什么是disruptor?
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。
基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。
目前,包括Apache Storm、Camel、Log4j 2在内的很多知名项目都应用了Disruptor以获取高性能。
说白了disruptor是一款高性能有界内存队列,对标的是ArrayBlockingQueueLinkedBlockingQueue,而不是分布式队列。
Java内置的内存队列
在稳定性和性能要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列;Java SDK提供的两个有界队列:ArrayBlockingQueue和LinkedBlockingQueue;
| 队列 | 有锁 | 有界 | 数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | ReentrantLock | 是 | arraylist |
| LinkedBlockingQueue | ReentrantLock | 是 | linkedlist |
链表结构缺点
- 频繁的插入、删除操作,会导致内存的频繁申请和释放,容易造成内存碎片,Java中容易触发系统GC(Garbage Collection,垃圾回收)机制。故优先使用ArrayBlockingQueue。
ArrayBlockingQueue VS Disruptor性能对比
示例:
ArrayBlockingQueue
public class ArrayBlockingQueue4Test {public static void main(String[] args) {// 避免扩容影响性能final ArrayBlockingQueue<Data> queue = new ArrayBlockingQueue<Data>(100000000);final long startTime = System.currentTimeMillis();//向容器中添加元素new Thread(() -> {long i = 0;while (i < Constants.EVENT_NUM_OHM) {Data data = new Data(i, "c" + i);try {queue.put(data);} catch (InterruptedException e) {e.printStackTrace();}i++;}}).start();new Thread(() -> {int k = 0;while (k < Constants.EVENT_NUM_OHM) {try {queue.take();} catch (InterruptedException e) {e.printStackTrace();}k++;}long endTime = System.currentTimeMillis();System.out.println("ArrayBlockingQueue costTime = " + (endTime - startTime) + "ms");}).start();}}
Disruptor
