单选址问题
比较了1)迭代法,2)重心法和3)one-median法的差异。总体而言从加权距离最小的角度看,迭代法选出来的结果最好。当网点和网点的单量呈现偏态分布时,one-median的结果更好,当网点和网点的单量呈现呈现随机分布时,重心法和one-median没有明显的差异。
参考链接:https://wiki.mbalib.com/zh-tw/%E9%87%8D%E5%BF%83%E6%B3%95
代码
import numpy as npimport pandas as pdimport randomimport math as mimport matplotlibimport matplotlib.pyplot as pltimport matplotlib.font_manager as fmplt.rcParams['font.sans-serif'] = [u'SimHei']"""单选址问题比较了1)迭代法,2)重心法和3)one-median法的差异。总体而言从加权距离最小的角度看,迭代法选出来的结果最好。当网点和网点的单量呈现偏态分布时,one-median的结果更好,当网点和网点的单量呈现呈现随机分布时,重心法和one-median没有明显的差异。参考链接:https://wiki.mbalib.com/zh-tw/%E9%87%8D%E5%BF%83%E6%B3%95"""class Weight:def __init__(self):passdef generate_data_handle(self):# 生成数据x_list = [6, 4, 1, 9, 3]y_list = [7, 2, 6, 3, 10]w_list = [8000, 7000, 5000, 4000, 6000]cost_list = [1, 1, 1, 1, 1]data = pd.DataFrame({'x': x_list, 'y':y_list, 'w': w_list, 'cost': cost_list})data['w'] = data['w'] * data['cost']data['w^2'] = data['w'] * data['w']self.data = datadef generate_data_random(self, batch_size=20, p_lb=0, p_ub=100):# 生成数据y_list = [random.randint(60, 110) for i in range(batch_size)]x_list = [random.randint(20, 50) for i in range(batch_size)]w_list = [random.randint(10, 100)*x_list[i] for i in range(batch_size)]cost_list = [1 for i in range(batch_size)]data = pd.DataFrame({'x': x_list, 'y': y_list, 'w': w_list, 'cost': cost_list})data['w'] = data['w'] * data['cost']data['w^2'] = data['w'] * data['w']self.data = datadef generate_data_skewness(self, batch_size=20, p_lb=0, p_ub=100):# 生成数据y_list = [random.randint(60, 110) for i in range(2*batch_size)]y_list.extend([random.randint(80, 110) for i in range(2*batch_size)])x_list = [random.randint(20, 50) for i in range(2*batch_size)]x_list.extend([random.randint(40, 50) for i in range(2*batch_size)])w_list = [random.randint(10, 100)*x_list[i] for i in range(4*batch_size)]cost_list = [1 for i in range(4*batch_size)]data = pd.DataFrame({'x': x_list, 'y': y_list, 'w': w_list, 'cost': cost_list})data['w'] = data['w'] * data['cost']data['w^2'] = data['w'] * data['w']self.data = datadef compute_node_weight(self, data, weight_col_name, d_j):# 普通重心法:加权均值:(x0, y0)WC = np.array(data[weight_col_name])WC_j = WC / d_jWCX = ((np.array(data['x']) * WC)/d_j).sum()WCY = ((np.array(data['y']) * WC)/d_j).sum()x = WCX / WC_j.sum()y = WCY / WC_j.sum()d_j = ((np.array(data['x']) - x) ** 2 + (np.array(data['y']) - y) ** 2) ** 0.5transportation_cost = (np.array(data['w']) * d_j).sum()return x, y, d_j, transportation_costdef run(self, iter_num=10):# one - median法: 加权平方均值x2, y2, d_j, transportation_cost2 = self.compute_node_weight(self.data, 'w^2', 1)print('加权平方重心选点大致位置:({},{}), 总运输费用:{}'.format(x2, y2, transportation_cost2))# 加权均值x0, y0, d_j, transportation_cost0 = self.compute_node_weight(self.data, 'w', 1)print('重心法选点大致位置:({},{}), 总运输费用:{}'.format(x0, y0, transportation_cost0))self.p0 = [x0, y0, transportation_cost0]self.p2 = [x2, y2, transportation_cost2]min_transportation_cost = transportation_cost0result_list = [[x0, y0, transportation_cost0, 0]]for i in range(iter_num):x, y, d_j, transportation_cost = self.compute_node_weight(self.data, 'w', d_j)result_list.append([x, y, transportation_cost, i+1])print('经{}次迭代后选址点位置:({},{}), 总运输费用:{}'.format(i + 1, x, y, transportation_cost))if min_transportation_cost - transportation_cost < 1:breakmin_transportation_cost = transportation_costself.result = result_listdef plot_figure(self):# 初始化函数用于绘制一块干净的画布,为后续绘图做准备result = self.resultp0, p2 = self.p0, self.p2scatter_size = 200 # [200, 200, 200, 200, 200, 200]# 生成画布# plt.figure(figsize=(6, 6), dpi=80)plt.subplot(1, 2, 1)# 打开交互模式plt.ion()for step in range(len(result)):# 清除原有图像plt.cla()position = result[step]plt.scatter(self.data['x'], self.data['y'], scatter_size, c='pink', marker='*', alpha=0.7, label='配送点')plt.scatter(p0[0], p0[1], scatter_size, c='blue', marker='p', alpha=0.7, label='加权重心')plt.scatter(p2[0], p2[1], scatter_size, c='green', marker='p', alpha=0.7, label='加权平方重心')plt.scatter(position[0], position[1], scatter_size, c='red', marker='p', alpha=0.7, label='选址点')plt.xlabel('纬度', fontsize=11)plt.ylabel('经度', fontsize=11)plt.grid(True)# plt.text(1,3,'总费用{}'.format(T),fontsize=16)plt.title('重心法选址,第{}次结果示意图'.format(step + 1), fontsize=14)# plt.title('重心法选址结果示意图', fontsize=14)plt.legend(loc='lower left')plt.pause(0.2)# 关闭交互模式plt.ioff()# 图形显示# plt.show()def plot_iteration(self):result = self.resultp0, p2 = self.p0, self.p2iter_num = len(result)# 生成画布# plt.figure(figsize=(6, 6), dpi=80)plt.subplot(1, 2, 