



1 域名系统DNS(Domain Name System)
1.1 DNS服务的作用
将域名(如:网址)解析为IP地址。域名解析是在我们成功访问网站之前进行的。
- 常用的DNS服务器有:
222.222.222.222是电信的DNS服务器;8.8.8.8是google的DNS服务器。
例如,在访问一个网站(web服务)时,我们输入网址,然后就可以访问网站。其背后的实际过程如下:
- 首先,用户输入对应网站的网址(假设为:
http://www,yuque.com) - 接下来,用户主机 会向 DNS服务器 发送请求。然后DNS服务器会把这个域名(网址)解析为对应网站的IP地址;
- 解析成功之后,DNS服务器会把解析后的IP地址发送给 用户主机;
- 然后用户主机才能访问该网站。

1.1 能登陆QQ,但不能访问网站?
当我们将DNS服务器配置错误,我们就可能访问不了网站了。此时,实际上并不是上不了网,只是说我们不能通过DNS服务器来解析域名了。但是我们可以手动输入对应的IP地址去访问。
例如:可以访问QQ,但是不能访问网站,为什么? 答:
- QQ能登陆—》说明我们可以访问Internet,即网络层没问题;访问不了网站—-》可能没有正常的域名解析。
- 新疑问:QQ登陆不需要域名解析吗?
- 答:是需要的。但是QQ当我们在登录时,将“登陆服务器”类型改为TCP类型时,地址选项会出现:IP地址、若干个域名。所以,当域名解析出问题的时候,QQ会直接使用IP地址。

1.2 什么是域名?
全球的网站、服务器都很多,当网民去访问这些网站、服务器时,更愿意去使用网站的名称(域名(网址)),而不愿意使用很难记住的IP地址去访问。
所以,就要求Internet中的网站、服务器等 的 名称 需要是全球唯一的,即不能重复。所以,这些网站、服务器再使用之前,需要向互联网组织进行名称注册。
1.2.1 互联网中的域名结构
互联网采用了层次树状结构的命名方法。采用这种命名方法,任何一个连接在互联网上的主机或路由器,都有一个唯一的层次结构的名字,即**域名(domain name)**。
这里,“域”(domain)是名字空间中一个可被管理的划分。域还可以划分为子域,而子域还可继续划分为子域的子域,这样就形成了顶级域、二级域、三级域,等等。
中央电视台用于收发电子邮件的计算机(即邮件服务器)
其中:
- 每一个域名都由 标号(label)序列组成,各标号之间用点隔开;
- 每一个标号不超过63个字符,不区分大小写;
- 由多个标号组成的完整域名总共不超过255个字符;
- DNS既不规定一个域名需要包含多少个下级域名,也不规定每一级的域名代表什么意思。各级域名由其上一级的域名管理机构管理,而最高的**顶级域名**则由ICANN进行管理。用这种方法可使每一个域名在整个互联网范围内是唯一的,并且也容易设计出一种查找域名的机制。【所以,在申请域名时,只要二级域名是独一无二的,就可以使用】
顶级域名(TLD:top level domain):
- 国家顶级域名nTLD:如
cn表示中国;us表示美国。
- 国家顶级域名nTLD:如
- 通用顶级域名gTLD:如:
com/net/org/gov/int/edu/等等;
- 通用顶级域名gTLD:如:
- 基础域名结构:这猴子那个顶级域名只有一个,即
arpa,用于反向域名解析,因此又称为 反向域名。
- 基础域名结构:这猴子那个顶级域名只有一个,即
用域名树表示互联网的域名系统:
域名树中的树叶就是单台计算机的名字,他不能再继续往下滑分子域了。
1.2.2 一些操作命令
Ping: 可以进行域名解析,得到IP地址;nslookup:也可以进行域名解析,得到IP地址;- 如:
nslookup www.baidu.com
- 如:

1.3 域名解析的过程
一个服务器所负责管辖的(或有权限的)范围叫做区(zone)。各单位根据具体情况来划分自己管辖范围的区。但在一个区中的所有节点必须是能够连通的。每一个区设置相应的权限域名服务器(authoritative name server),用来保存该区中的所有主机的域名到IP地址的映射。总之,DNS服务器的管辖范围不是以“域”为单位,而是以“区”为单位。
区是 DNS服务器实际管辖的范围,区可能等于或小于域,但不能大于域。
如:

在图6-3中的每一个域名服务器都能够进行部分域名到IP地址的解析。当某个DNS 服务器不能进行域名到IP地址的转换时,它就设法找互联网上别的域名服务器进行解析。

每一种DNS服务器都不止一个。如:根域名服务器可能有多个、com域名服务器也有多个。
根域名服务器:最高层次的域名服务器。根域名服务器知道所有的顶级域名服务器的域名和IP。它不进行具体的域名解析工作,但是它记录着各种解析顶级域名 对应的 DNS服务器。
比如:
- 记录着负责
org类型的域名解析过程的DNS服务器为最左边的(假设为1号服务器); - 记录着负责
com类型的域名解析过程的DNS服务器为最左边的(假设为2号服务器); - …….等等。
- 记录着负责
顶级域名服务器:这些域名服务器负责管理在该顶级域名服务器注册的所有二级域名;
这些顶级域名服务器都知道 根服务器 是谁。
权限域名服务器:负责一个区的域名服务器;
- 本地域名服务器: 当一个主机发出 DNS 查询请求时,这个查询请求报文就发送给本地域名服务器。
域名解析过程:
主机向本地域名服务器的查询一般都是采用递归查询。如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户的身份,向其他根域名服务器继续发出查询请求报文。
当然,我们使用的主机可以不安装 域名系统DNS,直接使用外网提供的DNS服务器来完成域名的解析。
但是,下列几种情况,必须要有本地域名服务器:
- 内网中有 邮件服务、web服务等(即内网有域环境 时),并且只让内网中的用户来访问,此时需要 自己安装DNS服务器;
- 降低域名解析占用的流量(因为DNS服务器有缓存功能,会缓存一些域名对应的IP地址,当用户再次访问该网站时,本地域名服务器缓存的就有对应的IP地址,从而就不用在去 找其他DNS服务器寻求帮助了);


1.3.1 DNS服务器使用高速缓存
为了提高DNS查询效率,并减轻根域名服务器的负荷和减少互联网上的DNS查询报文数量,在域名服务器中广泛地使用了高速缓存(有时也称为高速缓存域名服务器)。高速缓存用来存放最近查询过的域名以及从何处获得域名映射信息的记录。
例如,在图6-5(a)的查询过程中:
- 如果在不久前已经有用户查询过域名为
y.abc.com的IP地址,那么本地域名服务器就不必向根域名服务器重新查询y.abc.com 的I地址,而是直接把高速缓存中存放的上次查询结果(即y.abc.com的IP地址)告诉用户。 - 假定本地域名服务器的缓存中并没有
y.abc.com的I地址,而是存放着顶级域名服务器dns.com的IP地址,那么本地域名服务器也可以不向根域名服务器进行查询,而是直接向com顶级域名服务器发送查询请求报文。
这样不仅可以大大减轻根域名服务器的负荷,而且也能够使互联网上的DNS查询请求和回答报文的数量大为减少。
2 动态主机配置协议DHCP
DHCP协议 需要有DHCP服务器给计算机分配IP地址。而计算机使用DHCP协议 来请求获得IP地址。
因此,DHCP也是使用 服务器—客户机 的一个结构。
2.1 静态、动态IP地址
静态IP地址:
计算机一班固定放在某个地方,不挪动。则通常设置为 静态IP地址。
如,机房的服务器,机房的计算机等等。
- 使用静态IP地址的好处是:我们可以通过IP地址来访问它。
动态IP地址:
学生上课时,从一个教室到另一个教室上课,每个教室都是一个网段。如果让用户自己设置IP地址,那么可能会引起地址冲突的情况。所以,此时,使用DHCP服务器,来为每个用户动态的产生IP地址。
如,在windows下,可以设置静态、动态IP地址:
2.2 DHCP客户端请求IP地址的过程(单个网段)

假设在该网络中,有两个DHCP服务器,以若干计算机(A,B,C,…)。
开始时,需要IP地址 的主机(假设是A)在启动时就想DHCP服务器广播发送 发现文报(DHCPDISCOVER)(将目的的IP地址设置为全1,即255.255.255.255),这时该主机就成为了DHCP客户。
- 发送广播报文是因为现在还不知道DHCP服务器在什么地方,因此要将IP数据报的源IP地址设为全0。这样,在本地网络上的所有主机都能够收到这个广播报文,但只有DHCP服务器才对此广播报文进行回答。
- 若找到,则返回找到的信息。若找不到,则从服务器的地址池(address pool)中取一个地址分配给该计算机。
DHCP服务器先在其数据库中查找该计算机的配置信息。DHCP服务器的回答报文叫做提供报文(DHCPOFFER),表示“提供”了IP地址等配置信息。 | 》如上图所示,会有多台DHCP服务器。但是我们并不愿意在每一个网络上都设置一个DHCP服务器,因为这会使DHCP服务器的数量太多。(上图是在一个网络中有多个DHCP服务器。)
》因此现在是使每一个网络至少有一个DHCP中继代理(relay agent)(通常是一台路由器,见图6-19),它配置了DHCP服务器的IP地址信息。
- 当DHCP中继代理收到主机A以广播形式发送的发现报文后,就以单播方式向DHCP服务器转发此报文,并等待其回答。
| | —- |
该部分属于跨网段的内容
- 收到DHCP服务器回答的提供报文后,DHCP中继代理再把此提供报文发回给主机A。
需要注意的是,图6-19只是个示意图。实际上,DHCP报文只是UDP用户数据报的数据,它还要加上UDP首部、I数据报首部,以及以太网的MAC帧的首部和尾部后,才能在链路上传送。
2.2.1 DHCP服务器分配的IP地址是临时的
DHCP服务器分配给DHCP客户的IP地址是临时的,因此 DHCP客户只能在一段有限的时间内使用这个分配到的IP地址。DHCP协议称这段时间为租用期(lease period),但并没有具体规定租用期应取为多长或至少为多长,这个数值应由DHCP服务器自己决定。
应该合理设置租用期。如果是在流动频繁的主机用户的场景中,租用期应设置较短。否则,在租用期内,该IP就只能供这个主机使用,所以,应合理设置租用期。
比如:
一个校园网的DHCP 服务器可将租用期设定为1小时。DHCP服务器在给DHCP发送的提供报文的选项中给出租用期的数值。按照RFC 2132的规定,租用期用4字节的二进制数字表示,单位是秒。因此可供选择的租用期范围从1秒到136年。
- DHCP客户也可在自己发送的报文中(例如,发现报文)提出对租用期的要求。
2.2.2 DCHP详细工作过程
DHCP的详细工作过程如图6-20所示。DHCP客户使用的UDP端口是68,而 DHCP服务器使用的UDP端口是67。这两个UDP端口都是熟知端口。



