一、默认方法
1,为什么使用默认方法
如果我们想在接口里面加入新的方法,那么之前写的所有接口的实现类全部都要加上新的实现,默认方法就是为了解决这个问题而产生的。
默认方法的加入是为了能够写出更容易改进的接口。
在java8之前,list接口中不存在sort方法,在java8中,list接口中有sort方法,default修饰。
2,默认方法是什么
默认方法就是接口里面可以有实现的方法,并且不需要实现类去实现其方法。并且默认方法允许你添加新的方法到现在的接口中,并且确保与旧版本的兼容性。
3,默认方法怎么用
默认方法就是在接口签名前面加入default关键字就是默认方法了。
4,例子
在接口中定义一个默认方法
实现类自动继承接口的默认方法,不用实现默认方法,可以直接调用
默认方法可以重写
实现多个接口的时候,且有相同方法的调用问题的解决
上面的代码中test实现的两个接口中都有sout()这个默认方法,此时两个方法都无效,test实现类必须要覆盖方法来解决冲突。
并且上面还有一个新特性,接口可以声明静态方法并且有方法实现。
Java 接口静态方法适合于提供实用方法,例如空检查、集合排序等。我们可以使用 java 接口静态方法来移除诸如集合之类的实用工具类,并将其所有静态方法移动到相应的接口,这样就很容易找到和使用。
补充
- Java类不可以多继承(菱形问题),接口可以多继承(不会引起菱形问题)
- 接口继承时,子接口如果继承了父接口的的默认方法,可以对其进行重写(也是用@Override注解)
- 接口继承中,静态方法不能被继承;类继承中,静态方法可以被继承。
- 接口继承和类继承中,静态变量都可以被继承。
- 接口间的继承中,普通的抽象方法都可以被继承。
二、函数式接口
1,函数式接口是什么
函数式接口是Java8引用的一个新特性,函数式接口的出现主要是为了配合Java8的另一个新特性Lamdba表达式来使用。
l 接口中只有一个抽象方法
l 接口上面可以加一个注解@FunctionalInterface来检查接口中的方法是不是只有一个抽象方法
l 在接口里面可以加入默认方法和静态方法
l 函数式接口也可以继承,但是继承的时候,抽象方法必须一样
l 函数式接口重写父类的方法,并不会计入到自己的抽象方法中(下图中,接口为什么可以重写Object类的方法)
2,函数式接口如何定义

3,函数式接口的简单实用

4,java8中四个核心函数式接口
上面我自定义的一个接口,就是一个消费类型的函数式接口。其实这类接口在java.util.function里面有定义的,就是void Consumer< T >,消费类型接口,上面代码中的test方法里面的接口其实可以换成Consumer< T >接口,也可以用,下面主要就是介绍这四个函数式接口的简单使用。
| 函数式接口 | 接口类型 | 参数类型 | 返回类型 | 用途 | 抽象方法 |
|---|---|---|---|---|---|
| Consumer |
消费类型接口 | T | void | 对类型为T的对象应用操作 | Void accept(T t) |
| Supplier |
供给类型接口 | 无 | T | 操作数据,返回T类型结果 | T get() |
| Function |
函数型接口 | T | R | 对I类型参数进行操作,并返回R类型结果 | R apply(T t) |
| Predicate |
断定型接口 | T | boolean | 确定T类型参数是否满足约束条件,并返回boolean值 | boolean test(T t) |
5. 核心函数式接口的使用

(1)Consumer的应用

Consumer的默认方法的源码:
其返回值这一句是重点,先是传入一个Consumer接口,然后返回一个Consumer接口,说明可以用表达式链,然后用这个特性可以把数据进一次进行加工。
(T t) -> { accept(t); after.accept(t); };这一句说明必须先实现抽象方法,然后才能调用默认方法。
(2)Supplier的应用

Supplier< T >接口类型就有一个方法签名。T get()方法,没有默认方法。
(3)Function的应用

addThen的源码:
compose的源码:
compose默认方法的执行顺序(andThen相反)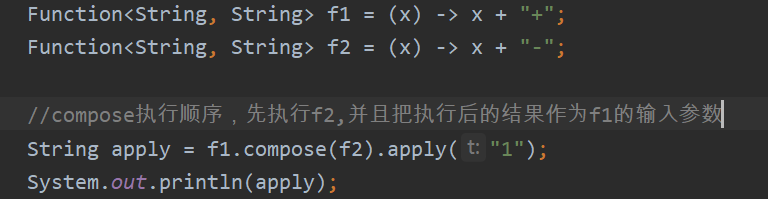
(4)Predicate的应用
Predicate是断言型接口
negate默认方法,取非
//输出 false

