set of candidate facts via matching the knowledge in the pretrained LM with facts in the textual corpus, e.g., a candidate fact (Dylan, is, songwriter) from the sentence “Dylan is a songwriter.”, and (2) produces an open KG by mapping the matched candidate facts to both an existing KG schema, e.g., (Bob Dylan.Q392, occupation.P106, Songwriter.Q753110) in Wikidata schema, and an open schema, e.g., (Bob Dylan.Q392, sign, Albert Grossman.Q708584).
图1: 建议方法的概述MAMA。MAMA在语料库上构建了一个开放知识图 (KG),其中包含预先训练的语言模型 (LM) 的单个前向通过 (无需微调)。给定输入: 包含段落和句子的文本语料库,例如英语维基百科,以及预先训练的LM,例如BERT,GPT-2/3,MAMA (1) 通过将预先训练的LM中的知识与文本语料库中的事实 (例如,候选事实) 相匹配来生成一组候选事实(迪伦,是,作曲家) 句子 “迪伦是作曲家。” 和 (2) 通过将匹配的候选事实映射到现有的KG模式,例如,(鲍勃·迪伦。q392,职业。第106页,歌曲作者。q753110) 和开放模式,例如,(鲍勃·迪伦。Q392,标志艾伯特·格罗斯曼。Q708584)。。
As illustrated in Figure 1, MAMA has two stages: Match and Map.
如图1所示,MAMA有两个阶段: Match和Map。
Match stage generates a set of candidate facts by matching the facts in the textual corpus with the knowledge in the pre-trained LM.
匹配阶段通过将文本语料库中的事实与预先训练的LM中的知识匹配来生成一组候选事实。
General or world knowledge from large-scale corpora is embedded in the LM, thus candidate facts in the target corpus are often covered by the knowledge in the LM.
来自大型语料库的一般或世界知识嵌入到LM中,因此目标语料库中的候选事实通常被LM中的知识覆盖。
The candidate facts are matched through an efficient beam search in the attention weight matrices of the pre-trained LM without fine-tuning.
候选事实通过预先训练的LM的注意力权重矩阵中的有效光束搜索进行匹配,而无需微调。
Map stage produces an open KG via mapping the matched candidate facts from Match stage to both fixed KG schema and open schema.
映射阶段通过将匹配的候选事实从匹配阶段映射到固定的KG模式和开放模式来生成开放的KG。
If the schema of candidate facts exists in the KG schema, we map the candidate facts directly to the fixed KG schema.
如果KG模式中存在候选事实的模式,我们将候选事实直接映射到固定的KG模式。
Otherwise, we reserve the unmapped candidate facts in the open schema.
否则,我们将未映射的候选事实保留在开放模式中。
This results in a new type of KG, open KG, with a mixture of mapped facts in fixed KG schema and unmapped facts in the open schema.
这导致了一种新类型的KG,即open KG,混合了固定KG模式中的映射事实和开放模式中的未映射事实。
Our contributions are as follows:
我们的贡献如下:
- We show how to construct KGs from pre-trained LMs. The KGs are constructed with a single forward pass of the pre-trained LMs without fine-tuning over the textual corpora. This helps researchers explicitly understand what the language models learn, bridging the deep LM and KG communities through enhanced model transparency.
我们展示了如何从预先训练的LMs中构建KGs。KG是用预训练的LMs的单个前向通过构建的,没有对文本语料库进行微调。这有助于研究人员明确理解语言模型学到了什么,通过增强的模型透明度桥接深层LM和KG社区。
- We propose an unsupervised two-stage approach, MAMA, to first match the candidate facts in the corpora with the knowledge stored in LMs, then map the matched candidate facts to both fixed and open schema to produce a KG.
我们提出了一种无监督的两阶段方法,MAMA,首先将语料库中的候选事实与存储在LMs中的知识相匹配,然后将匹配的候选事实映射到固定模式和开放模式,以产生KG。
- We generate a new type of KG, namely open KG, consists of mapped facts in the fixed KG schema of existing KGs (Wikidata and TAC KBP) annotated by humans; and unmapped facts in the open schema that are new in the reference KG schema. The reach of this result is broad and has downstream utility for knowledge graph construction, deep neural network interpretation, and information extraction.
