参考内容:
lhs rhs是啥意思 《Javasript 高级程序设计(第三版)》 《你不知道的 JavaScript(上卷)》 JavaScript异步机制详解 维基百科:柯里化 函数记忆 JavaScript专题之函数柯里化
几乎所有的编程语言都能够存储变量当中的值,并且可以在之后对该值进行访问或修改。很明显需要一套良好的规则来存储这些变量,并且之后可以方便的找到这些变量,这套规则我们称之为作用域。
编译原理
我们一般把 js 归为「动态」或「解释执行」语言,但是它也会经历编译阶段,不过它不像传统语言那样是提前编译的,它的编译发生在代码执行前的几微秒内。
传统语言在执行之前会经历三个步骤:分词/词法分析、解析/语法分析、代码生成,关于这三个步骤的具体工作,可以查看编译原理相关的文献,我们可以把这三个步骤统称为编译。不过 js 引擎要复杂的多,它会在编译的时候对代码进行性能优化,尽管给 js 引擎优化的时间非常少,但是它用尽了各种办法来保证性能最佳。
我们需要先了解三个名词。引擎:从头到尾负责整个 js 程序的编译及执行过程;编译器:负责词法分析及代码生成;作用域:负责收集并维护由所有声明的标识符(变量)组成的一系列查询,并实施一套非常严格的规则,确定当前执行的代码对这些标识符的访问权限。var a = 2;,我们以这段程序为例,它首先声明了变量a,然后将2赋值给变量a。前一个阶段在编译器处理,后一个阶段由 js 引擎处理。
变量的赋值操作会执行两个动作,首先编译器会在当前作用域中声明一个变量(如果之前没有声明过),然后在运行时引擎会在作用域中查找该变量,如果能够找到就会对它赋值。
变量提升
用过 js 的人都知道 js 存在变量提升,那么它到底是如何提升的呢?我们看下面的一段代码
console.log(a);var a = 2;
上述代码在a声明之前访问了变量a,按我们的逻辑它应该会抛出 ReferenceError 异常;或是变量提升直接输出 2。但是这两种答案都不对,输出的是undefined。
回顾一下前文的关于编译的内容,引擎会在解释 js 代码之前对其进行编译,编译阶段的一个重要工作就是找到所有的声明,并用合适的作用域将它们关联起来,包括变量和函数在内的所有声明都会在任何代码被执行之前首先被处理。所以我们前面列出来的代码实际上会变成下面这个样子。
var a;console.log(a);a = 2;
这个过程就好像变量和函数声明会从它们的代码中出现的位置被移动到最上面一样,这个过程就是提升。但是需要注意的是,函数声明会首先被提升,然后才是变量提升。
foo(); // 1var foo;function foo() {console.info(1);}foo = function() {console.info(2);}
这段代码输出 1 而不是 2 ,它会被引擎理解为下面的形式。
function foo() {console.log(1);}foo(); // 1foo = function() {console.log(2);};
可以看到,虽然var foo出现在function foo()之前,但是它是重复的声明,因此会被忽略掉,因为函数函数声明会提升到普通变量前。所以在在同一个作用域中进行重复定义是一个很糟糕的做法,经常会导致各种奇怪的问题。
LHS 和 RHS 查询
LHS 和 RHS 是数学领域内的概念,意为等式左边和等式右边的意思,在我们现在的场景下就是赋值操作符的左侧和右侧。当变量出现在赋值操作符的左边时,就进行 LHS 查询;反之进行 RHS 查询。
RHS 查询与简单的查找某个变量的值没什么区别,它的意思是取得某某的值。而 LHS 查询则是试图找到变量容器的本身,从而可以对其进行赋值。console.info(a);我们深入研究一下这句代码。这里对a的引用是 RHS 引用,因为这里a并没有赋予任何值,相应的需要查找并取得a的值,这样才能传递给console.info()。a = 2;对a的引用则是一个 LHS 引用,因为实际上我们并关心a当前的值是什么,只是想为= 2这个赋值操作找到一个目标。
function foo(a) {console.info(a);}foo(2);
为了加深印象,我们再来分析一下上述代码中的 RHS 和 LHS 引用。最后一行foo()函数的调用需要对foo进行 RHS 引用。这里有一个很容易被忽略的细节,2 被当作参数传递给foo()函数时,2 会被分配给参数a,为了给参数a(隐式地)分配值,需要进行一次 LHS 查询,也就是说代码中隐含了a = 2的语句。
前文已经说过了console.info(a);会对a进行一次 RHS 查询,需要注意的是console.info()本身也需要一个引用才能执行,因此会对console对象进行 RHS 查询,并检查得到的值中是否有一个log方法。
为什么区分 LHS 和 RHS
我们考虑下面的一段代码,就可以为什么要区分 LHS 和 RHS 查询了,而且区分它们是分厂有必要的。
function foo(a) {console.info(a + b);b = a;}foo(2);