三、Lambda表达式
1,为什么要有Lambda表达式
Java8允许java中的方法和函数成为一等公民(可以在方法间传递),所以就应运而出现了Lambda表达式,他可以将表达式传递给另一个方法,然后再进行操作。
我们其实可以把Lambda表达式看作是匿名类的语法糖(简单写法),但是匿名类和Lambda表达式的现实方式一点都不一样。
2,Lambda表达式的书写方式
(1)lambda由3部分组成:
参数
->
代码片段
格式如下:
(参数类型 参数名)->{代码片段}
(2)lambda表达式的简写规则
l 小括号内的参数类型可以省略。
l 如果小括号内有且仅有一个参数,则小括号可以省略。
l 如果大括号内有且仅有一个语句,则无论是否有返回值,都可以省略大括号,return关键字及语句分号。
(3)Lambda表达式的一些使用案例
| 使用案例 | Lambda示例 |
|---|---|
| 布尔表达式 | (List |
| 创建对象 | ()->new Apple(10) |
| 消费一个对象 | (Apple a)->{System.out.println(a.getWeight())}; |
| 从一个对象中选取/抽取 | (String s)->s.length() |
| 组合两个值 | (int a, int b)->a*b |
| 比较两个对象 | (Apple a1, Apple a2)->a1.getWeight().compareTo(a2.getWeight()) |
3,Lambda表达式的使用
Lambda表达式的使用主要结合函数式接口使用的,当然如果普通的只要有一个方法的接口也可以用Lambda也可以用Lambda来书写。以前的只有一个接口方法也可以用。
Lamdba表达式是结合着函数式接口使用的。
函数式接口是结合着Steam()流来使用的。
四、方法引用
1,什么是方法引用
重复使用现有的方法定义,并像Lambda一样传递它们。
引用:就是让你跟据已有的方法来创建一个Lambda表达式。
使用方法引用,可读性更好,它的基本思想是,如果一个Lambda代表的只是“直接调用这个方法”,那好还是用名称来调用它,而不是去描述如何调用它。
2,方法引用的简单使用


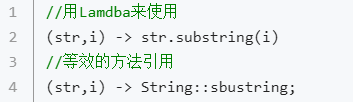

3,方法引用的构建
(1)指向静态方法的方法引用(Integer::parseInt)
(2)指向任意类型实例方法的方法引用(String::length)
(3)指向现有对象的实例方法的方法引用(自己定义的对象,传进lamdba表达式以后,就可以用方法引用了)
有参数的情况下,编译器会进行类型检查,来确定对于给定的函数式接口,这个方法引用是否有效,并且参数类型是否于上下文匹配。
4,使用方法引用来构建一个对象
在这里先定义一个javabean为Person,属性有两个name和sex,有一参构造方法,有两参构造方法和无参构造方法
l 用无参方法构建一个对象
l 用一个参数的构造方法来构建一个对象(使用方法引用的时候,最终调用apply的时候,才会根据参数明确到底用的是哪个方法)
l 用二个参数的构造方法来构建一个对象
BiFunction
T:第一个参数类型
U:第二个参数类型R:返回值类型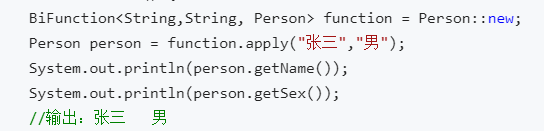
l 如果用多个参数来构建对象(三个或者三个以上)就必须自己写一个函数式接口
五、Steam API
1,为什么要加入流Stream()
集合是Java中使用最多的API,几乎每一个Java程序都会制造和处理集合。集合对于很多程序都是必须的,但是如果经常对一个集合进行,分组,排序,筛选,过滤…这些操作,会感到非常的难受,所以我们在连接数据库,处理数据时,数据能在sql中处理就在sql中处理,不能的才在java程序中处理,最后没有办法了才在页面中处理。
这个为什么呢?因为使用sql语句中处理数据,真的非常的简单。如果把数据取出来,在程序中用集合处理,用循环会非常的麻烦。所以java在Java8里面加入了Steam(),为了就是处理集合的时候,就像写sql语句一样简单。
2,流Stream()是什么
Stream流就是一种类似sql语句的方式来操作集合,可以以一种更加直观的方式对集合进行运算和表达式的高阶抽象。可以极大的提高效率,并且写出高质量的代码。
为什么说是流呢?
是因为它是把集合抽象成了一根管子内的水一样,可以进行过滤,处理,排序…等等操作。元素在经过中间操作以后,最后有终端操作来进行收集,可以变成你想要的任何类型的数据。比如:收集成 List,Set,Map,Array…
3,创建Stream流的几种方式
(1)通过Collection类的Stream()创建串行流,parallelStream()创建并行流,可以非常简单的利用多核资源
(2)通过数组创建流
可以使用静态方法Stream.of,通过显式值创建一个流。它可以接受任意数量的参数。
(3)创建一个空的流
(4)无限流
Stream API提供了两个静态方法来从函数生成流:Stream.iterate和Stream.generate。
这两个操作可以创建所谓的无限流:不像从固定集合创建的流那样有固定大小的流。由iterate 和generate产生的流会用给定的函数按需创建值,因此可以无穷无尽地计算下去!一般来说,应该使用limit(n)来对这种流加以限制,以避免打印无穷多个值。
4,中间操作:有状态操作(会改变原本的数据)
中间操作,就是把数据处理成自己想要的类型,并且有状态操作,是在所有的数据基础上进行操作的。比如dictinct(去重),sorted(排序)….
所有的有状态操作:
l 去重 distinct
l 跳过 skip
l 截断 limit
l 排序 sorted
(1)distinct方法
它会返回一个元素各异(根据流所生成元素的hashCode和equals方法实现)的流。
(2)limit(n)方法