public class DisruptorSingle4Test {public static void main(String[] args) {int ringBufferSize = 65536;final Disruptor<Data> disruptor = new Disruptor<Data>(() -> new Data(),ringBufferSize,Executors.newSingleThreadExecutor(),ProducerType.SINGLE,//new BlockingWaitStrategy()new YieldingWaitStrategy());DataConsumer consumer = new DataConsumer();//消费数据disruptor.handleEventsWith(consumer);disruptor.start();new Thread(() -> {RingBuffer<Data> ringBuffer = disruptor.getRingBuffer();for (long i = 0; i < Constants.EVENT_NUM_OHM; i++) {long seq = ringBuffer.next();Data data = ringBuffer.get(seq);data.setId(i);data.setName("c" + i);ringBuffer.publish(seq);}}).start();}// 消费者public class DataConsumer implements EventHandler<Data> {private long startTime;private int i;public DataConsumer() {this.startTime = System.currentTimeMillis();}@Overridepublic void onEvent(Data data, long seq, boolean bool) throws Exception {i++;if (i == Constants.EVENT_NUM_OHM) {long endTime = System.currentTimeMillis();System.out.println("Disruptor costTime = " + (endTime - startTime) + "ms");}}}
性能对比:
| NUM | Disruptor | ArrayBlockingQueue |
|---|---|---|
| 1千万 | 828ms | 2194ms |
| 5千万 | 3180ms | 12422ms |
| 1亿 | 6375ms | 25647ms |
ArrayBlockingQueue多线程情况下性能更差,有锁;Disruptor天生是个多生产者、多消费者的模型,高并发情况下更好。更能说明ArrayBlockingQueue与Disruptor差距。
ArrayBlockingQueue存在的问题
- 使用ReentrantLock保证线程安全;有锁性能太差
- 伪共享,缓存失效问题
�伪共享
共享
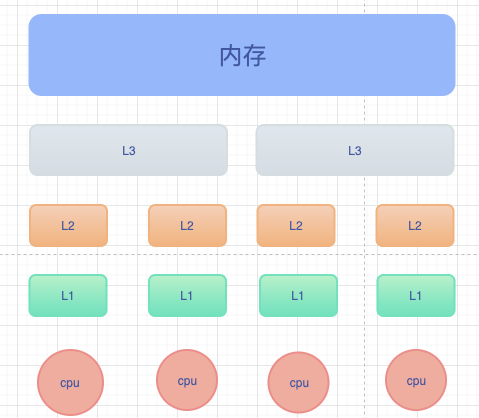
如图,计算机三级缓存架构,L1,L2缓存由CPU独占,L3缓存由多个CPU共享,内存所有CPU共享;速度从下至上依次递减,存储大小从下至上一直递增。
当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。
线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。
速度对比

缓存行
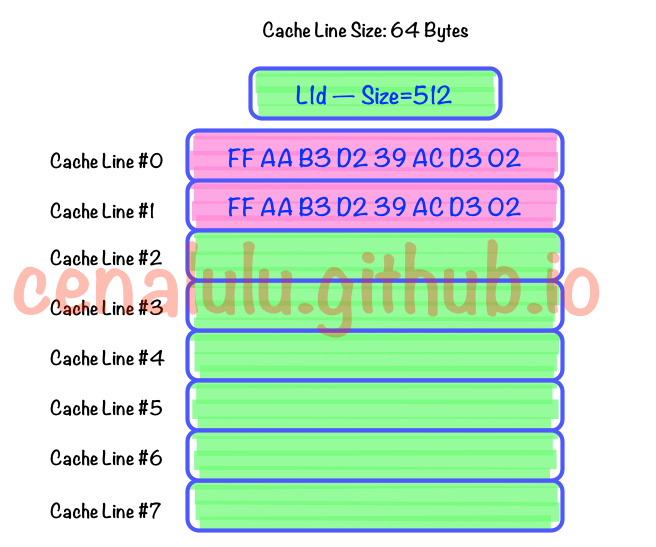