2.3 DHCP客户端请求IP地址的过程(跨网段)
| DHCP分配IP地址的过程,实际上是(假设设备A需要分配IP地址): - A发送广播,该广播含有A的MAC地址。该广播的信息大概就是:我这个MAC地址的设备 的IP地址是多少? - 也就是:知道MAC地址,来解析IP地址。 - 而之前所学的ARP协议,是已知IP地址,发送广播,来求MAC地址。 所以,DHCP客户端请求分配IP地址的过程 就是 逆向ARP。 |
|---|
有n个网段需要被分配IP地址,那么DHCP服务器就会创建n个作用域。
如下图,有三个网段中的PC机需要被分配IP地址,那么DHCP服务器就会创建三个作用域。

过程:(假设PC机2申请IP地址)
- PC机2 先发一个广播。但是广播传到路由器1处时,路由器会把广播隔绝广播发送至其他网段,所以PC机2发送的广播传不到DHCP服务器。
此时,需要在路由器1 的网段3的那个接口处 配置一个
IP helper address命令。通过该命令将 PC机2发送的广播 发送至 DHCP服务器。IP helper address命令的作用:该命令会将收到的广播定向的发送到 指定的IP地址的DHCP服务器。- 这个命令其实就是一个DHCP中继代理(relay agent)。
DHCP服务器收到广播之后(通过
IP helper address命令),查看处该广播来源于哪个网段(此处来源于网段3),然后在该网段的作用域(此处是作用域2)中选取一个IP地址。然后将该IP地址发送至路由器1,然后路由器1再将所得的IP地址给PC机2。
注意:如果是PC机3需要分配IP地址,那就不需要IP helper address 命令。因为它和DHCP服务器属于同一个网段。
2.3.1 练习:DHCP跨网段分配IP地址

3 文件传输协议FTP(File Transfer Protocol)
网络环境中的一项基本应用就是:将文件从一台计算机复制到另一台可能相距很远的计算机中。
但是这一过程的实现比较困难,经常遇到的困难是:
- 计算机存储格式的不同;
- 文件目录结构、文件命名规则不同;
- 对于相同的文件存储功能,操作系统使用的命令不同;
- 访问控制方法不同。
文件传送协议FTP只提供文件传送的基本服务,它使用TCP可靠的运输服务。FTP的主要功能是减少或消除在不同操作系统下处理文件的不兼容型。
FTP使用客户-服务器方式。一个FTP服务器进程可同时为多个客户进程提供服务。FTP服务器进程由两大部分组成:一个主进程,负责接受新的请求;另外若干个从属进程,负责处理单个请求。
主进程的工作步骤:
- 打开熟知端口(端口号为21),使客户进程能够连接上;
- 等待客户进程发出连接请求;
- 启动从属进程 处理客户进程发来的请求。从属进程对客户进程的请求处理完毕后即终止,但从属进程在运行期间根据需要可以创建其他一些子进程;
- 回到等待状态,继续接受其他客户进程发来的请求。主进程与从属进程的处理是并发进行的。
3.1 FTP的工作情况
如下图。图中:
- 椭圆圈 表示 在系统中运行的进程;
- 图中的服务器端有两个从属进程:控制进程、数据传送进程。
简单起见,服务器端没有画 主进程。
客户端除了控制进程、数据传送进程之外,还有一个用户界面用来和用户接口。
在进行文件传输时,FTP的客户和服务器之间要建立两个并行的TCP连接:“控制连接”和“数据连接”。
- TCP控制连接在整个会话期间一直保持打开,FTP客户所发出的传送请求,通过控制连接发送给服务器端的控制进程,但控制连接并不用来传送文件。
- 实际用于传输文件的是“TCP数据连接”。
- 服务器端的控制进程 在接收到FTP客户发送来的文件传输请求后就创建“数据传送进程”和“TCP数据连接”,用来连接客户端和服务器端的数据传送进程。
- 数据传送进程 实际完成文件的传送,在传送完毕后关闭“数据传送连接”并结束运行。

过程:
- 当客户进程向服务器进程发出建立连接请求时,要寻找连接服务器进程的熟知端口21,同时还要告诉服务器进程自己的另一个端口号码(假设为1409),用于建立数据传送连接。【此时,建立“控制连接”,用于发送FTP命令信息(如:上传、下载命令,文件重命名命令)】
- 接着,服务器进程用自己传送数据的熟知端口20 与 客户进程所提供的端口号(假设1410)建立数据传送连接。【此时建立“数据连接”。用于实际的上传、下载数据】由于FTP使用了两个不同的端口号,所以数据连接与控制连接不会发生混乱。
使用两个独立的连接的主要好处是:使协议更加简单和更容易实现,同时在传输文件时还可以利用控制连接对文件的传输进行控制。例如,客户发送“请求终止传输”。
3.2 FTP协议的主动模式、被动模式
- 主动模式:服务端从 20端口 主动向客户发起连接;
- 被动模式:服务端在指定范围内的某个端口被动等待客户端发起连接。
3.2.1 服务器打开防火墙时,防火墙需打开哪些端口?