(3)skip(n)方法
返回一个扔掉了前n个元素的流,如果流中的元素不足n个,则返回一个空流
//输出:c a abc d
(4)sorted()方法
使用的类型和函数式接口是Comparator
5,中间操作:无状态操作(不会改变原本的数据)
操作实例,以下所有方法基于此。


中间无状态操作,可以在单个对单个的数据进行处理。比如:filter(过滤)一个元素的时候,也可以判断,比如map(映射)…
所有的无状态中间操作
l 过滤 filter
l 映射 map
l 扁夹化 flatMap
l 遍厉 peek
(1)fileter方法
该操作会接受一个谓词(一个返回boolean的函数,例如Predicate接口)作为参数,并返回一个包含所有符合谓词的元素的流。
(2)map方法
它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素。
比如说,接收一个SKu类型的流,但是经过map以后,返回的是String的流。
不是构建一个Map类对象,只是将原来的item映射得到一个结果。
(3)flatmap方法
flatMap方法就是让你一个流中的每个值都换成另一个流,把所有的流都拼接成为一个流。
(4)peek方法
和终端操作一样,都是进行循环的。用的是peek方法,里面接收一个comsumer方法。这个方法最能体现无状态中间操作的。

6,终端操作:短路
传入一个谓词,返回传为boolean,如果符合条件,则直接结束流。
l 匹配所有 allMatch
l 任意匹配 anyMatch
l 不匹配 noneMatch
l 查找首个 findFirst
l 查找任意 findAny
(1)anyMatch方法
流中是否有一个元素能匹配给定的谓词,该方法返回一个boolean,因此是一个终端操作。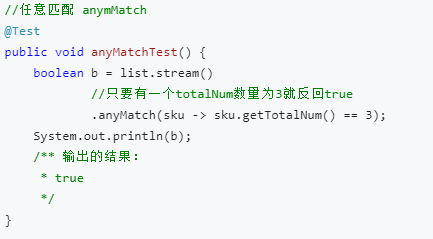
(2)allMatch方法

(3)noneMatch方法
和allMatch相对,可以确保流中没有任何元素与给定的谓词匹配。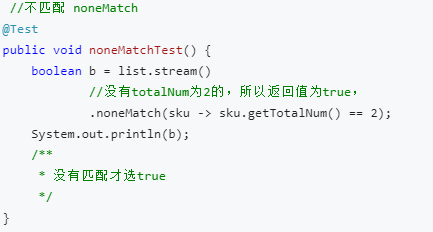
(4)findAny方法