第一次对b进行 RHS 查询时是无法找到该变量的,这是一个未声明的变量,在任何相关的作用域中都无法找到它。如果 RHS 查询在所有嵌套作用域中都找不到该变量,引擎就会抛出 ReferenceError 异常。
引擎在执行 LHS 查询时,如果在全局作用域中也无法找到目标变量,全局作用域就会创建一个具有该名称的变量,并将其返还给引擎。
需要注意的是,在严格模式下是禁止自动或隐式地创建全局变量的,因此在严格模式中 LHS 查询失败时,引擎同样会抛出 ReferenceError 异常。 接下来,如果 RHS 查询找到了一个变量,但是你尝试对这个值进行不合理的操作,比如对一个非函数类型的值进行函数调用,那么引擎就会抛出另一种叫做 TypeError 的异常。
对象
Js 共有number、string、boolean、null、undefined、object六种主要类型,除了object的其它五中类型都属于基本类型,它们本身并不是对象。但是null有时会被当做对象处理,其原因在于不同的对象在底层都表示为二进制,在 js 中二进制前三位都为 0 的话就会被判定为object类型,而null的二进制表示全是 0, 所以使用typeof操作符会返回object。"I'm a string"本身是一个字面量,并且是一个不可变的值,如果要在这个字面量上执行一些操作,比如获取长度、访问某个字符等,那就需要将其转换为String类型,在必要的时候 js 会自动帮我们完成这种转换,也就是说我们并不需要用new String('I'm a string')来显示的创建一个对象。类似的像使用42.359.toFixed(2)时,引擎也会自动把数字转换为Number对象。null和undefined没有对应的构造形式,它们只有文字形式。相反,Date只有构造,没有文字形式。对于Object、Array、Function和RegExp(正则表达式)来说,无论使用文字形式还是构造形式,它们都是对象,不是字面量。
数组类型有一套更加结构化的值存储机制,但是要记住的是,数组也是对象,所以有趣的是你也可以给数组添加属性。
var myArray = ["foo", 42, "bar"];myArray.baz = "baz";myArray.length; // 3myArray.baz; // "baz"
安全的类型检查
Js 内置的类型检查机制并不是完全可靠的,比如在 Safari(第5版前),对正则表达式应用typeof操作符会返回function。像instanceof在存在多个全局作用域(包含 frame)的情况下,也会返回不可靠的结果。
我们可以使用toString()方法来达到安全类型检查的目的,在任何值上调用Object原生的toString()方法都会返回一个[object NativeConstructorName]格式的字符串,下面以检查数组为例。
Object.prototype.toString.call([]); // "[object Array]"function isArray(val) {return Object.prototype.toString.call(val) == "[object Array]";}
作用域安全的构造函数
构造函数其实就是一个使用new操作符调用的函数,当使用new操作符调用时,构造函数内用到的this对象会指向新创建的对象实例,比如我们有下面的构造函数。
function Person(name, age) {this.name = name;this.age = age;}
现在的问题在于,要是我们不使用new操作符呢?会发生什么!
let person = Person('name', 23);console.info(window.name); // nameconsole.info(window.age); // 23
很明显,这里污染了全局作用域,原因就在于没有使用new操作符调用构造函数,此时它就会被当作一个普通的函数被调用,this就被解析成了window对象。我们需要将构造函数修改为先确认this是否是正确类型的实例,如果不是则创建新的实例并返回。
function Person(name, age) {if (this instanceof Person) {this.name = name;this.age = age;} else {return new Person(name, age);}}
Js 如何实现异步
一个浏览器通常会常驻以下几个线程。渲染引擎线程负责页面的渲染;Js 引擎线程负责 js 的解析与执行;事件触发线程负责处理 DOM 事件;定时器触发线程负责处理定时事件。需要注意的是渲染线程和 Js 引擎线程是不能同时进行的,渲染引擎线程在执行时 js 引擎线程会被挂起,因为 js 可以操作 DOM,如果在渲染时 js 操作了 DOM,那么浏览器自己就会傻眼了。
此处所参考的文章说浏览器常驻的是线程,但是从任务管理器中可以看到,实际上是进程,chrome 基本上是打开一个页面会出现四个 chrome 进程 之所以说 js 是单线程的,那是因为浏览器在运行时只开启了一个 js 引擎线程,为什么不开两个呢?如果两个线程都去操作同一个 DOM,那么浏览器又傻眼了。 因此虽然 js 是单线程的,但是浏览器内部不是单线程的,异步操作都是由浏览器其它线程完成的。因此 js 是通过 js 引擎线程与浏览器中其它线程交互实现异步的。