由于在被动模式下,FTP服务器端口是被动的等待客户端指定某个端口。不同客户端使用的服务器的端口不一样。所以,如果在被动模式下,想要下载数据,那服务端防火墙应该把所有客户端请求的端口都打开,这样不划算。所以,干脆就全都不打开,因此不能下载数据。
所以,FTP服务端,如果有防火墙,需要在防火墙上打开20和21端口。 并 使用主动模式进行数据连接。
3.3 FTP传输模式
- 文本模式:ASCII模式,以文本序列传输数据;
- 二进制模式:Binary模式,以二进制序列传输数据。
4 远程终端协议TELNET
telnet协议,默认使用TCP的23端口。
使用**net user** 命令来管理用户账号。
Net User命令是一个DOS命令,必须在Windows nt以上系统的MS-DOS模式下运行
【具体命令:https://baijiahao.baidu.com/s?id=1593063379778041306&wfr=spider&for=pc】
**talnet [远程IP地址] [端口]**:测试到远程的某个端口能否打开。
5 远程桌面协议RDP(remote desktop protocol)
**RDP协议 = TCP + 3389端口**
打开远程桌面连接:
1、在运行中,输入【mstsc】;
2、或者,直接搜索【远程桌面连接】
Mstsc (Microsoft terminal services client)
类似于远程终端协议。但是远程桌面协议 使用界面
注意:
Windows 2003 server 是多用户操作系统;而Windows XP和Windows 7 是单用户操作系统。
5.1 将本地硬盘映射到远程
在远程连接时,进行设置: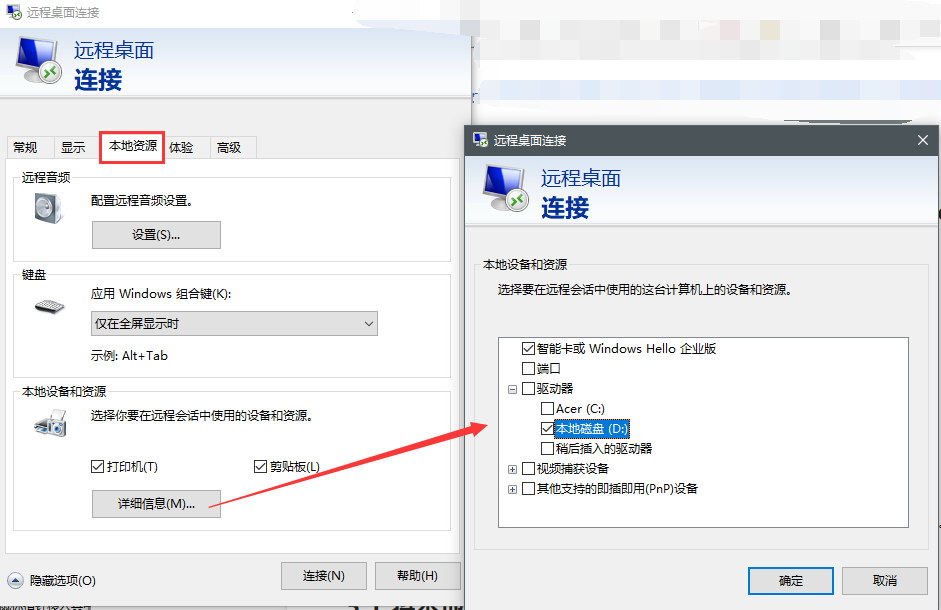
此时,进入之后,就可以看到本地硬盘了: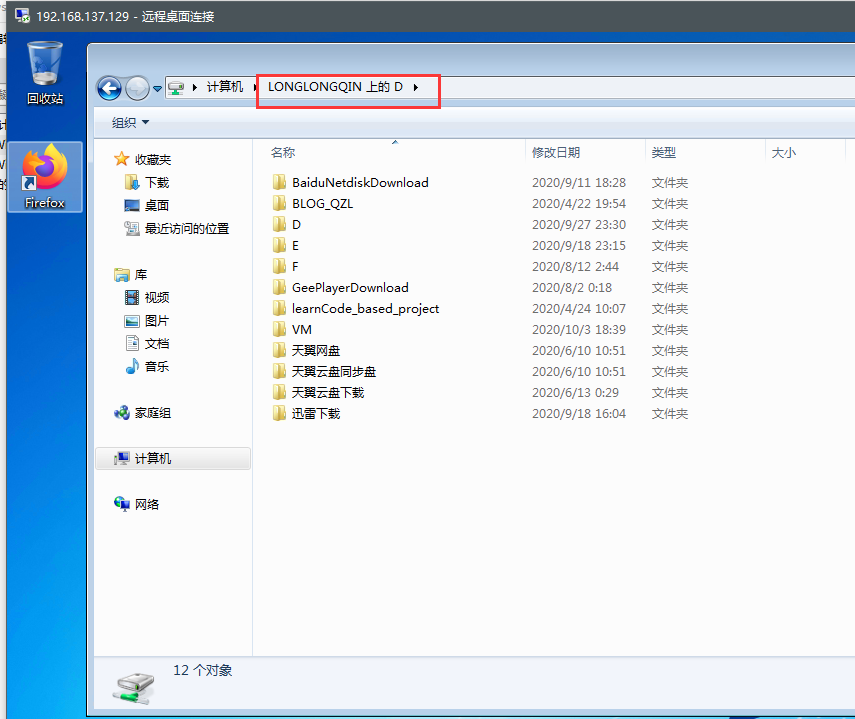
6 万维网WWW
万维网www(World Wide Web)并非某种特殊的计算机网络。万维网是一个大规模的、联机式的信息储藏所,英文简称为 Web。
万维网用链接的方法能非常方便地从互联网上的一个站点访问另一个站点(也就是所谓的“链接到另一个站点”),从而主动地按需获取丰富的信息。图6-8说明了万维网提供分布式服务的特点。
图6-8画出了五个万维网上的站点,它们可以相隔数千公里,但都必须连接在互联网上。每一个万维网站点都存放了许多文档。在这些文档中有一些地方的文字是用特殊方式显示的(例如用不同的颜色,或添加了下划线),而当我们将鼠标移动到这些地方时,鼠标的箭头就变成了一只手的形状。这就表明这些地方有一个链接(link)(这种链接有时也称为超链hyperlink),如果我们在这些地方点击鼠标,就可以从这个文档链接到可能相隔很远的另一个文档。
万维网是一个分布式的超媒体(hypermedia)系统,它是超文本(hypertext)系统的扩充。
