Bean有几种创建方式
两种
- 声明式:加入@component、@bean、《Bean》标签 之类
- 编程式:定义BeanDefinition,并且把这个注入进去spring容器中,不然spring容器不知道。

Bean对象的生命周期
得到class文件
推断构造函数
在实例化对象之前推断构造方法,一般是调用无参构造函数,当有两个构造函数的时候我们可以在我们想调用的构造函数上加@autowired表示要使用哪个构造函数。如果我们没有无参构造器,只有一个有参构造器,那么也会执行这个有参构造器。
真正实例化对象
属性填充(依赖注入,待完成)
这里涉及多个注解
处理Aware接口
Spring会检测该对象是否实现了xxxAware接口,通过Aware类型的接口,可以让我们拿到Spring容器的一些资源
BeanPostProcessor前置处理
如果想对Bean进行一些自定义的前置处理,那么可以让Bean实现了BeanPostProcessor接口,那将会调用postProcessBeforeInitialization(Object obj, String s)方法。
属性填充后的方法
afterPropertiesSet()方法,见名知意,是在属性填充完后执行的方法,一般可以用来给某些不注入容器的对象设置初始值,使用这个方法需要实现InitializingBean接口。
init-method
如果Bean在Spring配置文件中配置了 init-method 属性,则会自动调用其配置的初始化方法。
得到Bean
最终生成的bean,如果有aop生成的是代理对象,没有aop生成的就是真正的目标对象。
BeanPostProcessor后置处理
如果这个Bean实现了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法;由于这个方法是在Bean初始化结束时调用的,所以可以被应用于内存或缓存技术;
AOP(可选择)
如果使用aop了的话,最终产生的就是代理对象,这个代理对象继承了被代理对象,代理类有一个被代理类的属性(名字叫target),这个属性的类型就是被代理类的类型。同时也有代理的方法,其中包括了代理逻辑和被代理的方法(比如target.test() )。
注意:1、如果被代理对象有属性的话,这个代理对象是不包含这些属性的,但是我们去看代理对象属性指向的那个被代理对象的时候是有那些属性的,因为是同一个对象。2、开启事务的时候,底层用了aop增强,我们取到的是代理对象。
由事务引发的问题
Transactional注解
这个注解底层使用了增强aop,所以当一个方法需要事务支持的话,那这个方法所属的类生成的对象就是一个代理对象。在调用方法时会1、建立连接。2、设置自动提交为false。3、执行目标方法。4、手动提交。
为什么要加configuration注解才有可以支持事务
因为加了这个注解表示向ioc容器中注入的也是一个代理对象,事务管理器中需要调用datasource()方法注入一个datasource,jdbctemplate也需要调用datasource()方法注入一个datasource,当我们不加这个注解的时候,我们就会调用两次这个方法,那么datasource就不是同一个,这个时候我们加了configuration注解,他就会通过代理逻辑判断,使我们两次用的都是同一个datasource,这样就保证了事务控制。
循环依赖问题
怎么产生循环依赖问题的
就是说有两个service,aservice与bservice,他们两个互相依赖,导致他们互相都不能创建出来。
解决方法
首先了解三级缓存的每个缓存的作用
singletonObjects:一级缓存,又称单例池,里面存放的是已经创建好的bean。 concurrenthashMap
earlySingletonObjects:二级缓存,完成实例化,但是还未进行属性填充及初始化的对象。hashmap
singletonFactories:三级缓存,提前暴露的单例工厂,如果是aop增强生成的就是代理对象,没有aop增强生成 的就是原生对象,二级缓存存储的就是从这个工厂得来的。hashmsp 《beanName,objectFactory(lambda表达式)》
当对象不需要aop增强的时候,只需要二级缓存
之前是首先当A实例化,准备填充B的时候发现没有B,所以去创建B,但是B又要去创建A,所以一直创建不成功。
但现在,我们在完成Bean的实例化之后就直接把一个对象包装成一个工厂添加进三级缓存中,这个时候没有调用lambda表达式(源码如下图1)。
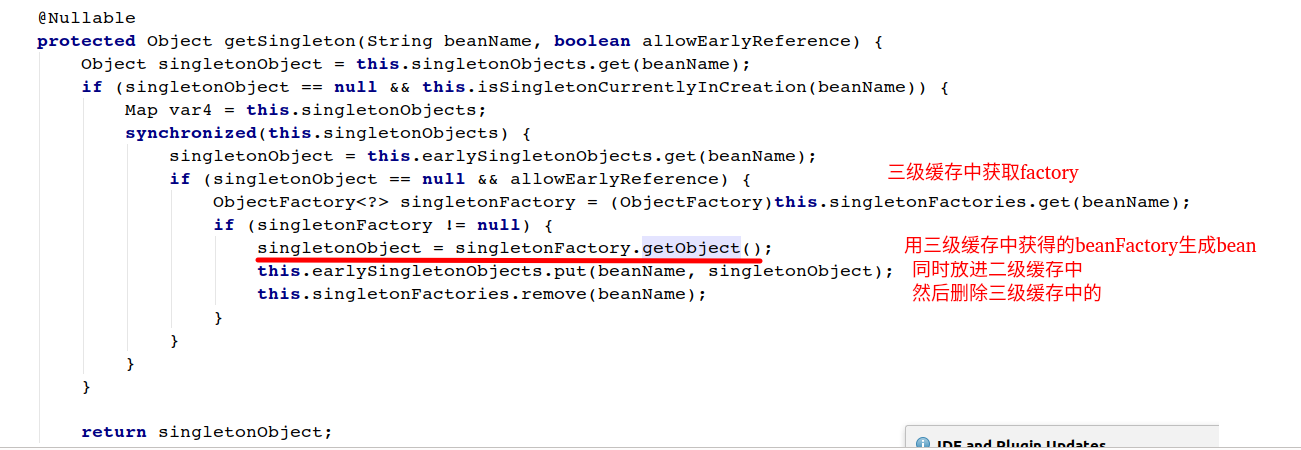
当B要创建A的时候,getBean(a)我们就不是创建了,就从二级缓存中获取,注意,是从二级缓存中取,看源码可以发现三级缓存调用lambda表达式直接把对象创建出来给二级缓存(源码如图2),二级没有的时候才去三级缓存调用getObject()方法(而实际调用的getEarlyBeanReference()方法暴露出实例化的A)得到A.
getEarlyBeanReference()方法源码(图3)。
这个时候我们就可以完成B的创建了,然后A也可以对B进行赋值了。这样我们就解决了循环依赖问题,但是我们会发现这个三级缓存他就只是得到一个工厂然后创建对象并且把对象缓存到二级缓存就可以了。这个时候确实只需要二级缓存就可以解决问题了,但是这个时候我们的对象不需要aop增强。