(5)findFirst方法
有些流有一个出现顺序来指定流中项目出现的逻辑顺,这个方法的工作方式类似与findany。
(6)何时使用findFirst和findAny
你可能会想,为什么会同时有findFirst和findAny呢?答案是并行。找到第一个元素在并行上限制更多。如果你不关心返回的元素是哪个,请使用findAny,因为它在使用并行流时限制较少。
7,终端操作:非短路
非短路终端操作,就是所有的元素都遍厉完,直到最后才结束。用来收集成自己想要的数据。
l 遍厉 forEach
l 归约 reduce
l 最大值 max
l 最小值 min
l 聚合 collect
l 计数 count
(1)forEach方法

(2)max方法

(3)min方法

(4)count方法

(5)reduce方法
观察上面的max()、min()等方法,实际上都是将一组数据逐步取出削减,然后通过指定的运算以取得想要的结果,reduce()方法可以自定运算需求,max(),min()等流程也可以使用reduce()实现。
我们用reduce来实现从一组数据依条件求得一个数。
reduce接受两个参数:
l 一个是初始值
l 一个BinaryOperator
(6)collect方法
我们使用collect来实现将一组数据依据条件收集到另一个容器中。
比如我们可以使用Stream的collect()方法,来实现将一组人的男性收集到另一个list的需求:
//toList()是java.util.stream.Collectors的静态方法。
Collectors的toList()方法传回的并不是List,而是java.util.Stream.Collector实例。
Collector主要的四个方法是:
l suppiler():传回Suppiler,定义收集结果的新容器如何建立建立
l accumulator():传回BiConsumer,定义如何使用结果容器收集物件
l combiner():传回BinaryOperator,定义若有两个结果容器时,如何合并为一个结果容器
l finisher():传回Function,选择性地定义如何将结果转回为最后的结果容器
来看看Stream的collect()方法另一个版本,有助于了解Collector这几个方法如何使用,以下的程序片段与上面的collect()范例结果是相同的: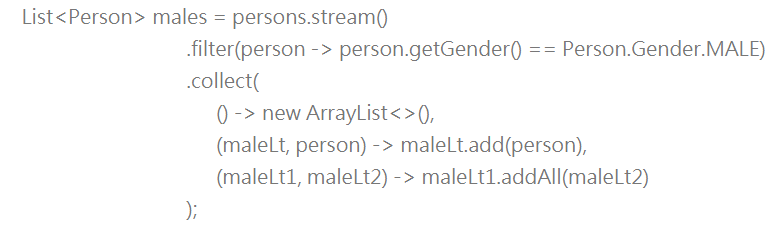
当collect()需要收集物件时,会使用第一个Lambda来取得容器物件,这相当于Collector的supplier()的作用,第二个Lambda定义了如何收集物件,也就是Collector的accumulator()的作用,在使用具有平行处理能力的Steam时,有可能会使用多个容器对原数据组进行分而治之,当每个小任务完成时,该如何合并,就是第三个Lambda要定义的。
上面的代码也可以写成:
当然,使用这个版本的collect()需要处理比较多的细节,举例来说,如果想要依性别分组,那可以使用Collectors的groupingBy()方法,告诉它要用哪个当作分组的键(Key),最后传回的Map结果会以List作为值(Value):
如果我们想在依性别分组后,取得分组下的姓名,那么可以写成: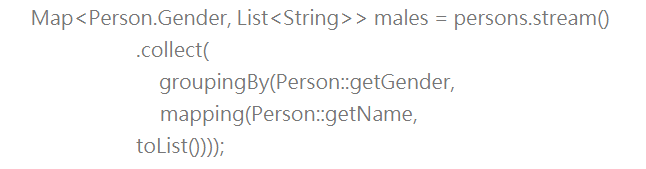
想在依性别分组之后,分别取得男女年龄总和,那么可以写成:
需要求得各性别下平均年龄的话,Collectors有个averagingInt()方法可以使用: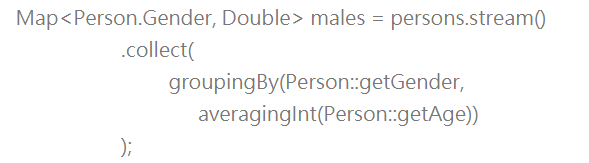
六、Optional类
1,为什么Optional类
Optional旨在减少代码中的NullPointerExceptions,虽然还不能完全消除这些异常。
它也是精心设计,自然融入Java 8函数式支持的功能。
总的来说,这个简单而强大的类有助于创建简单、可读性更强、比对应程序错误更少的程序。