超文本:包含指向其他文档的连接的文本(text)。也就是说,一个超文本由多个信息源链接而成,而这些信息员可以分布在世界各地,并且数目也是不受限制的。
超媒体与超文本的区别是文档内容不同。超文本文档仅包含文本信息,而超媒体文档还包含其他表示方式的信息,如图形、图像、声音、动画以及视频图像等。
万维网以客户-服务器方式工作。
- 上面所说的浏览器就是在用户主机上的万维网客户程序。
- 万维网文档所驻留的主机则运行服务器程序,因此这台主机也称为万维网服务器。
客户程序向服务器程序发出请求,服务器程序向客户程序送回客户所要的万维网文档。在一个客
户程序主窗口上显示出的万维网文档称为页面(page)。
从以上所述可以看出,万维网必须解决以下几个问题:
- 如何标志分布在整个互联网上的万维网文档?=========》答:使用 统一资源定位符URL(uniform resource locator)
- 用什么样的协议来实现万维网上的各种链接?======》答:使用超文本传输协议HTTP(hypertext transfer protocol)
- 怎样使不同作者创作的不同风格的万维网文档,都能在互联网上的各种主机上显示出来,同时使用户清楚地知道在什么地方存在着链接?=========》答:使用超文本标记语言HTML(hypertext markup language)
- 怎样能使用户方便的找到所需信息?
6.1 统一资源定位符URL(uniform resource locator)
统一资源定位符URL是用来表示从互联网上得到的资源位置和访问这些资源的方法。URL 给资源的位置提供一种抽象的识别方法,并用这种方法给资源定位。只要能够对资源定位,系统就可以对资源进行各种操作,如存取、更新、替换和查找其属性。由此可见,URL 实际上就是在互联网上的资源的地址。只有知道了这个资源在互联网上的什么地方,才能对它进行操作。显然,互联网上的所有资源,都有一个唯一确定的URL。
这里所说的“资源”是指:在互联网上可以被访问的任何对象,包括文件目录、文件、文档、图像、声音等,以及与互联网相连的任何形式的数据。“资源”还包括电子邮件的地址和USENET新闻组,或USENET新闻组中的报文。
URL的一般形式:
<协议>:指出使用什么协议来获取该万维网文档。(最常用的是HTTP协议,其次是FTP协议);://:是规定的格式;<主机>:指出这个万维网文档是在哪一台主机上;<端口>和<路径>:有时可以省略。现在有些浏览器为了方便用户,在输入 URL时,可以把最前面的“http:/l”甚至把主机 名最前面的“www”省略,然后浏览器替用户把省略的字符添上。例如,用户只要键入 ctrip.com,浏览器就自动把未键入的字符补齐,变成http://www.ctrip.com。
6.1.1 最常用的一种URL:使用HTTP的URL