当aop增强的时候会出现的问题:
就是我们B创建好A的那个对象他是一个原生对象,但是假如A需要aop增强,因为aop增强是后执行的,并且产生一个代理对象,我们真实想要的肯定是将这个代理对象放到容器中,这样就和B里面注入的那个A冲突了。
当对象需要aop增强的时候
上面已经说到了A如果是在后面需要aop增强的话我们就达不到想要的结果,这个时候我们就可以把aop提前(用earlyProxyReferences来记录有没有这个bean增强),这样我们b中获取的也是代理对象(也是通过getEarlyBeanReference()方法,只是参数不一样,如图1)了,既然我们的aop增强了,那后面的aop增强就不执行了,到时候我们就判断有没有增强就可以了(判断有无增强源码如图二)。这个时候我们获取到的代理对象要放到二级缓存中去,然后到时候我们一级缓存取的时候就是从二级缓存中取。

这里解释一下为什么要用到三级缓存:
因为当我们B创建A的时候还没有完成属性填充,初始化等,A这个Bean还没有完全创建成功,与ioc相矛盾。而且我们一级缓存的东西是从二级缓存中拿得,二级缓存是从三级缓存拿得,假设有c依赖与a,那么他就直接从三级缓存拿,而三级缓存是通过工厂产生bean,这样的话就会产生多个A,不是单例。
总结循环依赖流程
就是说我们创建A的原始对象的时候就把它放进三级缓存中,key是beanName,value是objectFactory(其实就是一个lambda表达式,最后可以获取到原始对象或者代理对象),属性填充B的时候,发现没有B所以去创建B,当B要填充A的时候判断A是不是正在创建中(creatingset)是的话直接去二级缓存中拿,二级缓存没有的话就去三级缓存中拿(三级缓存给了二级缓存就会删除自己的,二者只能有一个有相同的bean,避免产生多例),三级缓存返回的是对象或者代理对象
假设二者需要的只是原始对象那这个三级缓存并没有用,只需要二级缓存缓存一个原始对象就可以了,但是问题就是可能他们需要的是代理对象,那就出了问题,所以三级缓存就派上用场了,它可以选择生成代理对象(如果是代理对象就会有earlyProxyReferences记录有没有增强)或者原始对象,然后交给二级缓存,到时候取出这个不确定的对象就可以了。
可能有的会说直接一个三级缓存不就可以了,但是我们要记住三级缓存只是负责生产对象,生产之后交给二级缓存然后自己的删除。假设没有二级缓存,那如果有C依赖于A,他也调用三级缓存,那么就会产生不同的A,这样是我们所不愿意看到的。
同时我们要保证ioc,我们得到代理对象的时间是在B填充A的时候,这个时候A的属性还没有填充,初始化没完成,违反了ioc的规范。
注意:三级缓存只是最核心的,其实还用到了两个map,earlyProxyReferences用来记录这个类有没有aop增强, creatingset用来判断有没有产生循环依赖。
IOC
控制反转
目的
底层原理
涉及的技术:
底层实现过程:
- 在xml配置文件中配置要注入的bean
- 工厂类的具有方法能获得bean的实例:具体实现方法是先通过xml解析解析出那个bean对象的位置,然后利用反射技术反射出对象实例。
IOC思想基于基于IOC容器实现(两个IOC容器)
BeanFactory
IOC容器的基本实现,是Spring内部的接口,不提供给开发人员使用
重要特点:加载配置文件的时候不会

若有收获,就点个赞吧
0 人点赞