我们生成了一种新类型的KG,即open KG,由人类注释的现有KGs (Wikidata和TAC KBP) 的固定KG模式中的映射事实组成; 以及开放schema中引用KG schema中新的未映射事实。该结果的范围很广,在知识图构建、深度神经网络解释和信息提取方面具有下游效用。
2 MAMA
We introduce an unsupervised end-to-end approach Match and Map (MAMA) as illustrated in Figure1 to construct open knowledge graphs (KGs) from language models (LMs).
我们引入了一种无监督的端到端方法匹配和映射 (MAMA),如图所示1从语言模型 (LMs) 构建开放知识图 (KGs)。
MAMA constructs the KGs with a single forward pass of the pre-trained LMs (without fine-tuning) over the corpora.
MAMA通过预先训练的LMs (没有微调) 在语料库上的单个前进通道来构建KGs。
The two stages of MAMA are:
MAMA的两个阶段是:
Match generates a set of candidate facts from a textual corpus.
Match从文本语料库生成一组候选事实。
LMs contain global or world knowledge learned from large-scale corpora, which often does not perfectly match the knowledge in the target corpus.
LMs包含从大型语料库中学到的全球或世界知识,这些知识通常与目标语料库中的知识不完全匹配。
The goal of this stage is to match the knowledge stored in pre-trained LMs with facts in the corpus.
此阶段的目标是将预先训练的LMs中存储的知识与语料库中的事实相匹配。
Each fact is represented as a triplet (head, relation, tail) 1, in short, (h; r; t), and passed to Map stage.
每个事实都表示为一个三元组 (头、关系、尾) 1,简而言之,(h; r; t),并传递到地图阶段。
Match procedure is detailed in Sec. 2.1.
匹配过程在第节中有详细说明。2.1.
Map produces an open KG using the matched candidate facts from Match stage.
Map使用匹配阶段的候选事实生成一个开放的KG。
The constructed open KG has two portions: (a) mapped candidate facts that are in a fixed KG schema, e.g., (Dylan, is, songwriter) is mapped to (Bob Dylan.Q392, occupation.P106, Songwriter.Q753110) according to Wikidata schema; and (b) unmapped candidate facts that are in an open schema, e.g., a candidate fact (Dylan, signed, Albert Grossman) is partially mapped to (Bob Dylan.Q392, sign, Albert Grossman.Q708584) in the open schema.
构建开放KG两部分: (a) 映射候选人事实固定KG架构,例如 (迪伦,,作曲家) 映射到 (鲍勃·迪伦。q392,职业。第106页,歌曲作者。q753110) 根据维基数据模式; 和 (b)映射候选人事实开放架构,例如候选人事实 (迪伦签署,艾伯特格罗斯曼) 部分映射到 (鲍勃·迪伦。q392,标志艾伯特·格罗斯曼。q708584) 打开架构。
This stage is described in Sec. 2.2.
此阶段在第节中进行了描述。2.2.

Figure 2: Illustration of Match stage. The upper part of (a) represents the general matching steps of generatingthe best matched candidate fact (Dylan, is, songwriter) from the sentence “Dylan is a songwriter.” The lower portion shows the corresponding step-by-step process. Given a head-tail pair (Dylan, songwriter), at each step, the search chooses one of the actions, i.e., START, YIELD, STOP to produce an intermediate candidate fact. The search starts by adding the head “Dylan” as an initial candidate (step 0). The matching degree of the candidate is initialized as 0. Next, a new candidate is yielded if the candidate has not reached the tail “songwriter”, by appending the next largest attended token (with the largest score from the attention matrix (b) of the sentence) to the end of the current candidate, and the corresponding matching degrees are increased by the associated attention scores (step 1 and step 2). Otherwise, the search stops, and the candidate fact with the best matching degree is returned for the head-tail pair (step 3). The attention matrix (b) is from the forward pass of the LM without fine-tuning over the sentence. “x” marks the tokens to prevent searching backward.
