
传统流计算系统针对于状态的一些问题
由于我们是流处理所以我们需要把状态数据很好的管理起来 — 之前我们使用Storm 与 HBase 将状态给维护起来,用的时候把数据拿出来 更新后 再放回去。 —- 问题:我们节点有可能不在一起,网络消耗很影响性能,我们需要走远端的程序访问 存储 与更新 再写入等 而且想做到备份与恢复是很难的 。 像HBase 是没有什么回滚的,想做到Exactly-once 是很难的

针对于状态提供了
- 多种数据类型
- 多种划分方式
- 多种后端存储格式
- 高效的备份与恢复
Flink.支持类型
- keyed State
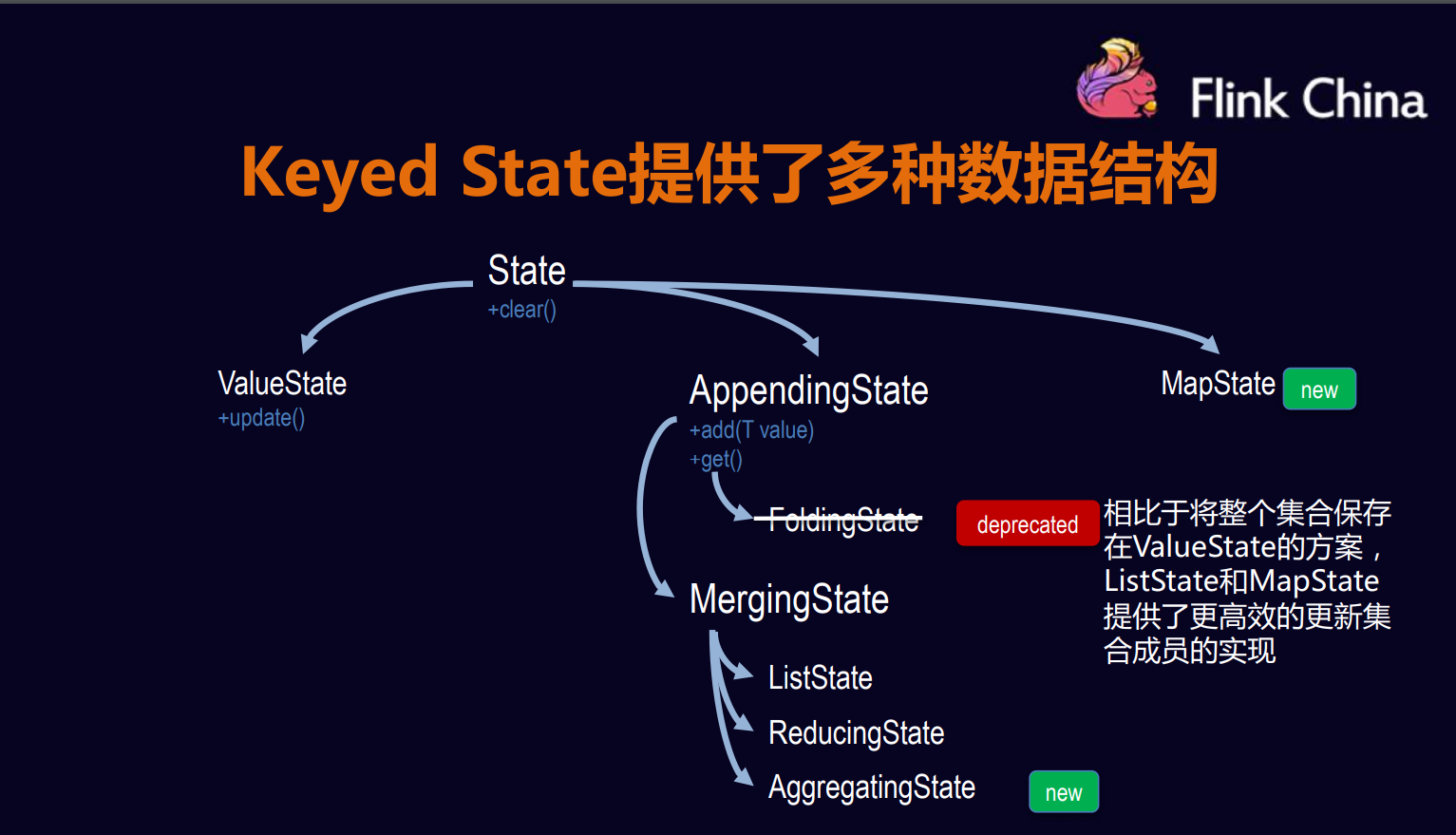
- Operator State 目前只支持ListState
Flink.动态扩展
Keyed State使用