Cache Line可以简单的理解为CPU Cache中的最小缓存单位。目前主流的CPU Cache的Cache Line大小都是64Bytes。假设我们有一个512字节的一级缓存,那么按照64B的缓存单位大小来算,这个一级缓存所能存放的缓存个数就是512/64 = 8个。
什么是伪共享
CPU从内存加载数据时,会把相邻的数据缓存到同一个缓存行。例如:加载long型的属性X(8字节)到Line1,Line1会把X邻近56个字节加载到缓存行,提升缓存命中。
但是会出现伪共享的问题,由于多核CPU多级缓存一致性协议MESI,线程修改了其中的一个缓存数据,会导致所在的缓存行失效,影响到X数据的缓存命中,这就是伪共享。
Disruptor设计
- 内存分配更加合理,环形数组结构(RingBuffer),内存预加载,初始化时提前一次性创建;对象循环利用,避免频繁GC。
- 才用大量的CAS,无锁算法,减少性能消耗。
- 解决伪共享的问题,提升缓存利用率。
- 支持批量消费,消费者可以无锁方式消费多个消息。
如何解决伪共享?
每个变量独占一个缓存行、不共享缓存行,就是缓存行填充技术。想让X独占一个缓存行,就在其前后各填充56个字节即可。Disruptor很多对象都是利用这种填充技术来避免伪共享。在1.8就可以通过注解@Contended来解决这个问题。
public class Sequence extends RhsPadding {static final long INITIAL_VALUE = -1L;private static final Unsafe UNSAFE = Util.getUnsafe();private static final long VALUE_OFFSET;...}class RhsPadding extends Value {protected long p9;protected long p10;protected long p11;protected long p12;protected long p13;protected long p14;protected long p15;...}class Value extends LhsPadding {protected volatile long value;Value() {}...}class LhsPadding {protected long p1;protected long p2;protected long p3;protected long p4;protected long p5;protected long p6;protected long p7;...}
RingBuffer设计
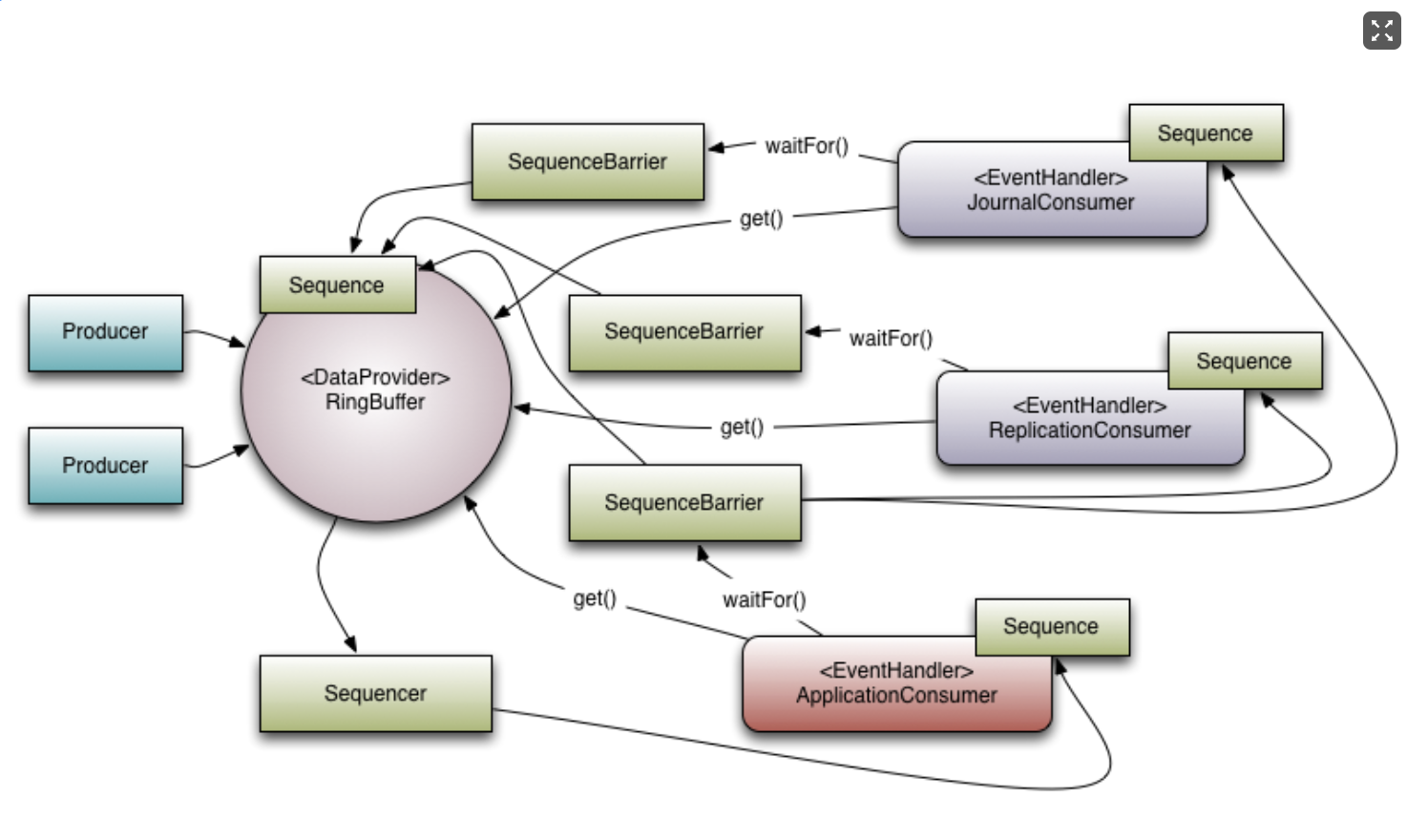
- RingBuffer:环状数组,承载数据的容器。
- Event:生产者生产对象
- EventHandler:消费者业务处理器,实现接口WorkHandler并实现onEvent方法(具体的业务逻辑)
- Sequence:序号,Long类型常量,记录RingBuffer投递下标,生产者消费位置,通过对齐填充消除伪共享。
- Sequence Barrier:用来跟踪发布者(publisher)的游标(cursor)和事件处理者(EventProcessor)的序列号(sequence)。
- WaitStrategy:生产者、消费者等待策略
- WorkProcessor:确保每个sequence只被一个processor消费,在同一个WorkPool中,确保多个WorkProcessor不会消费同样的sequence;
环形数组结构是整个Disruptor的核心所在。
- 首先因为是数组,所以要比链表快.
