设计原则是能被应用到设计或编写程序代码中的工具或技术,让程序代码更可维护,更具灵活性或者更易扩展.
使用已被证实的OO设计原则形成更可维护,更具灵活性以及更易扩展的软件.
基本原则
- 封装变化之物(最好将之封装到配置文件里面)。
- 对接口编程,而不是对实现。
- 应该程序的每一个类只有一个改变的理由。
- 类是关于行为各功能的。
- 多用组合,少用继承。
- 为交互对象之间的松耦合设计而努力。
开闭原则(OCP: Open-Closed Principle)
类应该允许对扩展开放,对修改关闭。
OCP关系到允许改变,但是以不需要修改现有程序代码的方式进行。
不自我重复原则(DRY:Don’t Repeat Yourself Principle)
通过将共同逻辑抽取出来并放到单一的地方以避免重复代码。
DRY关系到让系统中的每一个信息与行为的片段都保存在单一合理的地方。确保应用程序中的每一个功能与需求只实现一次。
重复的代码很难维护,必须杜绝!
单一职责原则(SRP:Single Responsibility Principle)
系统里的每一个对象应该具有单一职责,所有对象的服务都应该聚焦在实现该职责上。
对象保持简单性,只做一件事并把事情做好。类只有一个改变的理由。
Liskov替换原则(LSP:Liskov Substitution Principle)
子类型必须能够替换其基类型
LSP完全关系到设计良好的继承。当你从一个基类继承下来时,你必须能用你的子类替换该基类且不会出问题,否则你就错误地使用了继承。
面向接口编程,而非面向实现编程
- 上游的调用者代码,不依赖不稳定的具体实现细节。
- 降低上游代码与实现代码之间的耦合性,提供了系统的扩展性;
- 基于‘抽象’而非实现编程,提高了系统扩展性、灵活性、可维护性;
面向对象编程要有:抽象意识、封装意识、接口意识。
面向对象设计的五大原则:SOLID。
SOLID原则
SOLID都是些什么呢?
- SRP, Single responsibility principle,单一职责。一个类只能有一个职责,如果这个类需要被修改,那只能是某一个需求更改导致的(仅此一个,没有更多的)。例如,book类里面有一个print的函数,当我们修改book类的书名时,我们需要改book类,当我们把book的打印从打印到A4改成打印成6寸时,也需要修改此类,这就违背了SRP原则。
- OCP, Open/closed principle,开闭原则,Open for extension, but closed for modification
- LSP, Liskov substitution principle,父类能够被子类无忧的替代,不必担心产生副作用。
- ISP, Interface segregation principle,如果一个接口能够被拆分成多个接口,那就不该用这个通用的接口来呈现。
- DIP, Dependency Inversion principle,依赖于抽象,而不依赖与具体的实现。
单一职责
它的定义上面已经讲过了。
这一条是用来帮助我们创建更为松耦合和模块化的程序,因为每种不同的行为我们都封装到一个新的类或对象里面去了。未来要增加新的行为或特性,新增的内容也会增加新的对象里面,而不是把这些行为加到原来的对象上去。
这样做的好处是更安全,更不容易出错,因为以前的类可能是含有多种多样的依赖关系的,但新增加的类却没有那些依赖在里面。所以我们可以放心的修改系统行为,不必担心修改带来的副作用。
在分层结构中,这个思想也有体现。我们的UI/Presentation层专管UI的显示,logic层专攻业务逻辑,数据访问层只做数据访问相关内容。其实,都是同样的道理。
如果SRP思想贯穿了你的整个程序,你的逻辑层里的某一个服务是不是就成了微服务,一个微服务只有一个单一的职责,你要给你的程序增加功能,那再加一个微服务即可(切忌在已有的微服务上添加)
依赖反转(Dependency Inversion)
应用程序内部的依赖不应该依赖于具体的实现,应该依赖于抽象。
也是五大原则之一。
很多应用的依赖是在编译期就确定了依赖的顺序,就如同模块A调用了模块B的一个函数,刚好这个模块B内的函数又调用了模块C的某个函数,于是,A就依赖B,B依赖于C。
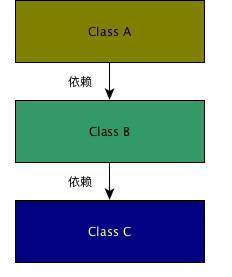
应用了DIP之后,就像这个样子:
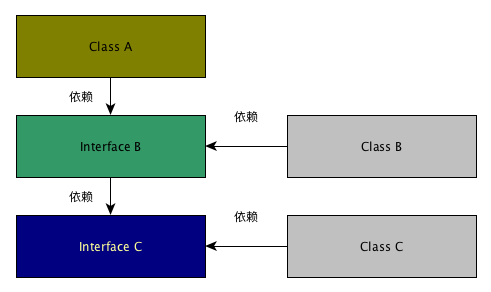
可以看到,ClassA不再依赖于Class B,转而依赖InterfaceB,ClassB也不再依赖于Class C,转变成Interface B依赖于Interface C。