Keyed State 动态扩容

**
- Key 取 Hash 模 最大并发数
—— — —- —— ——
Operator State 使用

Operator 动态扩容
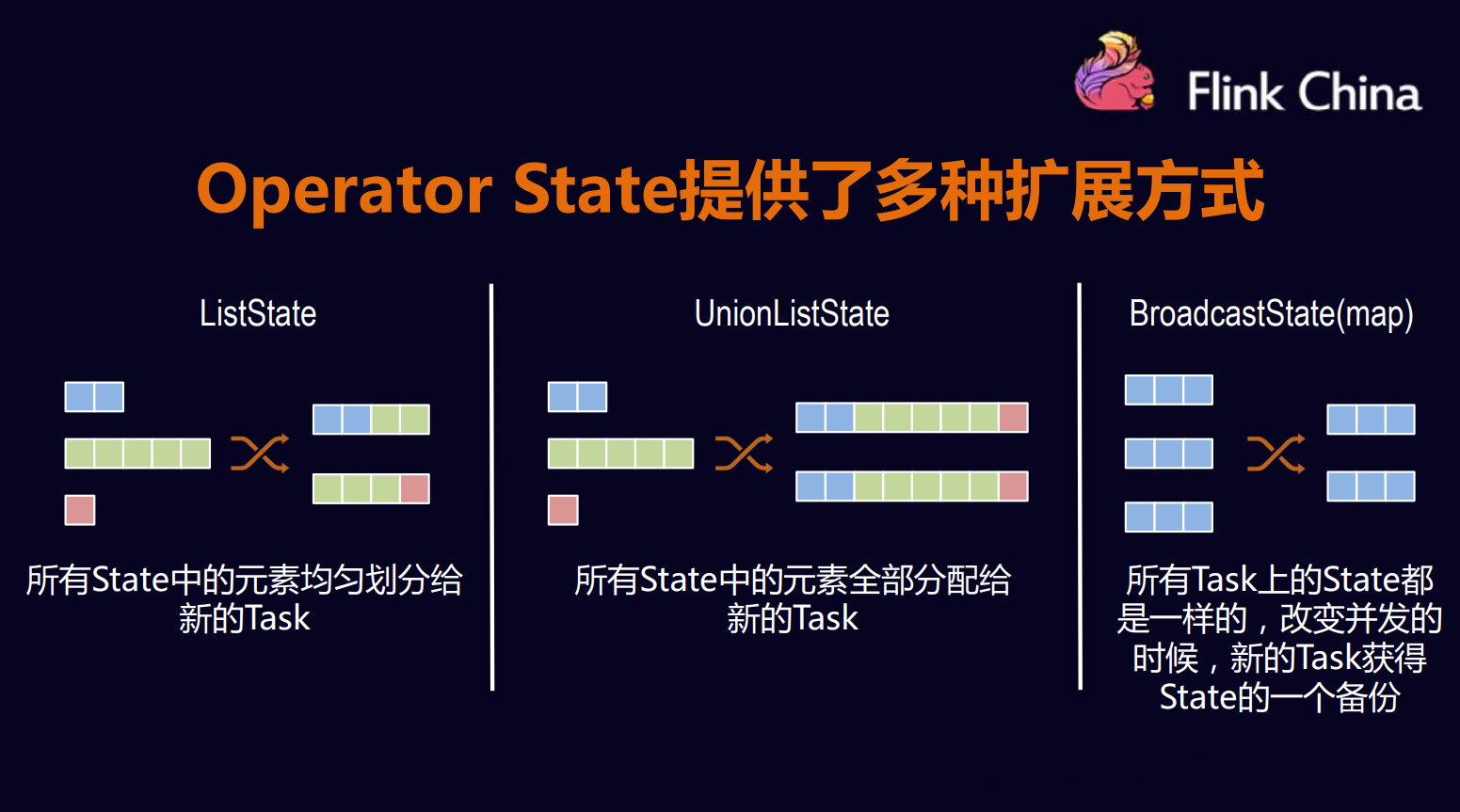
- List State 将所有的State 合并起来后 除Task 数量
- UnionListState 将所有的State合并起来后 交给用户自定义分配