图2: 比赛阶段的插图。上部 (a) 表示通用匹配步骤生成最佳匹配候选人事实 (迪伦,,作曲家) 句子 “迪伦是作曲家。” 下部显示了相应的逐步过程。给定头尾对 (迪伦,歌曲作者),在每个步骤中,搜索都会选择其中一个动作,即开始、屈服、停止以产生中间候选事实。搜索从添加标题 “迪伦” 作为初始候选开始 (步骤0)。候选者的匹配度初始化为0。接下来,如果候选人没有到达尾巴 “歌曲作者”,则通过附加下一个最大参与令牌 (注意力矩阵中的最大分数 (b) 句子) 到当前候选人的结尾,并且相应的匹配程度通过相关的注意力分数增加 (步骤1和步骤2)。否则,搜索停止,并且对于头-尾对返回具有最佳匹配度的候选事实 (步骤3)。注意矩阵 (b) 来自LM的前向通过,没有对句子进行微调。“x” 标记令牌以防止向后搜索。
2.1 MATCH
We frame the matching procedure as a search problem. To obtain the best matched candidate facts of an input sentence, the candidates with the top matching degrees are returned from a search process. The matching degree is derived from the search in the attention weight matrices of the pre-trained LM, since the attention weight matrices are the container of the knowledge in the pre-trained LM. The attention weight matrices are simply from the forward pass of the LM without fifine-tuning over the sentence.
我们将匹配过程框架为一个搜索问题。为了获得输入句子的最佳匹配的候选事实,从搜索过程中返回具有最高匹配学位的候选人。匹配度是从预先训练的LM的注意力权重矩阵中的搜索中得到的,因为注意力权重矩阵是预先训练的LM矩阵中知识的容器。注意力权值矩阵只是从LM的向前传递,而不对句子进行微调。
2.1.1 BEAM SEARCH 波束搜索
We design a simple-yet-effective beam search to find the best matched candidate facts.
我们设计了一个简单而有效的波束搜索,以找到最匹配的候选事实。
For every
head-tail pair (h; t) in a sentence, the search maintains the k-best matched candidate facts of the pair.
对于句子中的每个头尾对 (h; t),搜索保持该对的k-最佳匹配候选事实。
Let’s first consider the search from left to right with beam size equals to 1.
让我们首先考虑从左到右的搜索,光束大小等于1。
An example search process is shown in Figure 2.
示例搜索过程如图2所示。
Given a head-tail pair (Dylan, songwriter), at each step, the search performs one of the following actions:
给定头尾对 (迪伦,歌曲作者),在每个步骤中,搜索都会执行以下操作之一:
START: the search from the head. The head h is added as an initial candidate into the beam. For
simplicity, we use START(h) to denote the action, which returns a candidate (h;. In Figure 2(a), at step 0, the head “Dylan” is added as (Dylan, into the beam. The matching degree is initialized to 0.
开始:
从头部进行搜索。头h作为初始候选加入到光束中。为简单起见,我们使用START(h) 表示返回候选对象 (h;) 的动作。图2(a),在步骤0,“迪伦” 添加 (迪伦,梁。匹配度初始化为0。
YIELD: a new intermediate candidate in the beam if the current candidate has not reached the tail.
The next largest attended token (with the largest score from the attention matrix) is appended
to the end of the current candidate to yield the new candidate. The corresponding
matching degrees are increased by the associated attention scores. At step 1 (orange arrow
in Figure 2(a)), “is” is appended to the current candidate to yield (Dylan, is, , since “is”
has the largest attention score with “Dylan” in the attention matrix. The attention score is
0.3 as highlighted in orange in Figure 2(b). The multi-head attention is reduced to a single
head so that every two tokens of the sentence are associated with one attention weight. We
experiment with different reduction setups in Sec. A.3. “x” marks the tokens (prior to the
current token) that are not considered in the search to prevent searching backward. Step 2
similarly takes YIELD action to produce (Dylan, is songwriter, . We use YIELD(c; s;As)
to denote the action, where c is a current candidate, s represents the sentence, and As is the attention matrix from the forward pass of the pre-trained LM over s, which yields a new
candidate.
STOP: the search step if the candidate has reached the tail, then add the candidate as a valid candidate
fact into the beam. As beam size equals to 1, (Dylan, is, songwriter) is the only returned
candidate fact for the given pair. We denote this step using STOP(c; t), which returns a
valid fact.

若有收获,就点个赞吧
0 人点赞