ClassA现在依赖的是B的抽象(即Interface B),这使得A在运行时依然可以调用到B的函数,运行时应有的行为还能得以保留。不过B依赖已经变化了,它现在依赖于Interface B了(反转依赖),现在的好处在于,不但B的功能可用,未来你想变成B1,B2,B3,这些都不必修改Class A了(如果你现在还不明白如何去实现,参考Ioc Container的实现)。
依赖翻转是构建松耦合应用的关键所在,既然具体的实现都依赖于更高层的抽象了,那么程序就应该更容易被测试、维护和模块化。其实依赖注入(Dependency injection)也是准照这个原则来扩展实现的,所以掌握这个方法也是十分的重要。
以下原则跟SOLID无关,但我认为也是比较重要的。
显式依赖
如果函数或类必须依赖其他类或对象的某些状态才能正常工作,那应该显式的声明其依赖的对象或类。
这有点拗口。
实际上类的构造函数提供了一个约定:我要构造这个类A的对象,需要提供1、2、3、4个参数,如果没有这几个参数,我的类就可能工作不正常。
ClassA的依赖关系很明确,就是要1、2、3、4个参数,这是合理的。
假设这样一种情况,ClassA除了上述依赖以外,后来增加了一个新的依赖,在增加这个依赖的时候,我没有将它显示的写在构造函数里面,因为这个依赖项是个全局对象。
一般来说这样的代码运行起来也没有什么问题,但是在实际上,它在逻辑上已经引发了一个问题:你的这个类的依赖关系内外不一致。试想如果在另外一个场景里,这个全局的对象失效了或不存在,那么你的这个类就不能用了。
你的类已经不能用了,但是你们团队里面的其他成员可能并不知道,他们仍然按照之前的模式继续使用你的类,于是这就引起了潜在的错误。
如果你的类能够显式声明它的所有依赖,你的类才能够更友好,代码本身也能更清楚的表达自身的含义。你的小组其他成员相信,只要完全的传递了你要的参数,你的代码就一定会按既定的逻辑运行下去。
避免重复(Don’t repeat yourself)
重复代码是后期bug修复的大敌。
我们要尽量避免编程时使用复制和粘贴的功能,如果同样的逻辑在代码里的多个位置出现,每次我们维护的时候就不得不同时维护多处。当功能转交给其他人时,其他人也会厌烦多处查找这些问题;其他人将这类代码转交给你时,你也会头疼不已。
忽略持久化(Persistence Ignorance)
这个概念PI,有些地方也称作持久性无知,是指你需要存储某个对象,但是这些代码不应该受到持久化方式更改的的影响。
在.Net里,有一种类叫POCOs(Plain Old CLR Objects),在Java里,这种叫POJOs(Plain Old Java Objects),这种类是不需要从基类或接口来继承的。
我们需要保证这类对象不要插手如何保存或如何获取(持久化和获取数据回来)。
做到这一点,我们的业务逻辑能更纯粹,而存储对象时,也能灵活地按需调整(比如说用Redis或Azure或Sql Server等等),无论存储的策略如何调整,我们的业务逻辑都是稳定的。
注意,如果你的代码有以下几类情况,那这些代码可能就是违反PI规则的:
- 必须继承自某个基类或必须实现某个接口
- 类的内部含有保存他们自己的代码
- 必须要写构造函数
- 属性上要求加Virtual
- 有自定义的存储相关的Attribute
如果类里面有上面的逻辑,暗示着这些类的持久化跟持久化的策略产生关联性,可以理解为她们是耦合的,将来如果要更换新的持久化方式,也许就比较困难了。
有界上下文(Bounded Contexts)
有界上下文是DDD中的一个核心模式,这种模式是帮助我们剥离开复杂的应用程序,将他们隔离开,形成不同的上下文边界。不同的模块有着不同的上下文,且能独立调用,而各自的模块可以有自己的持久化的,互不干扰。
在大型的应用程序中,不同的人对不同的的东西可能取相同的名字,这跟我们程序的类一样,为何我们要在外面放一个namespace在外面,其实也是形成一个边界。程序内部也是如此。
例如,售楼部内的员工把商品房认为是产品(Product);但是在工程部,可能他们把刷灰和修理管道的服务叫做产品,为了消除这些歧义,可以定义一个边界,分离开两种情况,以免在系统内产生混淆。
结语
这是这个系列的最后内容,实际上每一个小点都能展开成一大章节来说,后续有时间可以进行延伸的讨论。而因为这篇的内容除了SOLID外,跨度都还比较大,以至于我都不好写标题,暂以《其他原则》为题好了。
面向对象编程其实挺难的,我们很多的人都没有真正的理解面向对象,以至于所谓的面向对象,就是我们用上了class关键字而已。如果有时间,可以专门看看设计模式的书,相信还是会有很多的收获的。
这些内容可能过于偏于理论,但是有了这些理论的指导,我们的开发的日子才会更容易一些。但话又说回来,如果你要做的项目是个一杆子买卖,根本不会持续维护,那你还是尽量的使用反模式吧,又快又省心不烧脑。可是如果你的项目是长度维护的项目,必要的考量还是需要的,否则,你就陷入了泥潭,总是发梦期望公司将原来的推翻重写,一次偿还所有的技术债了。

若有收获,就点个赞吧
0 人点赞