- BroadCast State 将数据作为State广播出去后每个节点保存一份
Flink.正确性保证语义
- AT LEAST ONCE 所有数据至少被处理一次,在状态恢复时有可能导致数据重复消费
- EXACTLY ONCE 所有的数据正好一次,无论发生异常
至于对齐不对齐请看下方文档
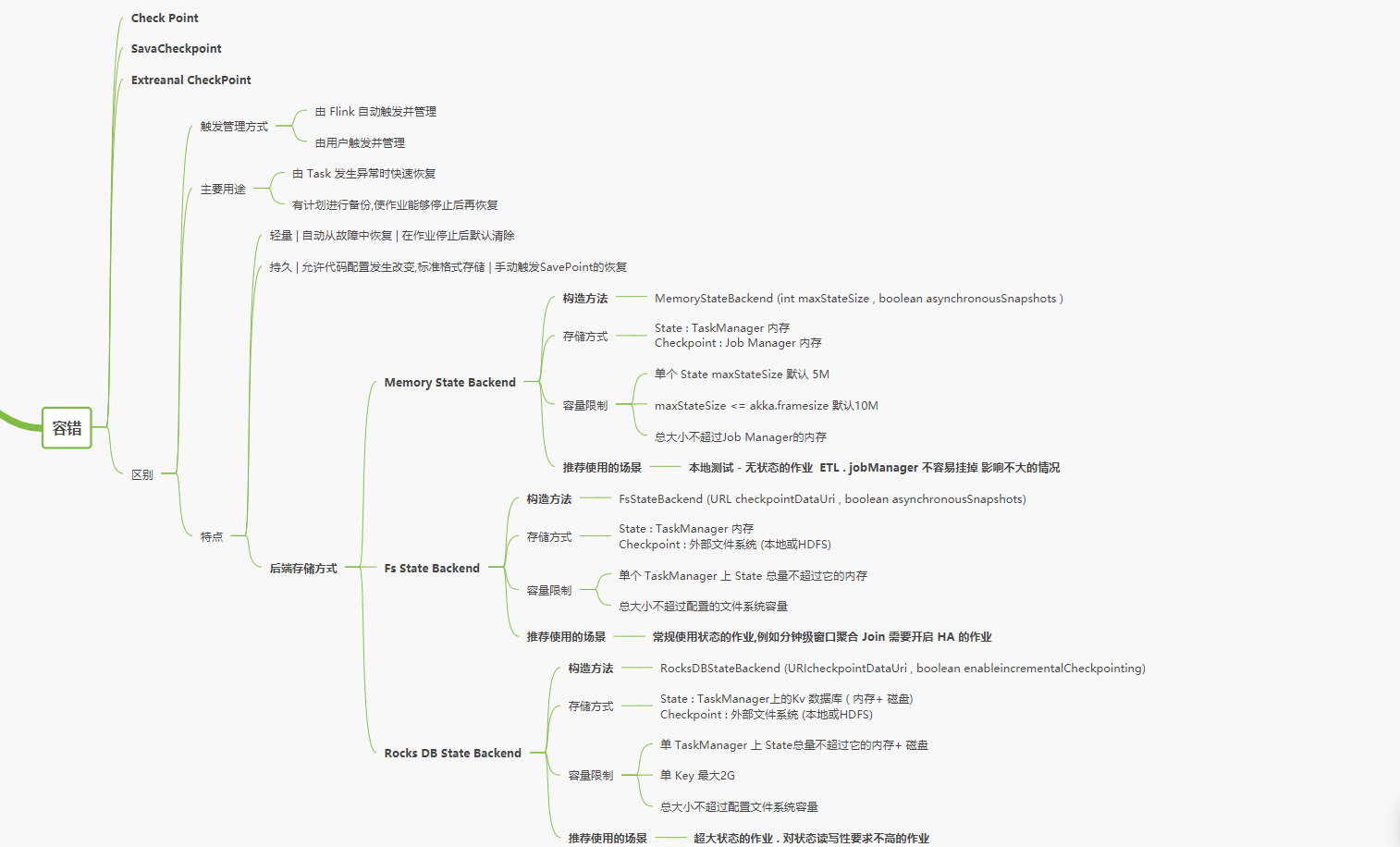
Flink.备份与恢复
把程序的状态放在内存中,然后再做Checkpoint到时候再交给Flink,由Flink来帮你做备份与恢复