我们从一个简单的用例开始。在Java 8之前,任何访问对象方法或属性的调用都可能导致NullPointerException:
在这个小示例中,如果我们需要确保不触发异常,就得在访问每一个值之前对其进行明确地检查:
这很容易就变得冗长,难以维护。
2,Optional类的简单使用
(1)创建Optional实例
of(),empty(),ofNullable()
这个类型的对象可能包含值,也可能为空。可以使用同名方法创建一个空的Optional。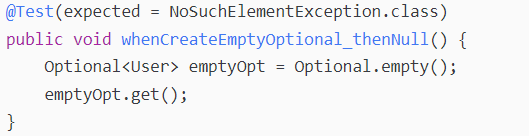
毫不奇怪,尝试访问emptyOpt变量的值会导致NoSuchElementException。
你可以使用of()和ofNullable()方法创建包含值的Optional。两个方法的不同之处在于如果你把null值作为参数传递进去,of()方法会抛出NullPointerException:
我们并没有完全摆脱NullPointerException。因此,应该明确对象不为null的时候使用of()。
如果对象即可能是null也可能是非null,就应该使用ofNullable()方法:
(2)访问Optional对象的值
get(), ifPresent()
从Optional实例中取回实际值对象的方法之一是使用get()方法:
这个方法会在值为null的时候抛出异常。要避免异常,你可以选择首先验证是否有值: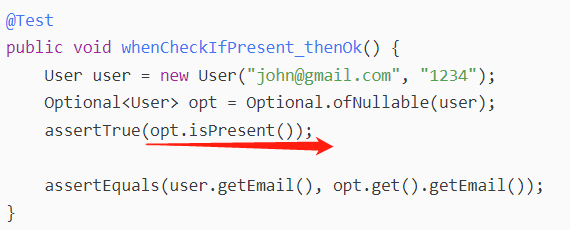
检查是否有值的另一个选择是ifPresent()方法。该方法除了执行检查,还接受一个Consumer(消费者)参数,如果对象不是空的,就对执行传入的Lambda表达式
只有 user 用户不为 null 的时候才会执行断言。
(3)返回默认值
orElse() orElseGet()
Optional类提供了API用以返回对象值,或者在对象为空的时候返回默认值。
l 第一个方法是orElse(),它的工作方式非常直接,如果有值则返回该值,否则返回传递给它的参数值。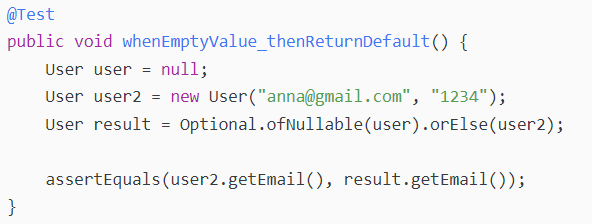
这里user对象是空的,所以返回了作为默认值的user2。
如果对象的初始值不是null,那么默认值会被忽略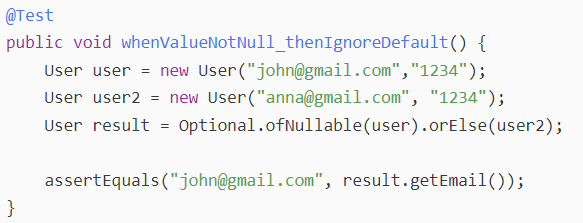
l 第二个同类型的API是orElseGet()—— 其行为略有不同。这个方法会在有值的时候返回值,如果没有值,它会执行作为参数传入的Supplier(供应者)函数式接口,并将返回其执行结果:
l orElse()和orElseGet()的不同之处
乍一看,这两种方法似乎起着同样的作用。然而事实并非如此。
当对象为空时,它们的行为:
上面的代码中,两种方法都调用createNewUser()方法,这个方法会记录一个消息并返回User对象。
代码输出如下:
由此可见,当对象为空而返回默认对象时,行为并无差异。
当Optional不为空,它们的行为: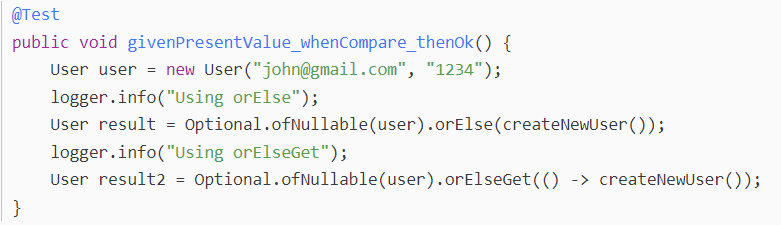
这次输出
这个示例中,两个Optional对象都包含非空值,两个方法都会返回对应的非空值。不过,orElse()方法仍然创建了User对象。与之相反,orElseGet()方法不创建User对象。
在执行较密集的调用时,比如调用 Web 服务或数据查询,这个差异会对性能产生重大影响。
(4)返回异常
orElseThrow()
Optional 还定义了orElseThrow()API —— 它会在对象为空的时候抛出异常,而不是返回备选的值。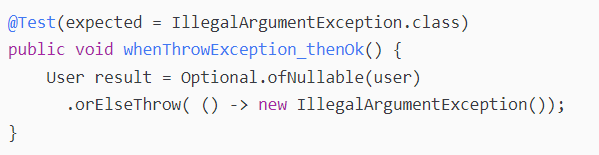
这里,如果user值为null,会抛出IllegalArgumentException。
这个方法让我们有更丰富的语义,可以决定抛出什么样的异常,而不总是抛出NullPointerException。
七、Date Time API