2)plt.plot([0, iter_num-1], [p0[2], p0[2]], c='blue', label='加权重心')plt.plot([0, iter_num-1], [p2[2], p2[2]], c='green', label='加权平方重心')plt.plot([i for i in range(iter_num)], [p[2] for p in result], c='red', label='重心法')plt.xlabel('迭代次数', fontsize=11)plt.ylabel('总运输成本', fontsize=11)plt.grid(True)plt.title('重心法选址结果示意图', fontsize=14)plt.legend(loc='lower left')plt.show()def plot_figure_subplot(self):# 初始化函数用于绘制一块干净的画布,为后续绘图做准备result = self.resultp0, p2 = self.p0, self.p2scatter_size = 200 # [200, 200, 200, 200, 200, 200]iter_num = len(result)# 生成画布plt.figure(figsize=(10, 6), dpi=80)plt.subplot(1, 2, 1)# 打开交互模式plt.ion()for step in range(len(result)):# 清除原有图像plt.cla()position = result[step]plt.scatter(self.data['x'], self.data['y'], scatter_size, c='pink', marker='*', alpha=0.7, label='配送点')plt.scatter(p0[0], p0[1], scatter_size, c='blue', marker='p', alpha=0.7, label='重心法')plt.scatter(p2[0], p2[1], scatter_size, c='green', marker='p', alpha=0.7, label='one-median')plt.scatter(position[0], position[1], scatter_size, c='red', marker='p', alpha=0.7, label='迭代法选址点')plt.xlabel('纬度', fontsize=11)plt.ylabel('经度', fontsize=11)plt.grid(True)# plt.text(1,3,'总费用{}'.format(T),fontsize=16)plt.title('重心法选址,第{}次结果示意图'.format(step + 1), fontsize=14)# plt.title('重心法选址结果示意图', fontsize=14)plt.legend(loc='lower left')plt.pause(0.2)# 关闭交互模式plt.ioff()plt.subplot(1, 2, 2)plt.plot([0, iter_num-1], [p0[2], p0[2]], c='blue', label='重心法')plt.plot([0, iter_num-1], [p2[2], p2[2]], c='green', label='one-median')plt.plot([i for i in range(iter_num)], [p[2] for p in result], c='red', label='迭代法选址点')plt.xlabel('迭代次数', fontsize=11)plt.ylabel('总运输成本', fontsize=11)plt.grid(True)plt.title('重心法选址结果示意图', fontsize=14)plt.legend(loc='lower left')plt.show()if __name__ == "__main__":weight_compare = Weight()# 生成小测试算例# weight_compare.generate_data_handle()# 生成随机数# weight_compare.generate_data_random(batch_size=30, p_lb=0, p_ub=100)# 生成偏态分布weight_compare.generate_data_skewness(batch_size=20)weight_compare.run(iter_num=50)# weight_compare.plot_iteration()# weight_compare.plot_figure()weight_compare.plot_figure_subplot()
结果展示
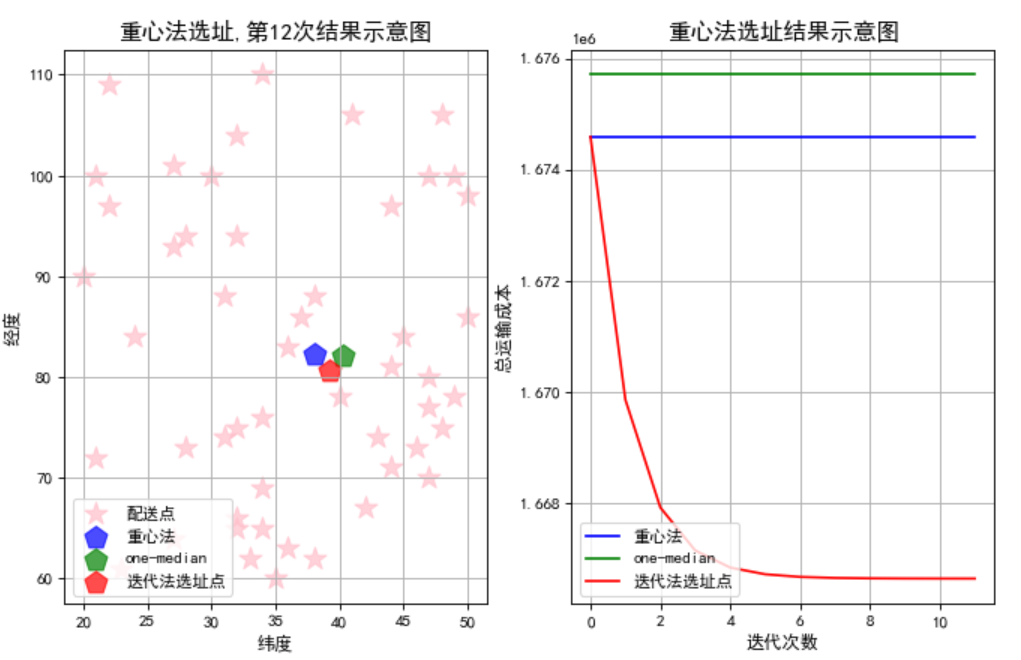
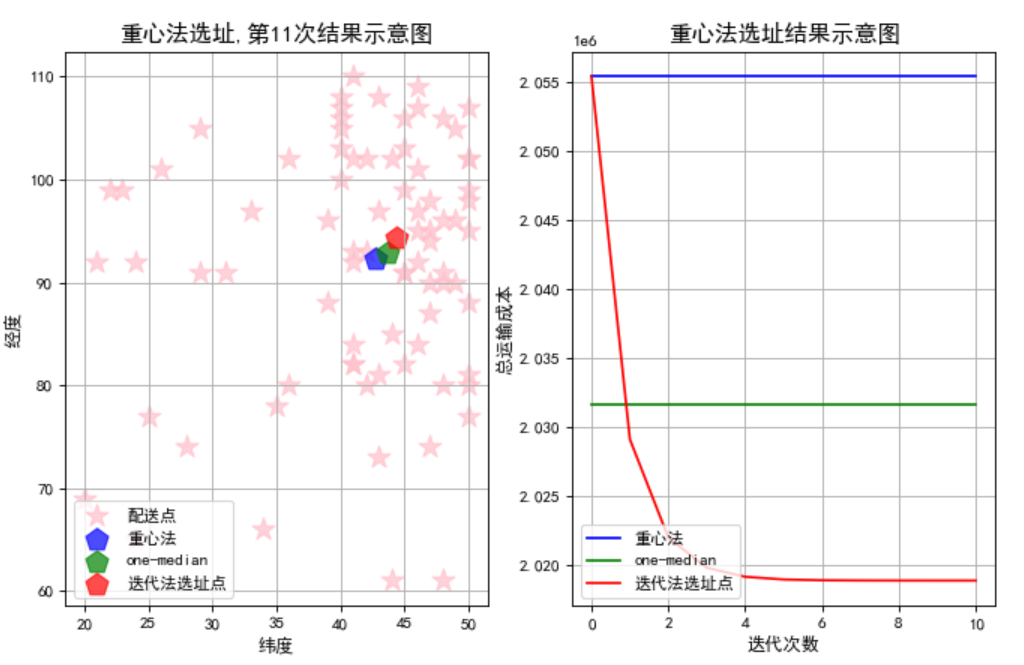
数据为随机分布的结果 数据为偏态分布的结果
注:应该重负做100次试验,比较成本的统计结果

若有收获,就点个赞吧
0 人点赞