那么首先需要继承 ListCheckpoint 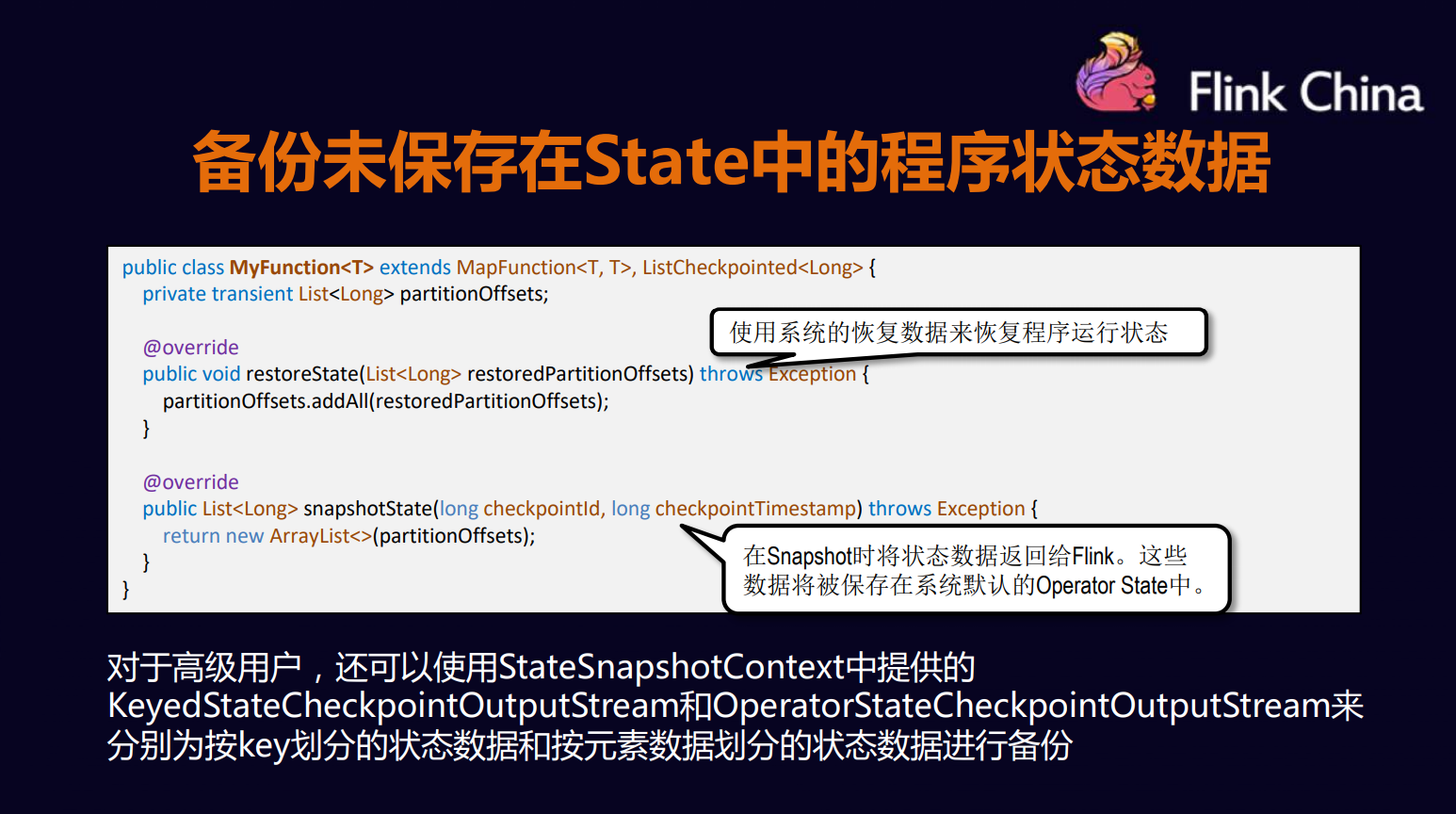
对于写Operator 的用户还可以使用KeyedStateCheckPointOutputStream OperatorStateCheckPointOutputStream
从停止作业的运行状态中恢复
- SavePoint
- Extreanal CheckPoint