- 根据我们对上面缓存行的解释知道,数组中的一个元素加载,相邻的数组元素也是会被预加载的,因此在这样的结构中,cpu无需时不时去主存加载数组中的下一个元素。
- 为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。
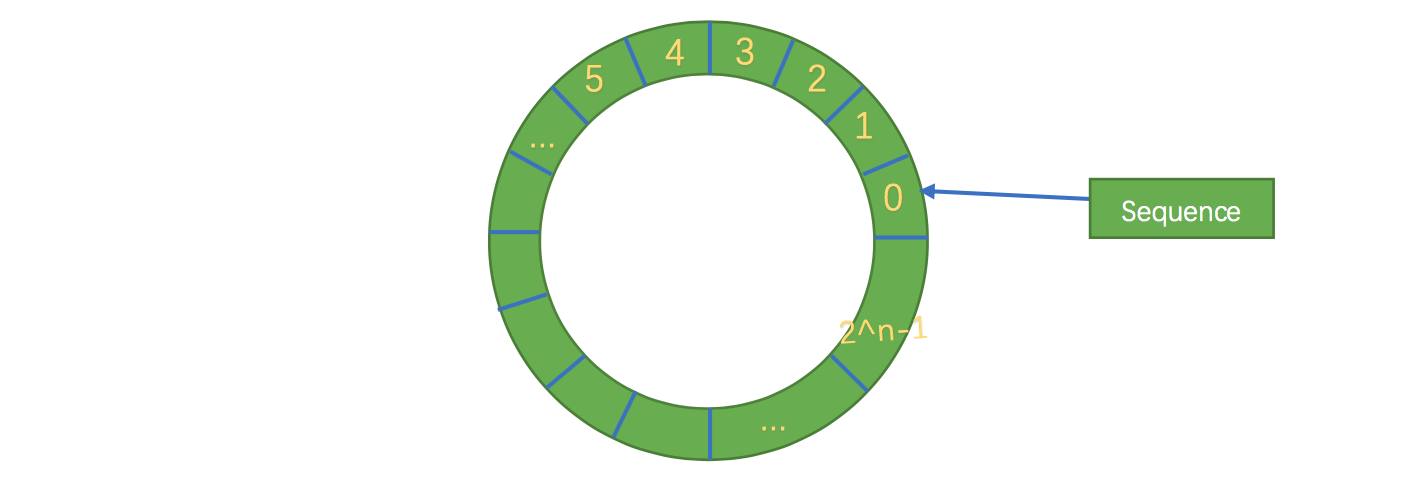
- 其次结构作为环形,数组的大小为2的n次方,这样元素定位可以通过位运算效率会更高,这个跟一致性哈希中的环形策略有点像。
- 其实质只是一个普通的数组,只是当放置数据填充满队列(即到达2^n-1位置)之后,再填充数据,就会从0开始,覆盖之前的数据,于是就相当于一个环。
Disruptor无锁算法
ArrayBlockingQueue是利用管程实现的,生产、消费操作都需要加锁,实现起来简单,但性能不是十分理想。Disruptor采用的是无锁算法,大量的CAS操作,但核心无非是生产和消费两个操作。最复杂是入队操作,不能把没有消费的数据给覆盖。
SingleProducerSequencer投递数据(入队)核心代码
public long next(int n) {//生产者获取n个写入位置if (n < 1) {throw new IllegalArgumentException("n must be > 0");} else {//类似于入队索引,上次生产到的地方long nextValue = this.nextValue;// 获取生产的第n个的位置下标long nextSequence = nextValue + (long)n;// 减掉一个循环,来判断是否会覆盖掉未消费的数据long wrapPoint = nextSequence - (long)this.bufferSize;// 获取上一次的最小消费位置long cachedGatingSequence = this.cachedValue;// 没有足够的空余位置(wrapPoint如果比最小的消费下标大,说明会覆盖)if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue) {long minSequence;// 没有足够的空余位置,挂起while(wrapPoint > (minSequence = Util.getMinimumSequence(this.gatingSequences, nextValue))) {LockSupport.parkNanos(1L);}// 重新设置最小消费位置this.cachedValue = minSequence;}this.nextValue = nextSequence;return nextSequence;}}
