es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。
我们在kibana的DevTools中测试:
POST /_analyze{"text": "黑马程序员学习Java太棒了","analyzer": "standard"}
{"tokens" : [{"token" : "黑","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "马","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "程","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2},{"token" : "序","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3},{"token" : "员","start_offset" : 4,"end_offset" : 5,"type" : "<IDEOGRAPHIC>","position" : 4},{"token" : "学","start_offset" : 5,"end_offset" : 6,"type" : "<IDEOGRAPHIC>","position" : 5},{"token" : "习","start_offset" : 6,"end_offset" : 7,"type" : "<IDEOGRAPHIC>","position" : 6},{"token" : "java","start_offset" : 7,"end_offset" : 11,"type" : "<ALPHANUM>","position" : 7},{"token" : "太","start_offset" : 11,"end_offset" : 12,"type" : "<IDEOGRAPHIC>","position" : 8},{"token" : "棒","start_offset" : 12,"end_offset" : 13,"type" : "<IDEOGRAPHIC>","position" : 9},{"token" : "了","start_offset" : 13,"end_offset" : 14,"type" : "<IDEOGRAPHIC>","position" : 10}]}
语法说明: POST:请求方式 /_analyze:请求路径,这里省略了http://ip:9200,有kibana帮我们补充 请求参数,json风格: analyzer:分词器类型,这里是默认的standard分词器 text:要分词的内容
IK分词器
处理中文分词,一般会使用IK分词器。
ik分词器包含两种模式:
- ik_smart:最少切分,粗粒度
- ik_max_word:最细切分,细粒度
安装分词器ik
下载分词版本,解压到挂在目录plugins,然后重启es服务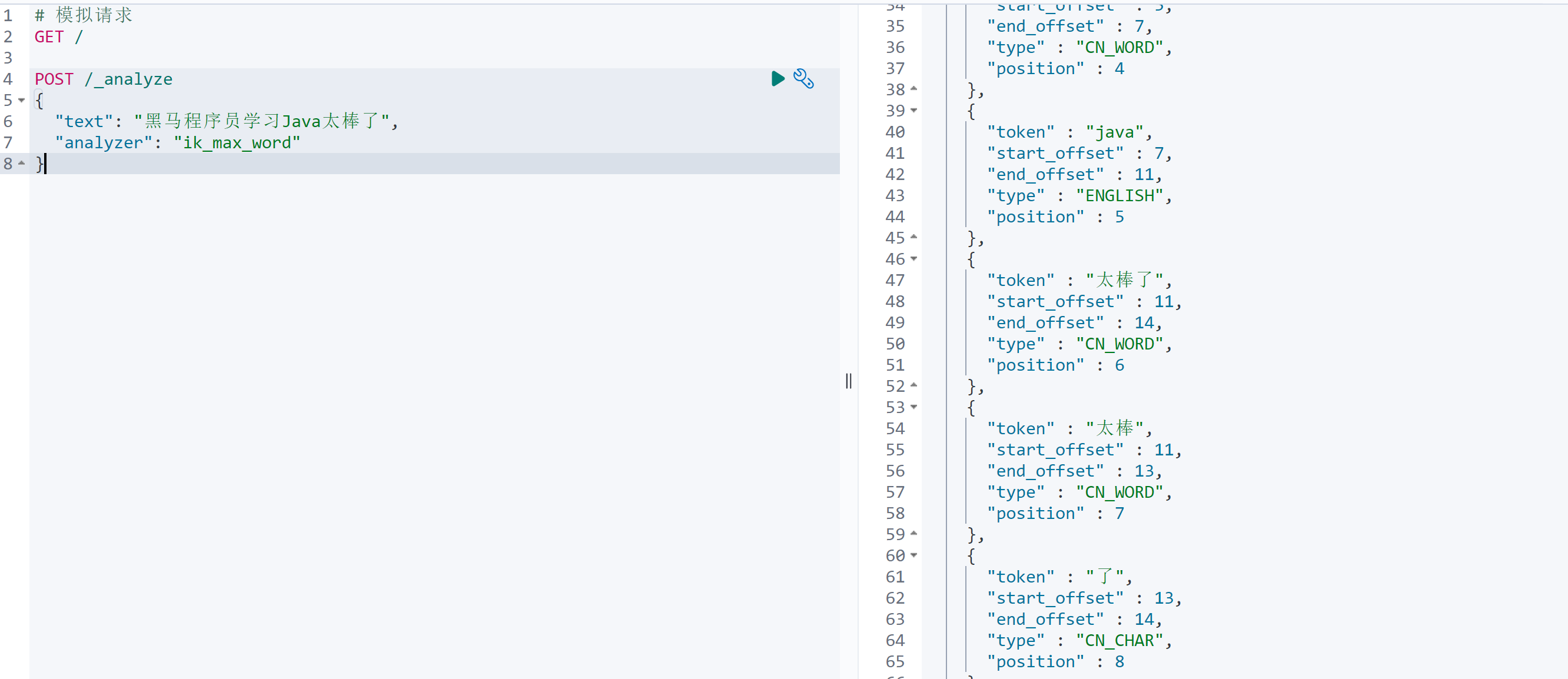
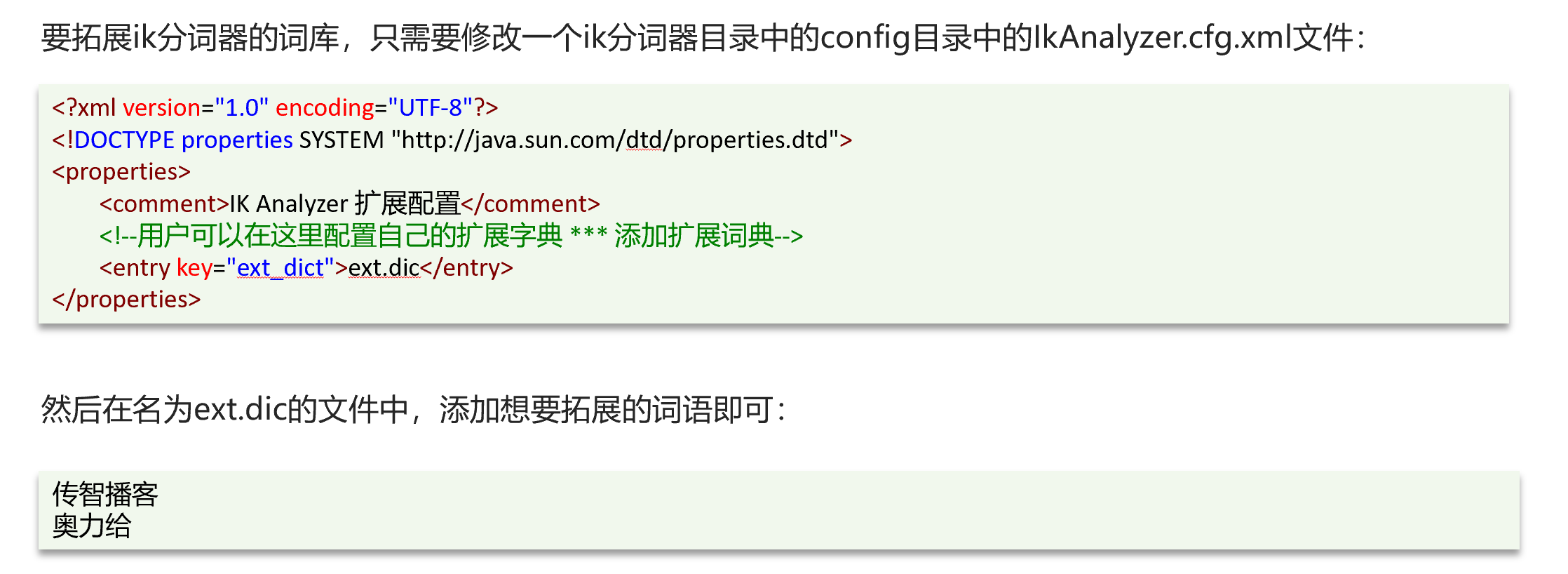
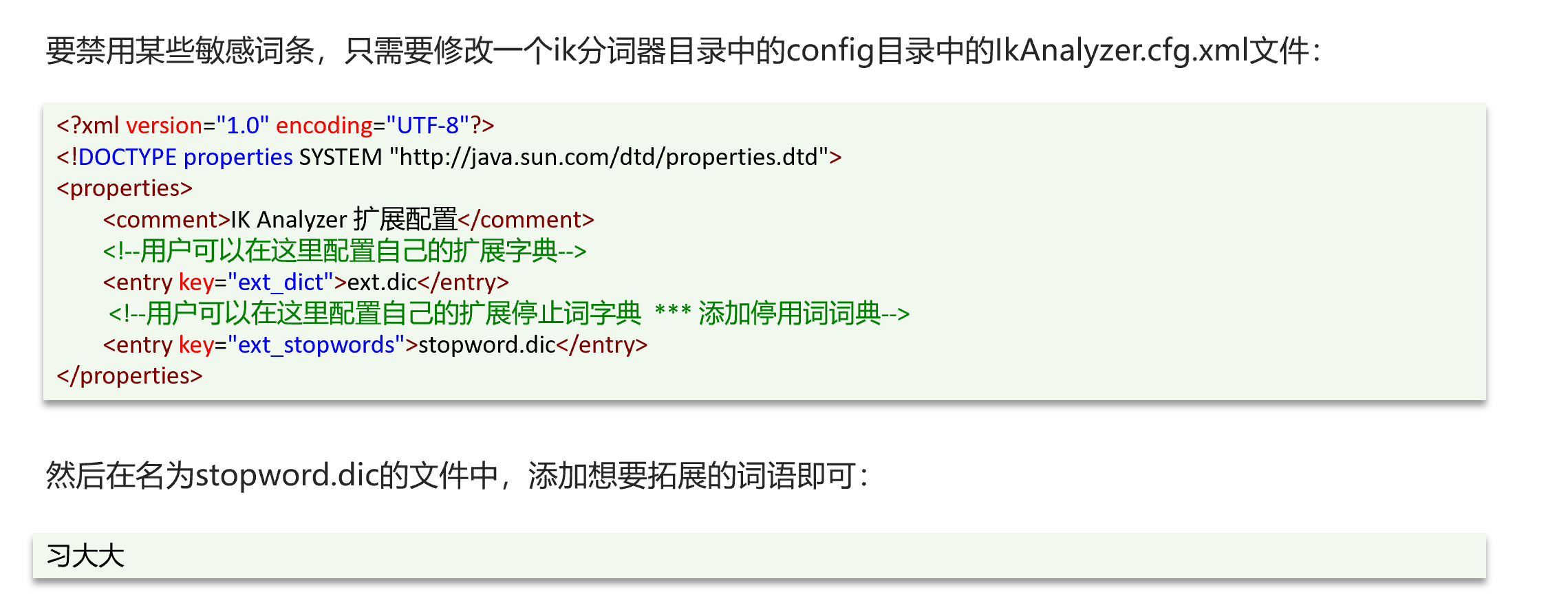
ik分词器-拓展词库

若有收获,就点个赞吧
0 人点赞