- 当作业FAILED 或者 CANCELLED时,内部的CheckPoint已经停止了但外部的CheckPoint会被保存下来
Flink.State与CheckPoint数据的存储方式

- HeapKeyedStateBackend (有点类似于 多个嵌套的Map组成的)
- RocksDBKeyedStateBackend (每个State存储在单独的一个ColumnFamily中)

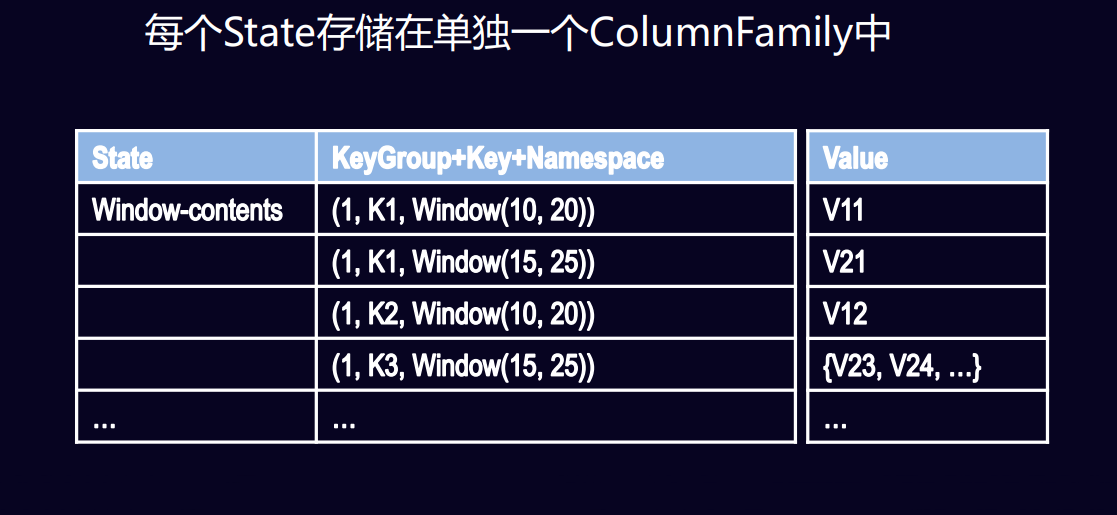
CheckPoint
- CheckPoint 执行流程

- 关键字