消费者消费逻辑解析:BatchEventProcessor(生产者不能覆盖消费的最小下标)
while (true){try{// 获取可用消息的最大值final long availableSequence = sequenceBarrier.waitFor(nextSequence);// 如果当前的位置小于可用的位置,说明有消息可以处理,进行消息处理while (nextSequence <= availableSequence){event = dataProvider.get(nextSequence);// 回调eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);nextSequence++;}sequence.set(availableSequence);}catch (final TimeoutException e){notifyTimeout(sequence.get());}catch (final AlertException ex){if (!running.get()){break;}}catch (final Throwable ex){exceptionHandler.handleEventException(ex, nextSequence, event);sequence.set(nextSequence);nextSequence++;}}
Disruptor实战
disruptor快速使用
- 建立一个工厂Event类,用于创建Event类实例对象
public class OrderEvent {/*** 订单的价格*/private long value;public long getValue() {return value;}public void setValue(long value) {this.value = value;}}/*** @author liushiqiao* @desc 继承 EventFactory工厂*/public class OrderEventFactory implements EventFactory<OrderEvent> {/*** 这个方法就是为了返回空的数据对象(Event)** @return*/@Overridepublic OrderEvent newInstance() {return new OrderEvent();}}
- 需要有一个监听事件类,用户处理数据(Event类)