HTTP的默认端口号是80;通常可以省略。若再省略文件的<路径>项,则URL就指到互联网上的某个主页(home page)。
【主页】可以是以下情况之一:
- 一个WWW服务器的最高级别的页面;
- 某一个组织或部门的一个定制的页面或目录。从这样的页面可链接到互联网上与本组织或部门忧患的其他站点;
- 由某一个人自己设计的WWW页面;
|
 |
| —- |
|
| —- |
URL里面的字母不分大小写,但为了便于阅读,有时故意使用一些大写字母。
6.2 超文本传输协议HTTP(hypertext transfer protocol)
HTTP协议定义了浏览器(即万维网客户进程)怎样向万维网服务器请求万维网文档,
以及服务器怎样把文档传送给浏览器。
从层次的角度看,HTTP是面向事务的(transaction-oriented)应用层协议,它是万维网上能够可靠地交换文件(包括文本、声音、图像等各种多媒体文件)的重要基础。
请注意,HTTP不仅传送完成超文本跳转所必需的信息,而且也传送任何可从互联网上得到的信息,如文本、超文本、声音、图像 等。
每个万维网网点都有一个服务器进程,它不断地监听TCP的端口80,以便发现是否有浏览器(即万维网客户。请注意,浏览器和万维网客户是同义词)向它发出连接建立请求。
一旦监听到连接建立请求并建立了TCP连接之后,浏览器就向万维网服务器发出浏览某个页面的请求,服务器接着就返回所请求的页面作为响应。最后,TCP连接就被释放了。
在浏览器和服务器之间的请求和响应的交互,必须按照规定的格式和遵循一定的规则。这些格式和规则就是超文本传送协议HTTP。
HTTP规定在HTTP客户与HTTP服务器之间的每次交互,都由一个ASCII码串构成的请求和一个类似的通用互联网扩充,即“类MIME (MIME-like)”的响应组成。HTTP报文通常都使用TCP连接传送。
用户浏览页面的方法有两种。
- 一种方法是在浏览器的地址窗口中键入所要找的页面的URL。
- 另一种方法是在某一个页面中用鼠标点击一个可选部分,这时浏览器会自动在互联网上找到所要链接的页面。
HTTP协议的特点:
HTTP使用了面向连接的TCP作为运输层协议,保证了数据的可靠传输。HTTP不必考虑数据在传输过程中被丢弃后又怎样被重传。但是,HTTP 协议本身是无连接的。这就是说,虽然HTTP使用了TCP连接,但通信的双方在交换HTTP报文之前不需要先建立HTTP连接。
在1997年以前使用的是RFC 1945定义的HTTP/1.0协议。现在普遍使用的升级版本HTTP/1.1已是互联网建议标准[RFC 7231]。
HTTP协议是无状态的(stateless)。也就是说,同一个客户第二次访问同一个服务器上的页面时,服务器的响应与第一次被访问时的相同(假定现在服务器还没有把该页面更新),因为服务器并不记得曾经访问过的这个客户,也不记得为该客户曾经服务过多少次。HTTP的无状态特性简化了服务器的设计,使服务器更容易支持大量并发的HTTP请求。
6.2.1 从浏览器请求一个万维网文档到收到整个文档所需时间
用户在点击鼠标链接某个万维网文档时,HTTP协议首先要和服务器建立TCP连接。这需要使用三报文握手。当建立TCP连接的三报文握手的前两部分完成后(即经过了一个RTT 时间后),万维网客户就把HTTP请求报文,作为建立TCР连接的三报文握手中的第三个报文的数据,发送给万维网服务器。服务器收到HTTP请求报文后,就把所请求的文档作为响应报文返回给客户。
从图6-10可看出,请求一个万维网文档所需的时间是该文档的传输时间(与文档大小成正比)加上两倍往返时间RTT(一个RTT用于连接TCP 连接,另一个RTT用于请求和接收万维网文档。TCP建立连接的三报文握手的第三个报文段中的数据,就是客户对万维网文档的请求报文)。
6.2.2 代理服务器
代理服务器(proxy server)是一种网络实体,它又称为万维网高速缓存(Web cache)。代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的请求相同,就返回暂存的响应,而不需要按URL的地址再次去互联网访问该资源。代理服务器可在客户端或服务器端工作,也可在中间系统上工作。
下面我们用例子说明它的作用。
1、
设图6-11(a)是校园网不使用代理服务器的情况。这时,校园网中所有的计算机都通过2Mbit/s专线链路(Ry-R)与互联网上的源点服务器建立TCP连接。因而校园网各计算机访问互联网的通信量往往会使这条2 Mbit/s的链路过载,使得时延大大增加。
2、
图6-11(b)是校园网使用代理服务器的情况。这时,访问互联网的过程是这样的:
- 校园网的计算机中的浏览器向互联网的服务器请求服务时,就先和校园网的代理服务器建立TCP 连接,并向代理服务器发出HTTP请求报文(见图6-11(b)中的②)。
- 若代理服务器已经存放了所请求的对象,代理服务器就把这个对象放入 HTTP 响应报文中返回给计算机的浏览器。
- 否则,代理服务器就代表发出请求的用户浏览器,与互联网上的源点服务器(origin server)建立TCP连接(如图6-11(b)中的O所示),并发送HTTP请求报文。
- 源点服务器把所请求的对象放在HTTP响应报文中返回给校园网的代理服务器。
- 代理服务器收到这个对象后,先复制在自己的本地存储器中(留待以后用),然后再把这个对象放在HTTP响应报文中,通过已建立的TCP连接(见图6-11(b)中的①),返回给请求该对象的浏览器。