- CheckPoint Coordinator
- CheckPoint Trigger
- CheckPoint Barrier
- CheckPoint State handle
- Complted CheckPoint Mate
- CheckPoint Barrier 对齐
略
- 全量的CheckPoint
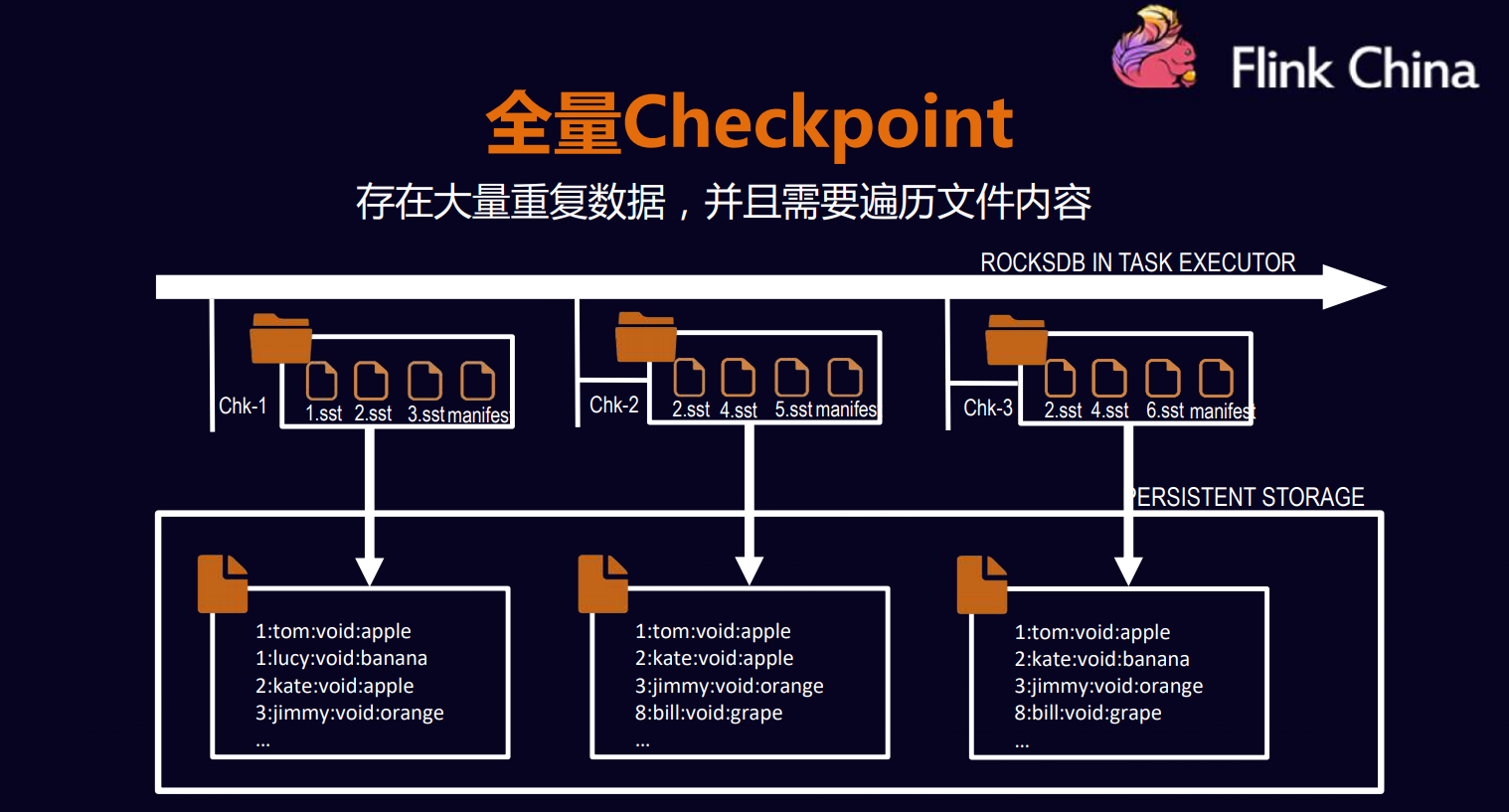
**
- 增量的CheckPoint

- JobManager的增量CheckPoint管理 (增删操作)

施晓罡
视频地址

若有收获,就点个赞吧
0 人点赞