/*** @author liushiqiao* 消费者对象*/public class OrderEventHandler implements EventHandler<OrderEvent> {@Overridepublic void onEvent(OrderEvent event, long sequence, boolean endOfBatch) throws Exception {Thread.sleep(Integer.MAX_VALUE);System.err.println("消费者: " + event.getValue());}}
- 实例化Disruptor实例,配置参数,编写Disruptor核心组件
/*** @author liushiqiao*/public class Main {public static void main(String[] args) {// 参数准备工作OrderEventFactory orderEventFactory = new OrderEventFactory();int ringBufferSize = 4;ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());/*** 1 eventFactory: 消息(event)工厂对象* 2 ringBufferSize: 容器的长度* 3 executor: 线程池(建议使用自定义线程池) RejectedExecutionHandler* 4 ProducerType: 单生产者 还是 多生产者* 5 waitStrategy: 等待策略*///1. 实例化disruptor对象Disruptor<OrderEvent> disruptor = new Disruptor<OrderEvent>(orderEventFactory,ringBufferSize,executor,ProducerType.SINGLE,new BlockingWaitStrategy());//2. 添加消费者的监听 (构建disruptor 与 消费者的一个关联关系)disruptor.handleEventsWith(new OrderEventHandler());//3. 启动disruptordisruptor.start();//4. 获取实际存储数据的容器: RingBufferRingBuffer<OrderEvent> ringBuffer = disruptor.getRingBuffer();OrderEventProducer producer = new OrderEventProducer(ringBuffer);ByteBuffer bb = ByteBuffer.allocate(8);for (long i = 0; i < 5; i++) {bb.putLong(0, i);producer.sendData(bb);}disruptor.shutdown();executor.shutdown();}}
