hashtable :对每个方法都加了Synchronized修饰
优点:不会有线程安全问题
缺点:Synchronized在多线程情况下会升级为重量级锁,涉及到用户态和内核态之间的转换,效率较低。
底层原理:hashtable会将整张表锁起来,无论是调用什么方法,都会先进入锁,才能够操作hashtable,。
concurrentHashmap
优点:不会出现线程安全问题,采用分布式锁,使其执行时降低了资源消耗。
缺点:暂无。
底层原理:
1.8版本之前:
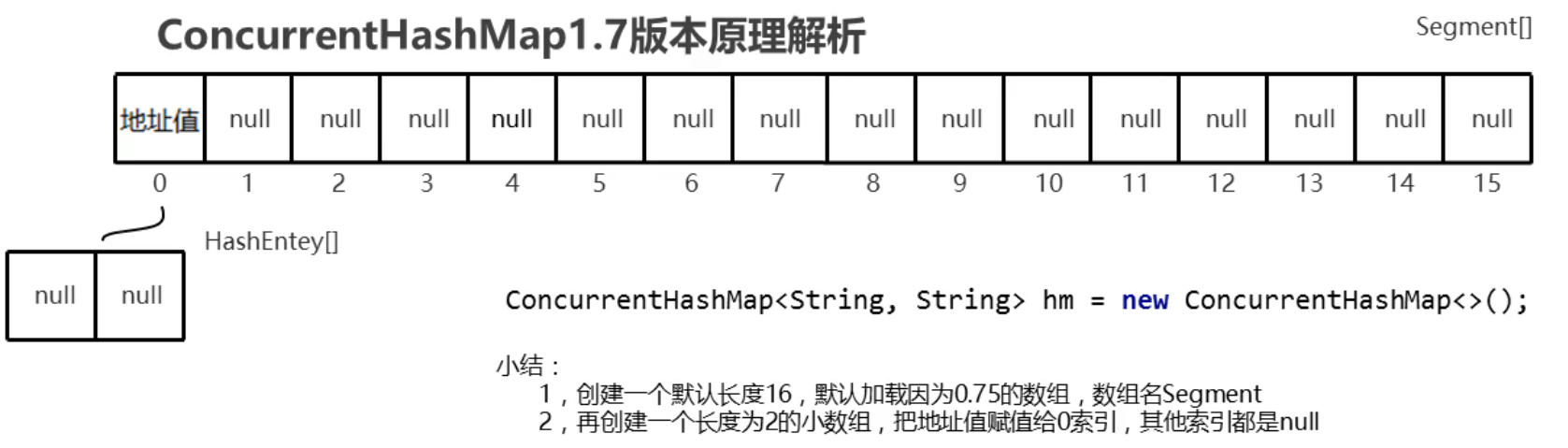
1.ConcurrentHashMap集合底层是一个默认长度为16,加载因子为0.75的大数组 Segment数组。这个大数组一旦创建无法扩容。后面的小数组可以扩容的。
2.默认情况下还会创建一个长度为2的小数组,把地址赋值给0索引处,其他索引此时的元素仍为null。
3.调用put方法时,此时会根据key的哈希值来计算出在大数组中存储的索引位置。
如果这个索引此时为null,则按照0素引的模板小数组来创建小数组。创建完毕后会二次哈希计算出key在小数组中存储的位置,然后把键值对对象存储小数组的该索引位。
如下图,先根据key的哈希算出来在大数组的4索引,创建小数组挂在4索引。接着继续使用key的hash算出存在小数组的0素引。
4.调用put方法时,此时会根据key的哈希值来计算出在大数组中存储的索引位置。
如果该位置不为null,就会根据记录的地址值找到小数组。二次哈希计算出小数组的索引位置。
如果需要扩容就把小数组扩容2倍。
如果不需要扩容,则会判断小数组该索引是否有元素
如果没有元素,就直接存
如果有元素,就调用equals方法比较key是否相同
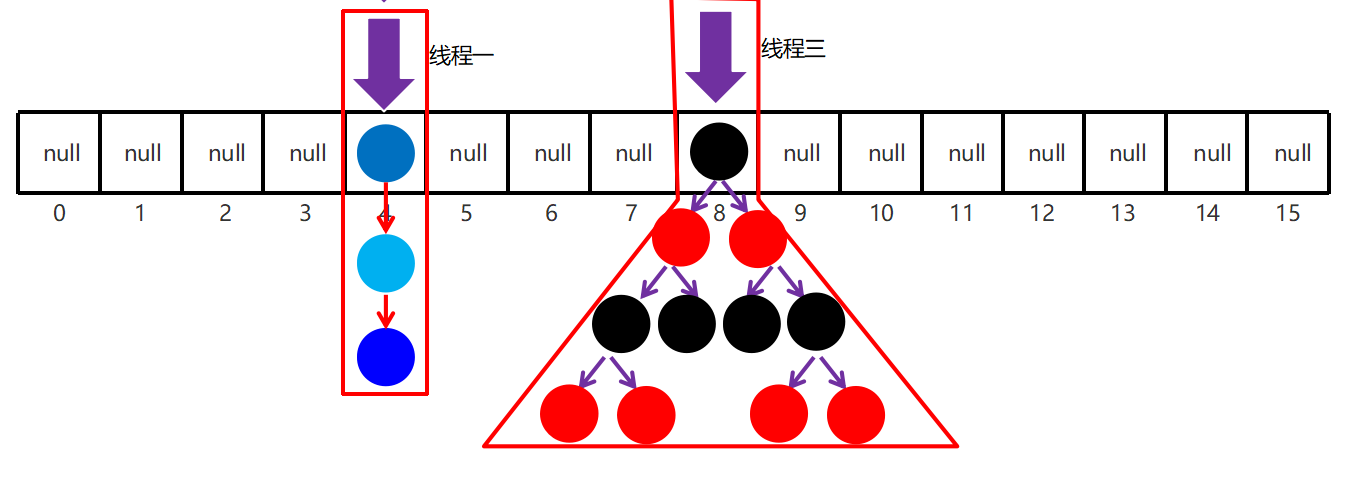
比较发现没有重复,就会在小数组上挂链表。
如下图
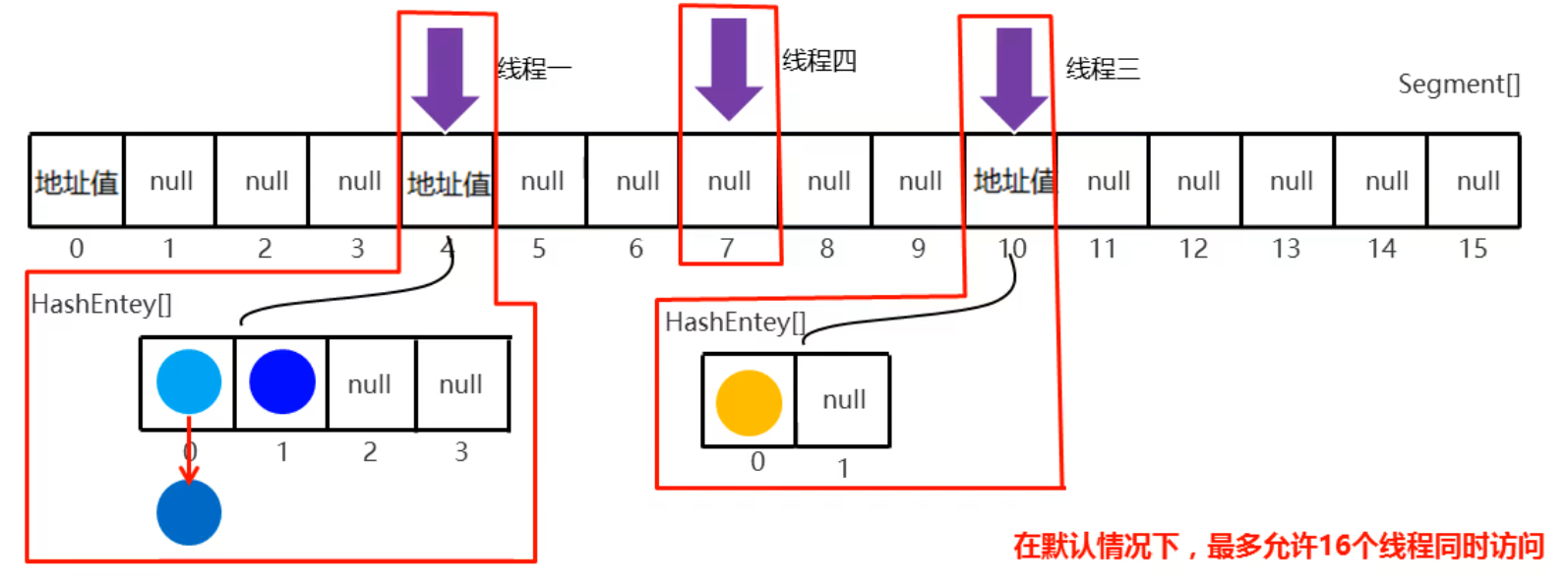
线程一来访问索引4,此时就会对索引4的Segment进行加锁。其他线程访问索引4就会阻塞,访问其他索引就可以访问,这种技术叫分段锁,将数据拆成一段一段的进行加锁。
