基础姿势
- 标识符,命名规则如下:
- 第一个字符为字母或下划线
- 除第一个字符外的其他字符,可以使字母、下划线或数字。
- python中的数据类型,笔记如下:

- 运算符,相关笔记如下:
- 基本的数学运算符的优先级规律在python中基本上试用。
- 实在不清楚优先级规律,为需要先执行的运算加上括号。
- 缩进规律,相关笔记如下:
- 同一层次的代码,处于同一缩进幅度上,下一层次的代码,需要相对于上一层次的代码进行缩进,建议用TAB键缩进。
- print输出结果
- 输出中,需要将字符串与变量连接,加
,即可,如下图:
- 输出中,需要将字符串与变量连接,加

- 用 ` ,` 会显得略宽。
- 可以用
+,但连接的必须是字符串。print("Hello"+" "+str(a)),类似- 中断结构,指的是中途退出的一种结构,相关笔记如下:

函数
- 函数,的本质就是功能的封装。使用函数可大大提高编程效率与程序的可读性。
- 函数的定义与调用

函数的参数,是与外界沟通的接口。
为了程序实现起来更方便,按需求类别将一些常见的功能(函数)组合在一起,形成模块。
- 导入,的方法
- import 模块名
- from 模块名 import 方法
模块的类别(来源):
使用程序进行文件操作可以自动对文件进行处理,比如合并多个excel表格文件的内容等。

异常处理
- 注意格式和缩进。

面向对象编程
- OOP编程,类和对象。
- 类,具有某种特征的事物的集合(群体)
- 对象,群体(类)里面个体
- 类是抽象的,对象是具体的。

- 构造函数。初始化
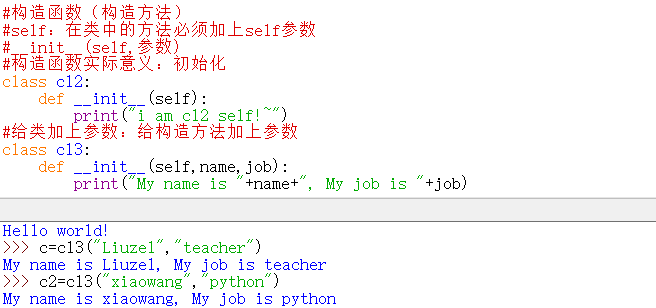
- 属性和方法
- 属性,静态的特征。如头发、手臂等
- 方法,动态的特征。如唱歌、写字等。

相关演示代码:c=cl4("xiaobai","python")c.mynamec.myjobc=cl5()c.myfunc1("xiaobai")c=cl6("xiaohei")c.myfunc1()
- 继承与重载
- 继承:把某一个或多个类(基类)的特征拿过来
- 重载:在子类(派生类)里面对继承过来的特征重新定义
- 父类:基类
- 子类:派生类。

查看模块功能以及如何安装模块
概述
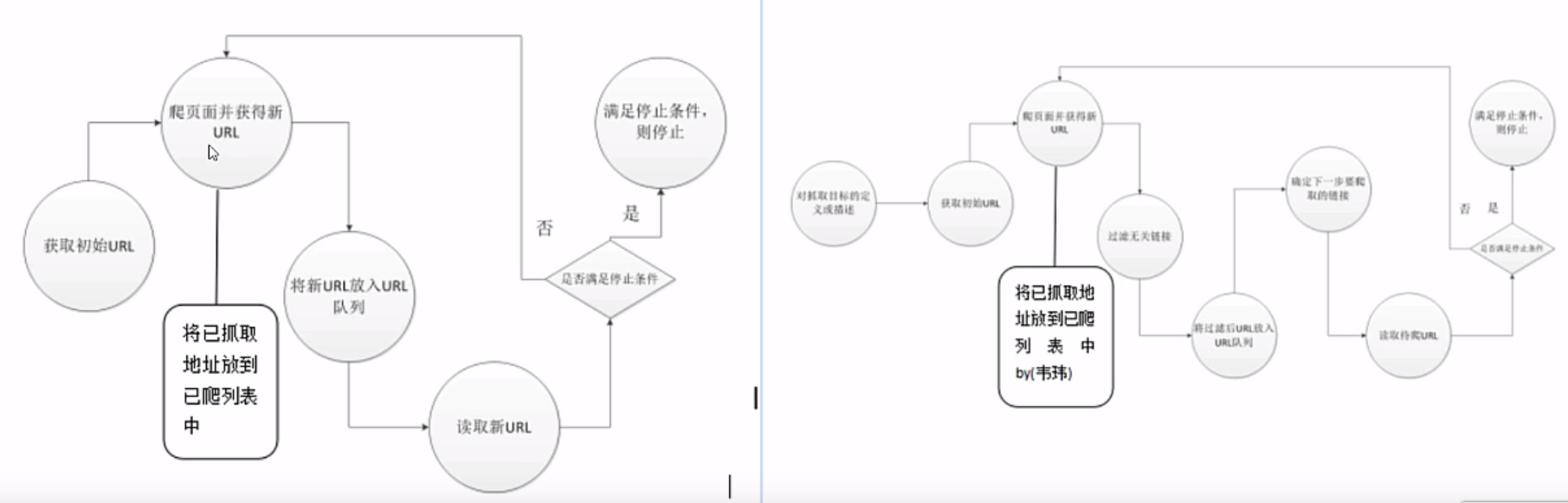
- 网络爬虫就是自动从互联网中定向或不定向地采集信息的一种程序。
- 常用的有通用网络爬虫(不定向)、聚焦网络爬虫(定向)。
- 通用与聚焦爬虫的运行原理:
- 正则表达式
- 原子是最基本的组成单位,每个正则表达式中至少包含一个原子。常见的原子类型有。相关笔记如下。
- 普通字符作为原子
- 非打印字符作为原子
- 通用字符作为原子
- 原子表
- 原子是最基本的组成单位,每个正则表达式中至少包含一个原子。常见的原子类型有。相关笔记如下。