- 编写生产者组件,向Disruptor容器投递数据
/*** @author liushiqiao* 生产者*/public class OrderEventProducer {private RingBuffer<OrderEvent> ringBuffer;public OrderEventProducer(RingBuffer<OrderEvent> ringBuffer) {this.ringBuffer = ringBuffer;}public void sendData(ByteBuffer data) {//1 在生产者发送消息的时候, 首先 需要从我们的ringBuffer里面 获取一个可用的序号long sequence = ringBuffer.next();try {//2 根据这个序号, 找到具体的 "OrderEvent" 元素 注意:此时获取的OrderEvent对象是一个没有被赋值的"空对象"OrderEvent event = ringBuffer.get(sequence);//3 进行实际的赋值处理event.setValue(data.getLong(0));} finally {//4 提交发布操作ringBuffer.publish(sequence);}}}
串行操作
//2 把消费者设置到Disruptor中 handleEventsWith//2.1 串行操作:disruptor.handleEventsWith(new Handler1()).handleEventsWith(new Handler2()).handleEventsWith(new Handler3());
并行操作: 可以有两种方式去进行
disruptor.handleEventsWith(new Handler1(), new Handler2(), new Handler3());// 分别调用disruptor.handleEventsWith(new Handler2());disruptor.handleEventsWith(new Handler3());
�菱形操作
disruptor.handleEventsWith(new Handler1(), new Handler2()).handleEventsWith(new Handler3());EventHandlerGroup<Trade> ehGroup = disruptor.handleEventsWith(new Handler1(), new Handler2());ehGroup.then(new Handler3());
�六边形操作