我们注意到,代理服务器有时是作为服务器(当接受浏览器的HTTP 请求时),但有时却作为客户(当向互联网上的源点服务器发送HTTP请求时)。
在使用代理服务器的情况下,由于有相当大一部分通信量局限在校园网的内部,因此,2 Mbit/s专线链路(Ry-Rz)上的通信量大大减少,因而减小了访问互联网的时延。
6.2.3 HTTP的报文结构
HTTP有两类报文:
- 请求报文——从客户向服务器发送请求报文,见图6-12(a)。
- 响应报文—从服务器到客户的回答,见图6-12(b)。

由于HTTP是面向文本的(text-oriented),因此在报文中的每一个字段都是一些ASCII码串,因而各个字段的长度都是不确定的。
HTTP请求报文和响应报文都是由三个部分组成的。可以看出,这两种报文格式的区别就是开始行不同。
- 开始行,用于区分是请求报文还是响应报文。在请求报文中的开始行叫做请求行(Request-Line),而在响应报文中的开始行叫做状态行(Status-Line)。在开始行的三个字段之间都以空格分隔开,最后的“CR”和“LF”分别代表“回车”和“换行”。
- 首部行,用来说明浏览器、服务器或报文主体的一些信息。首部可以有好几行,但也可以不使用。在每一个首部行中都有首部字段名和它的值,每一行在结束的地方都要有“回车”和“换行”。整个首部行结束时,还有一空行将首部行和后面的实体主体分开。
- 实体主体(entity body),在请求报文中一般都不用这个字段,而在响应报文中也可能没有这个字段。
6.2.3.1 HTTP请求报文的特点
请求报文的第一行“请求行”只有三个内容:方法、请求资源URL、HTTP的版本。
这里的“方法(method)”指:面向对象技术中使用的专门名词。它是指 对所请求的对象进行的操作,这些方法实际上也就是一些命令。 因此,请求报文的类型是由他所采用的的方法决定的。下表给出了请求报文中常用的几种方法。


6.2.3.1 HTTP响应报文的特点


6.3 在服务器上存放用户的信息
由于HTTP是无状态的。这样简化了服务器的设计。
但是,在实际工作中,一些万维网站点却常常希望能够识别用户。
例如,在网上购物时,一-个顾客要购买多种物品。当他把选好的一件物品放入“购物车”后,他还要继续浏览和选购其他物品。因此,服务器需要记住用户的身份,使他接着选购的一些物品能够放入同一个“购物车”中,这样就便于集中结账。有时某些万维网站点也可能想限制某些用户的访问。要做到这点,可以在HTTP中使用Cookie。
在RFC 6265中对Cookie进行了定义,规定万维网站点可以使用Cookie来跟踪用户。Cookie原意是“小甜饼”(广东人用方言音译为“曲奇”),目前尚无标准译名,在这里Cookie表示在HTTP服务器和客户之间传递的状态信息。现在很多网站都已广泛使用Cookie。
Cookie的工作过程:
- 用户A浏览某个使用Cookie的网站时,该网站的服务器就为A产生一个唯一的识别码,并以此作为索引在服务器的后端数据库中产生一个项目。接着在给A的HTTP响应报文中添加一个叫做 set-cookie 的首部行。这里的“首部字段名”就是“set-cookie”。后面的“值”就是赋予该用户的“识别码”。例如下面的首部行:

- 当A收到这个响应时,其浏览器就在它管理的特定cookie文件中添加一行,其中包括这个服务器的主机名和set-cookie后面给出的识别码。当A继续浏览这个网站时,每发送一个HTTP请求报文,其浏览器就会从其cookie文件中提取出这个网站的识别码,并放到HTTP请求报文的cookie首部行中:

- 于是,这个网站就能跟踪用户
31d4d96e407aad42(用户A)在该网站的活动。注意,服务器并不需要知道该用户的真实姓名及其他信息。但服务器能知道用户31d4d96e407aad42在什么时间访问了哪些页面,以及访问这些页面的顺序。如果A是在网上购物,那么这个服务器就可以为A维护一个所购物品的列表,使得A在结束此次购物时可以一起付费。

所以,cookie会引起争议。即对于用户隐私的保护问题。网站服务器知道了A的一些信息,就可能报这些信息出卖给第三方。
但是,认为cookie会把计算机病毒待到用户的计算机中,是对cookie的误解。cookie只是一个小小的文本文件,不是计算机的可执行程序,因此不肯能传播计算机病毒,也不可能用来获取用户计算机硬盘中的信息。
6.4 使用Web代理服务器访问网站
用户不直接访问网站,而是通过Web代理服务器来访问:
主机A访问搜狐:
- 主机A向Web服务器发送访问搜狐的请求;
- Web服务器接受到A的请求,然后访问搜狐网站,并将结果发送给A。
Web服务器还有其他功能:
- 有缓存功能:假设A访问过搜狐,那么Web服务器会将搜狐这个网站缓存下来。当主机B来访问搜狐时,Web服务器看看自己的缓存中有没有搜狐,有那就直接发送给主机B。
- 控制访问网站:Web服务器可以控制哪些网站可以访问,哪些网站不可访问;
- 控制网段访问:Web服务器可以控制哪些网段可以访问,哪些网段不可访问;
- ……
6.4.1 Web服务器可以解决的问题
1、可以节省内网访问Internet的带宽
假设,学校内网中有很多主机。如果不设置Web代理服务器,那这些主机都需要从内网中出去,访问Internet。
如果设置Web代理服务器,在Web代理服务器中缓存了一些网站信息。当有其它主机再次访问这些网站时,会先通过Web代理服务器,Web代理服务器查看自己的缓存中是否有这些网站的信息。如果有,则直接发送给主机 而不需要再去Internet中。如果缓存中没有,那么才会去Internet中查找。
2、通过Web代理可以绕过防火墙
比如,科学上网时,就是使用的国外的代理服务器