在Java8以前,Date日期API对我们非常的不友好,它无法表示日期,只能以毫秒的精试来表示时间,并且可以修改,他的线程还不是安全的。所以Java8中引入了全新的日期和时间API就是为了解决这一问题。
1,日期时间类
Java 8的日期和时间类包含LocalDateTime、LocalDate、LocalTime、Instant、Duration以及Period,这些类都包含在java.time包中,下面我们看看这些类的用法
(1)LoclDateTime
LocalDateTime类是LocalDate和LocalTime的结合体,可以通过of()方法直接创建,也可以调用LocalDate的atTime()方法或LocalTime的atDate()方法将LocalDate或LocalTime合并成一个LocalDateTime:
LocalDateTime``也提供用于向LocalDate和LocalTime的转化:
(2)LocalDate和LocalTime
LocalDate类表示一个具体的日期,但不包含具体时间,也不包含时区信息。可以通过LocalDate的静态方法of()创建一个实例,LocalDate也包含一些方法用来获取年份,月份,天,星期几等: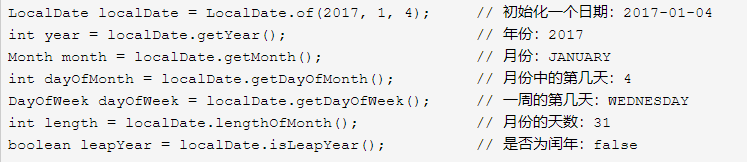
也可以调用静态方法now()来获取当前日期: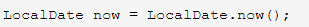
(3)Instant
Instant``用于表示一个时间戳,它与我们常使用的System.currentTimeMillis()有些类似,不过Instant可以精确到纳秒(Nano-Second),System.currentTimeMillis()方法只精确到毫秒(Milli-Second)。如果查看Instant源码,发现它的内部使用了两个常量,seconds表示从1970-01-01 00:00:00开始到现在的秒数,nanos表示纳秒部分(nanos的值不会超过999,999,999)。Instant除了使用now()方法创建外,还可以通过ofEpochSecond方法创建:
ofEpochSecond()方法的第一个参数为秒,第二个参数为纳秒,上面的代码表示从1970-01-01 00:00:00开始后两分钟的10万纳秒的时刻,控制台上的输出为:
(4)Duration
Duration的内部实现与Instant类似,也是包含两部分:seconds表示秒,nanos表示纳秒。两者的区别是Instant用于表示一个时间戳(或者说是一个时间点),而Duration表示一个时间段,所以Duration类中不包含now()静态方法。可以通过Duration.between()方法创建Duration对象:
Duration对象还可以通过of()方法创建,该方法接受一个时间段长度,和一个时间单位作为参数:
(5)Period
Period``在概念上和Duration类似,区别在于Period是以年月日来衡量一个时间段,比如2年3个月6天: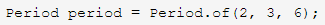
Period``对象也可以通过between()方法创建,值得注意的是,由于Period是以年月日衡量时间段,所以**between()方法只能接收LocalDate类型的参数**: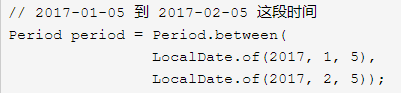
2,日期的操作和格式化
(1)增加和减少日期
Java 8``中的日期/时间类都是不可变的,这是为了保证线程安全。当然,新的日期/时间类也提供了方法用于创建对象的可变版本,比如增加一天或者减少一天: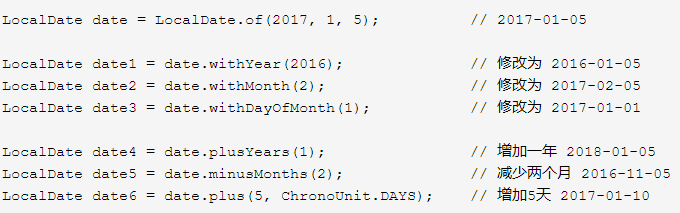
有些时候我们要面临更复杂的时间操作,比如将时间调到下一个工作日,或者是下个月的最后一天,这时候我们可以使用**with()**方法的另一个重载方法,它接收一个**TemporalAdjuster**参数,可以使我们更加灵活的调整日期:
**TemporalAdjusters**类中包含了很多静态方法可以直接使用,下面的表格列出了一些方法:
| 方法名 | 描述 |
|---|---|
| dayOfWeekInMonth | 返回同一个月中每周的第几天 |
| firstDayOfMonth | 返回当月的第一天 |
| firstDayOfNextMonth | 返回下月的第一天 |
| firstDayOfNextYear | 返回下一年的第一天 |
| firstDayOfYear | 返回本年的第一天 |
| firstInMonth | 返回同一个月中第一个星期几 |
| lastDayOfMonth | 返回当月的最后一天 |
| lastDayOfNextMonth | 返回下月的最后一天 |
| lastDayOfNextYear | 返回下一年的最后一天 |
| lastDayOfYear | 返回本年的最后一天 |
| lastInMonth | 返回同一个月中最后一个星期几 |
| next / previous | 返回后一个/前一个给定的星期几 |
| nextOrSame / previousOrSame | 返回后一个/前一个给定的星期几,如果这个值满足条件,直接返回 |
还可以创建自定义的TemporalAdjuster接口的实现,TemporalAdjuster也是一个函数式接口,所以我们可以使用Lambda表达式: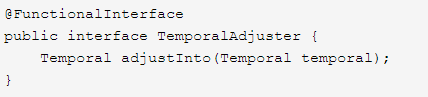
(2)格式化日期
新的日期API中提供了一个DateTimeFormatter类用于处理日期格式化操作,它被包含在java.time.format包中,Java 8的日期类有一个format()方法用于将日期格式化为字符串,该方法接收一个**DateTimeFormatter**类型参数:
同样,日期类也支持将一个字符串解析成一个日期对象,例如:
这个地方有个坑,java8中的DateTimeFormatter无法解析yyyyMMddHHmmssSSS格式的字符串日期,会报错,在jdk9里已修复,所以这里可以曲线救国,如果传入的是yyyyMMddHHmmssSSS格式的字符串,可以考虑自己转换为yyyyMMddHHmmss.SSS格式,这个格式是OK的。BUG详情见
https://bugs.java.com/bugdatabase/view_bug.do?bug_id=JDK-8031085
(3)时区
Java 8中的时区操作被很大程度上简化了,新的时区类java.time.ZoneId是原有的java.util.TimeZone类的替代品。ZoneId对象可以通过**ZoneId.of()**方法创建,也可以通过**ZoneId.systemDefault()**获取系统默认时区:
of()方法接收一个“区域/城市”的字符串作为参数,你可以通过**getAvailableZoneIds()**方法获取所有合法的“区域/城市”字符串:
对于老的时区类TimeZone,Java 8也提供了转化方法: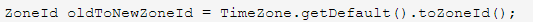
有了ZoneId,我们就可以将一个LocalDate、LocalTime或LocalDateTime对象转化为ZonedDateTime对象:
将zonedDateTime打印到控制台为:
2017-01-05T15:26:56.147+08:00[Asia/Shanghai]示例ZonedDateTime对象由两部分构成,LocalDateTime和ZoneId,其中2017-01-05T15:26:56.147部分为LocalDateTime,+08:00[Asia/Shanghai]部分为ZoneId。
另一种表示时区的方式是使用ZoneOffset,它是以当前时间和世界标准时间(**UTC)/格林威治时间(GMT)**的偏差来计算,例如:

若有收获,就点个赞吧
0 人点赞