长度默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。
关键字:分段锁、二次哈希、大数组不能扩容、小数组可以扩容
总结:
在JDK1.7中,ConcurrentHashMap基于Segment+HashEntry数组实现的。ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
ConcurrentHashMap优势就是采用了 锁分段技术, 每一个segment就好比一个自治区,读写操作高度自治,segment之间互不影响。可以说,ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
1.8 ConcurrentHashMap原理
底层结构:数组+链表+红黑树
CAS + synchronized同步代码块 保证线程安全

初始化数组
自旋+Cas+线程让出cpu自旋+Cas:初始化原子性,不会初始化多个数组。线程让出cpu:提高性能
put
1. 如果索引位置是null,CAS插入值2. 如果有值,synchronized加锁链表头结点。此索引位置的Node元素只能单线程访问。
扩容
多线程扩容步长cpu核心数


区别
1.7用的是segment+hashentry数组实现的分段锁。只要线程没同时访问同一个分段数组,就可以并行访问默认长度16,不可以扩容(大数组)。
1.8用的是CAS+synchronized+voletile 实现的,底层是数组+链表+红黑树。对比1.7 锁的粒度更细,锁到了节点级别。
为什么synchronized替换segment?我们就用ReentrantLock加锁不用synchronized?
ReentrantLock:park unpark 用户态 - 内核态 性能开销比较大。
synchronized:1.6之后优化了,偏向锁 轻量级锁 。此时加锁粒度非常小,比1.7小。转成重量级锁概率极小。

若有收获,就点个赞吧
0 人点赞