如果,不适用代理直接访问时,会被路由器拦截。路由器识别出我们访问“油管web”的地址是被列为禁止访问的。
但是使用国外web代理服务器时,路由器是没有禁止访问国外web代理服务器的(或许过一段时间就被禁止了),那么就可以通过国外web代理服务器访问国外网站了。
路由器只关注数据包的来源与去路。不关注数据包的具体内容。
3、避免跟踪
假设我们在某网站发表言论。如果我们使用web代理服务器,那么该网站记录下来的IP地址是web代理服务器的IP。而查不到我们自己主机的IP地址。
这样就可以,避免被跟踪。
7 电子邮件
实时通信有两个缺点:
下图演示的是“用户A从QQ邮箱发送邮件到用户B的163邮箱的过程”:
图示的六个步骤分别进行如下的说明:
①、用户A的电子邮箱为:xx@qq.com,通过邮件客户端软件写好一封邮件,交到QQ的邮件服务器,这一步使用的协议是**SMTP**,对应图示的①;
②、QQ邮箱会根据用户A发送的邮件进行解析,也就是根据收件地址判断是否是自己管辖的账户,如果收件地址也是QQ邮箱,那么会直接存放到自己的存储空间。这里我们假设收件地址不是QQ邮箱,而是163邮箱,那么QQ邮箱就会将邮件转发到163邮箱服务器,转发使用的协议也是**SMTP**,对应图示的②;
③、163邮箱服务器接收到QQ邮箱转发过来的邮件,也会判断收件地址是否是自己,发现是自己的账户,那么就会将QQ邮箱转发过来的邮件存放到自己的内部存储空间,对应图示的③;
④、用户A将邮件发送了之后,就会通知用户B去指定的邮箱收取邮件。用户B会通过邮件客户端软件先向163邮箱服务器请求,要求收取自己的邮件,对应图示的④;
⑤、163邮箱服务器收到用户B的请求后,会从自己的存储空间中取出B未收取的邮件,对应图示⑤;
⑥、163邮箱服务器取出用户B未收取的邮件后,将邮件发给用户B,对应图示的⑥;最后三步用户B收取邮件的过程,使用的协议是**POP3或者IMAP**;
【注】:
在上述过程中:
- 步骤① 不允许匿名发送;步骤②允许匿名发送;
- 步骤②实际上还要使用DNS域名服务器的解析,需要将用户B的
xx@163.com使用的邮箱服务器的地址解析出来,才能进行发送;
7.1.1 邮件服务器
图示出现了两个邮件服务器,QQ和163邮件服务器。用户想要在网上收发邮件,必须要有专门的邮件服务器。邮件服务器我们可以假想为现实生活中的邮局。
如果按功能划分,邮件服务器可以划分为两种类型:
- SMTP邮件服务器:替用户发送邮件和接收外面发送给本地用户的邮件,对应上图的第①、②步。它相当于现实生活中邮局的邮件接收部门(可接收普通用户要投出的邮件和其他邮局投递进来的邮件)。
- POP3/IMAP邮件服务器:帮助用户读取SMTP邮件服务器接收进来的邮件,对应上图的第⑥步。它相当于专门为前来取包裹的用户提供服务的部门。
7.1.2 电子邮箱
电子邮箱也称为E-mail地址,比如用户A的xx@qq.com,和用户B的xx@163.com。用户能通过E-mail地址标识自己发送的电子邮件,同时也可以通过这个地址接收别人发来的电子邮件。
电子邮箱需要到邮件服务器进行申请,也就是说,电子邮箱其实就是用户在邮件服务器上申请的账户。邮件服务器会把接收到的邮件保存到为该账户所分配的邮箱空间中,用户通过用户名密码登录到邮件服务器查收该地址已经收到的邮件。一般来讲,邮件服务器为用户分配的邮箱空间是有限的。
7.1.3 邮件客户端软件(用户代理)
我们可以直接在网站上进行邮件收发,也可以用邮件客户端软件。比如常见的FoxMail,Outlook Express。邮件客户端软件通常集邮件撰写,发送和收发功能于一体,主要用于帮助用户将邮件发送给SMTP邮件服务器和从POP3/IMAP邮件服务器读取用户的电子邮件。
7.1.4 邮件传输协议
电子邮件需要在邮件客户端和邮件服务器之间,以及两个邮件服务器之间进行邮件传递,那就必须要遵守一定的规则,这个规则就是邮件传输协议。下面我们分别简单介绍几种协议(后面会详细讲解):
①、SMTP协议:全称为 Simple Mail Transfer Protocol,简单邮件传输协议。它定义了邮件客户端软件和SMTP邮件服务器之间,以及两台SMTP邮件服务器之间的通信规则。
②、POP3协议:全称为 Post Office Protocol,邮局协议。它定义了邮件客户端软件和POP3邮件服务器的通信规则。
③、IMAP协议:全称为 Internet Message Access Protocol,Internet消息访问协议,它是对POP3协议的一种扩展,也是定义了邮件客户端软件和IMAP邮件服务器的通信规则。
我们说所有的邮件服务器和邮件客户端软件程序都是基于上面的协议编写的。

若有收获,就点个赞吧
0 人点赞