- 元字符。就是正则表达式中具有一些特殊含义的字符,比如重复N次前面的字符等。

- 模式修正符。可以在不改变正则表达式的情况下,通过模式修正符改变正则表达式的含义,从而实现一些匹配结果的调整。

- 贪婪模式与懒惰模式。
- 贪婪模式核心点是尽可能多的匹配,而懒惰是尽可能少的匹配。

- 正则表达式函数。有,re.match() 函数,re.search() 函数,全局匹配函数,re.sub() 函数。

- 匹配 .com 或 .cn 网址,以及如何匹配电话号码。

- 直接使用urllib 库就可以。

- urllib模块,从urllib基础开始。urlretrieve(),urlcleanup(),info(),getcode(),geturl() 等。

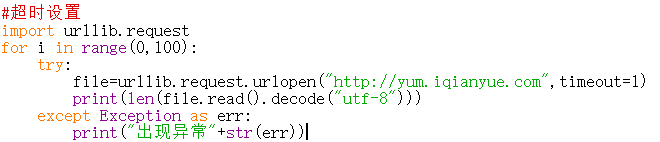
- 超时设置。有些网站服务器反应快,timeout的值就是2;有些反应慢,那么我们希望100秒没有反应,才判断为超时,此时timeout的值就是100。
- 自动模拟HTTP请求。指的是,客户端如果要与服务器端进行通信,需要通过http请求进行,下面有post与get请求方式。比如登录、搜索某些信息的时候会用。HTTP是无状态协议,无法记住你的状态。
- 有时爬虫结果会不准确,注意仔细检查。



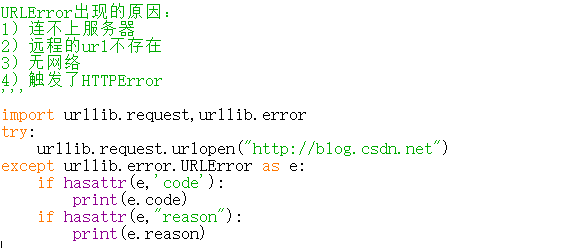
- URLError与HTTPError。HTTPError是URLError的子类,所以所有的都可以使用URLError。
- HTTPError有异常状态码与异常原因,URLError没有异常状态码。所以不能直接URLError代替HTTPError。代替前,必须判断是否有状态码属性。
- 格式都一样,只有中间的程序部分,需要有变动。
- 浏览器伪装技术。爬取网站时,返回403,因为对方服务器对爬虫进行屏蔽。因此需要伪装。一般通过报头来进行。F12-Network-All-随便点开一个Name-Headers-Request Headers 里面的User-Agent
- urlopen()不支持一些HTTP的高级功能。因此可以使用urllib.request.build_opener()进行。也可以用urllib.request.Request() 下面的add_header()实现浏览器的模拟。

-
小习题
输出乘法口诀表,代码如下:
#end="", 代表不换行输出for i in range(1,10):for j in range(1,i+1):print(str(j)+"*"+str(i)+"="+str(j*i),end=" ")print()
- 逆向输出的话,需要改步长,更改为
range(9,0,-1),range(i,0,-1)即可。 - 或者,
range(0,9),range(9-i,0,-1),(9-i)*j也是可以的。方法有很多。
- 使用python进行excel文档的合并
- 才用一些操作excel的模块去实现。如,xlrd,openpyxl,xlsxwriter。但是,在信息追加的时候回比较麻烦。思路如下。
- 换成其他模块,比如openpyxl等
- 仍使用xlwt与xlsxwriter等。将每次读取的信息存储到list(列表)中,最后一次写入。
- 才用一些操作excel的模块去实现。如,xlrd,openpyxl,xlsxwriter。但是,在信息追加的时候回比较麻烦。思路如下。
- 爬取豆瓣出版社列表并写入文件中。
- 首先,进行源码的分析。找到出版社名称的标签。

- 爬取官网的新闻的url地址。目前只能从list 里面获取6个。还需要改。参考
import urllib.requestimport redata=urllib.request.urlopen("http://www.baidu.com/artlist.asp?tag=news").read().decode("utf-8")print(len(data))#pat='<a href="view.asp?id=(.*?)"target="_blank">'pat='<a href="(.*?)" target="_blank">.*?></a>'rst=re.compile(pat,re.S|re.M).findall(data)print(len(rst))#print("http://www.baidu.com/"+str(rst[6]))#fh=open("F:/python-file/url-xw-sjpopc.txt","w")#for i in range(0,len(rst)):# print("http://www.baidu.com/"+str(rst[i]))# fh.write(rst[i]+'\n')#fh.close()

若有收获,就点个赞吧
0 人点赞