Handler1 h1 = new Handler1();Handler2 h2 = new Handler2();Handler3 h3 = new Handler3();Handler4 h4 = new Handler4();Handler5 h5 = new Handler5();disruptor.handleEventsWith(h1, h4);disruptor.after(h1).handleEventsWith(h2);disruptor.after(h4).handleEventsWith(h5);disruptor.after(h2, h5).handleEventsWith(h3);
消费者常见的等待策略
BusySpinWaitStrategy : 自旋等待,类似Linux Kernel使用的自旋锁。低延迟但同时对CPU资源的占用也多。
BlockingWaitStrategy : 使用锁和条件变量。CPU资源的占用少,延迟大,默认等待策略。
SleepingWaitStrategy : 在多次循环尝试不成功后,选择让出CPU,等待下次调度,多次调度后仍不成功,尝试前睡眠一个纳秒级别的时间再尝试。这种策略平衡了延迟和CPU资源占用,但延迟不均匀。
YieldingWaitStrategy : 在多次循环尝试不成功后,选择让出CPU,等待下次调。平衡了延迟和CPU资源占用,但延迟也比较均匀。
PhasedBackoffWaitStrategy : 上面多种策略的综合,CPU资源的占用少,延迟大
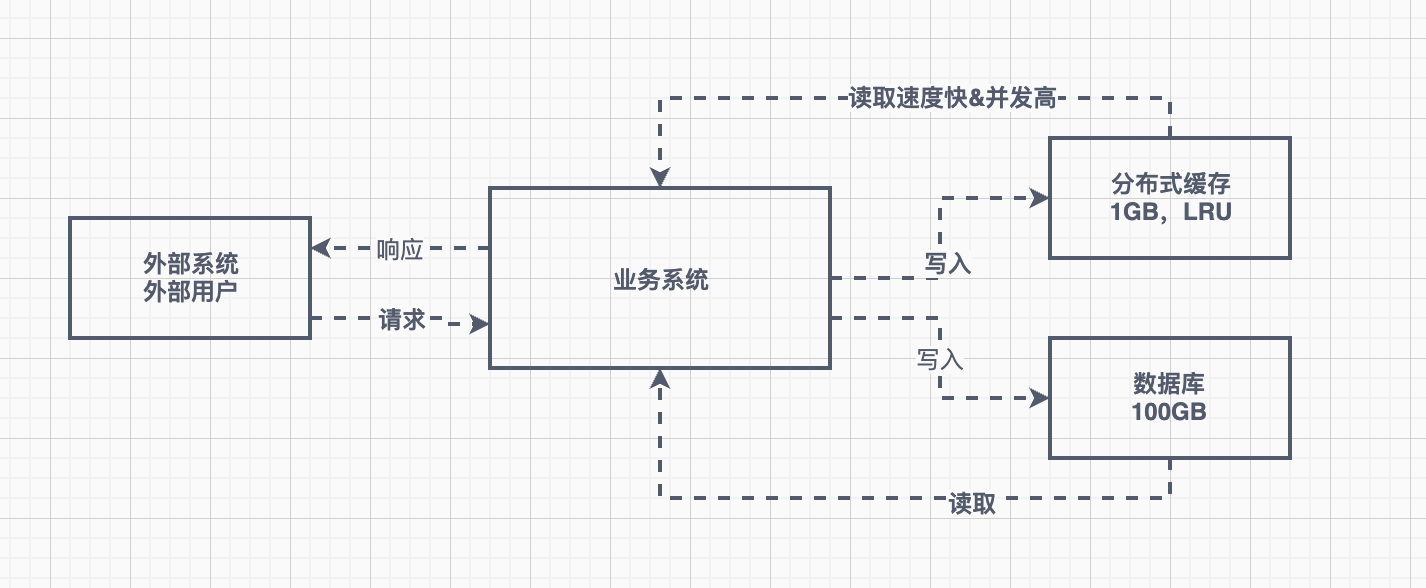
高并发下使用场景
缓存架构
缓存不一致场景
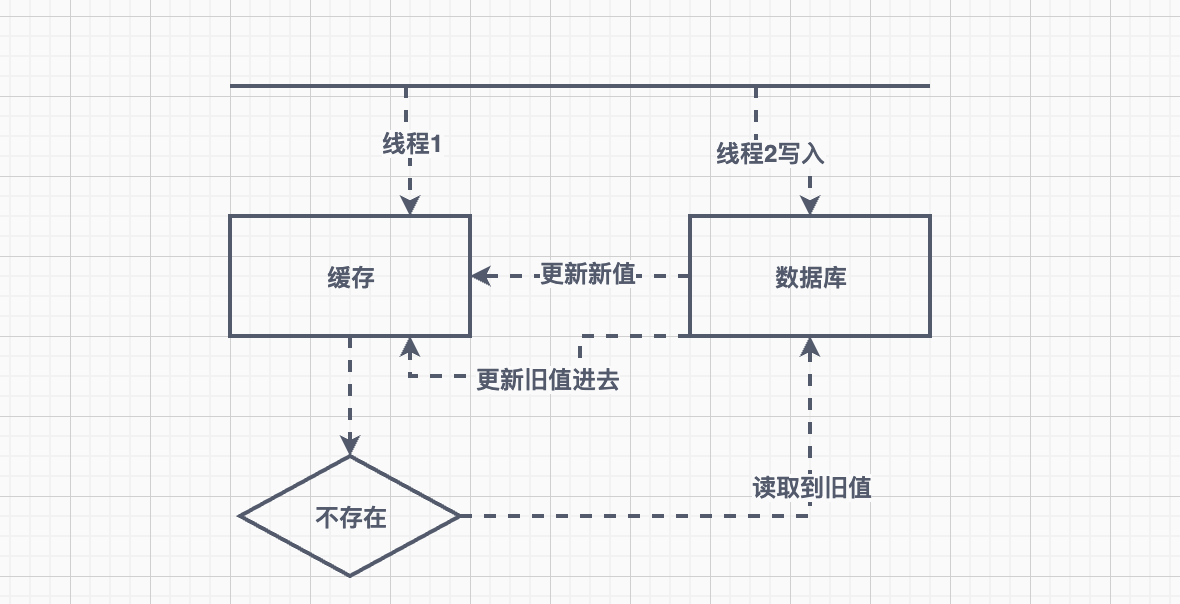
- 线程一:读取数据,缓存不存在(淘汰),读取数据库(旧值)
- 线程二:写入数据库,更成功更新缓存
- 线程一:把读取的旧值更新到缓存,导致数据库、缓存不一致
解决方案
内存队列异步读写串行化
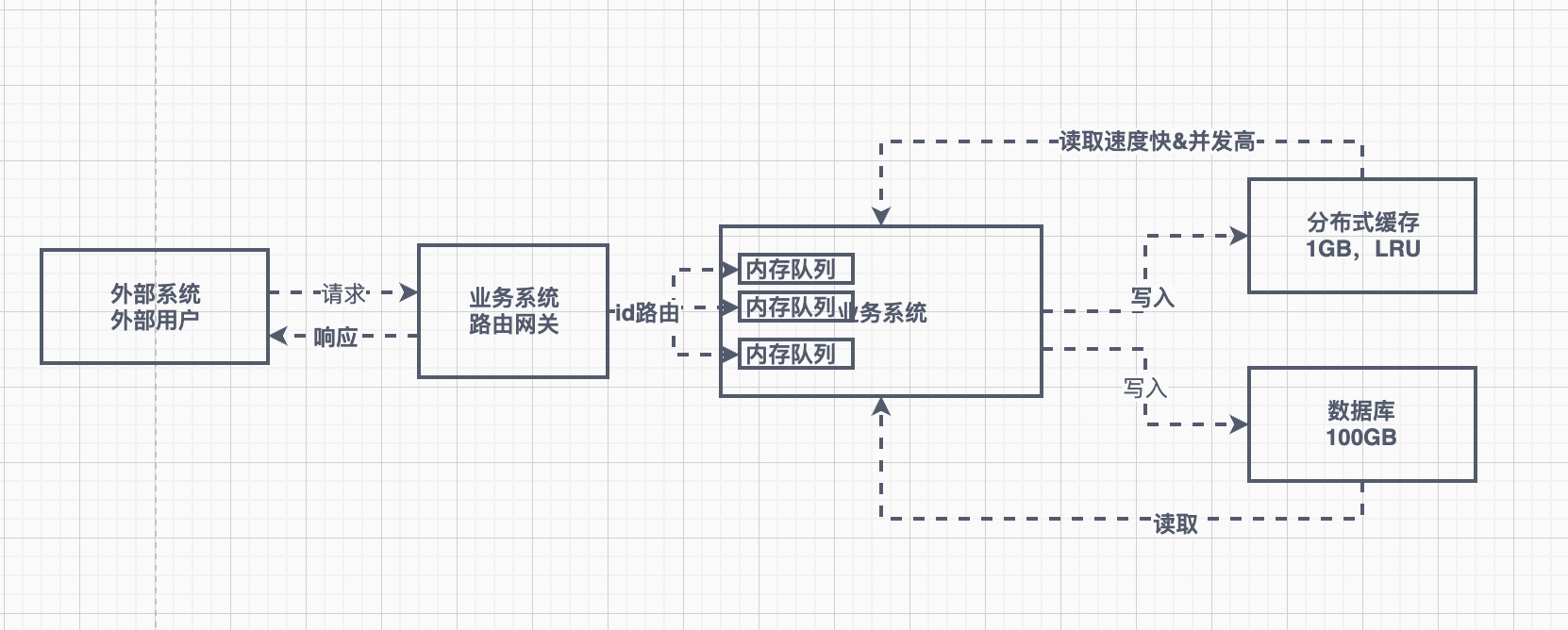
问题:内存队列数据慢了,阻塞,系统崩溃了都会导致数据异常。
最终解决方案
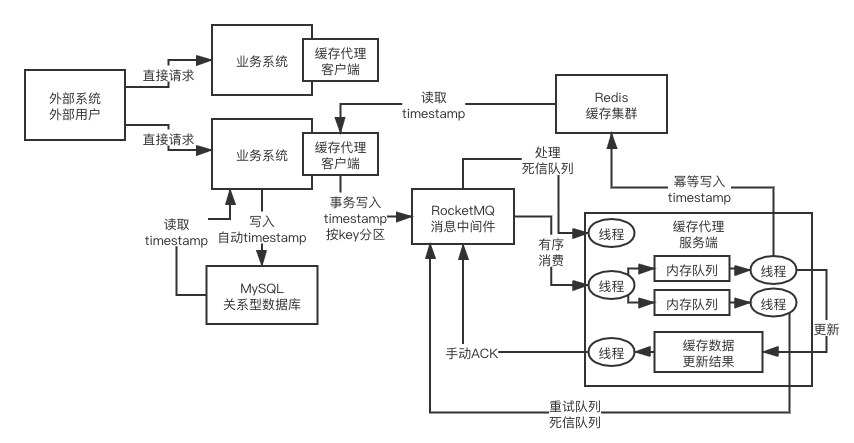
1、根据数据库时间戳当写入版本号,避免覆盖问题
2、通过业务id,hash到某个队列上,顺序消费
3、避免吞吐量性能问题,一个队列使用一个线程消费,可以使用内存队列多线程消费
4、避免内存队列数据丢失问题使用手动ACK机制,内存队列消费完后手动ACK
5、如果更新失败,丢到重试队列,防止阻塞
6、重试队列一直失败,丢到死信队列中,人工接入
7、使用时间戳保证重复消费幂等信
[

若有收获,就点个赞吧
0 人点赞