消息队列与事件循环
如下图所示,左边的栈存储的是同步任务,就是那些能立即执行、不耗时的任务,如变量和函数的初始化、事件的绑定等等那些不需要回调函数的操作都可归为这一类。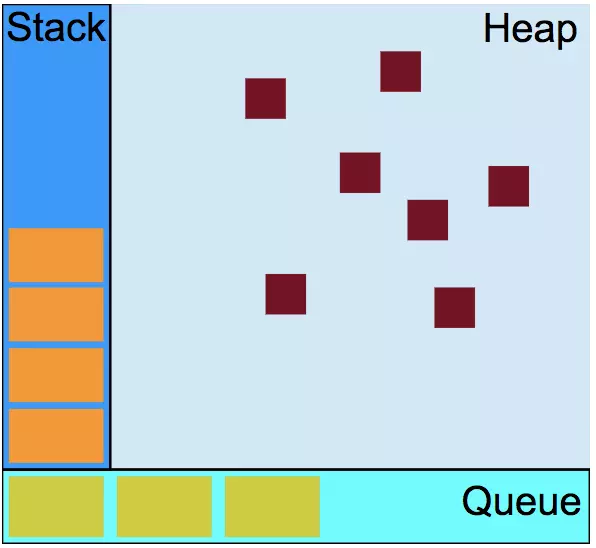
右边的堆用来存储声明的变量、对象。下面的队列就是消息队列,一旦某个异步任务有了响应就会被推入队列中。如用户的点击事件、浏览器收到服务的响应和setTimeout中待执行的事件,每个异步任务都和回调函数相关联。
JS引擎线程用来执行栈中的同步任务,当所有同步任务执行完毕后,栈被清空,然后读取消息队列中的一个待处理任务,并把相关回调函数压入栈中,单线程开始执行新的同步任务。
理解消息队列与事件循环
执行下面这段代码,执行后,在 5s 内点击两下,过一段时间(> 5s)后,再点击两下,整个过程的输出结果是什么?
setTimeout(function(){for(var i = 0; i < 100000000; i++){}console.log('timer a');}, 0)for(var j = 0; j < 5; j++){console.log(j);}setTimeout(function(){console.log('timer b');}, 0)function waitFiveSeconds(){var now = (new Date()).getTime();while(((new Date()).getTime() - now) < 5000){}console.log('finished waiting');}document.addEventListener('click', function(){console.log('click');})console.log('click begin');waitFiveSeconds();
首先,先执行同步任务。其中waitFiveSeconds是耗时操作,持续执行长达 5s。然后,在 js 引擎线程执行的时候,'timer a'对应的定时器产生的回调、'timer b'对应的定时器产生的回调和两次 click 对应的回调被先后放入消息队列。由于 js 引擎线程空闲后,会先查看是否有事件可执行,接着再处理其他异步任务,最后,5s 后的两次 click 事件被放入消息队列,由于此时 js 引擎线程空闲,便被立即执行了。因此会产生 下面的输出顺序。
01234click beginfinished waitingclickclicktimer atimer bclickclick
函数柯里化
在计算机科学中,柯里化是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。它是一门编译原理层面的技术,用途是实现多参函数。
// 假设我们现在需要实现一个如下功能的函数var result = sum(1)(2)(3);console.log(result);//6
下面的实现方式可以满足上面的要求,但是如果函数需要调用四次呢?
function add(a){var sum = 0;sum += a;return function(b){sum += b;return function(c){sum += c;return sum;}}}add(1)(2)(3);//6
下面是通过判断入参的长度来实现我们想要达到的效果,当然也可以重写toString()方法来达到匿名函数的效果,即不需要最后一个括号。
function add(a){var sum = 0;sum += a;return function temp(b) {if (arguments.length === 0) {return sum;} else {sum= sum+ b;return temp;}}}add(2)(3)(4)(5)(); //14
函数记忆
函数记忆是指将上次的计算结果缓存起来,当下次调用时,如果遇到相同的参数,就直接返回缓存中的数据。
function add(a, b) {return a + b;}// 假设 memoize 可以实现函数记忆var memoizedAdd = memoize(add);memoizedAdd(1, 2) // 3memoizedAdd(1, 2) // 相同的参数,第二次调用时,从缓存中取出数据,而非重新计算一次function memoize(f) {var cache = {};return function(){var key = arguments.length + Array.prototype.join.call(arguments, ",");if (key in cache) {return cache[key]}else {return cache[key] = f.apply(this, arguments)}}}

若有收获,就点个赞吧
0 人点赞
