如需数据仓库经典电子书
可在公众号后台回复数字 1 获取链接。
上篇,我们主要讲解了数据建模的理论知识,同时跟大家介绍了数据建模的流程,以及常见的建模方法。
本篇,我们会基于上篇的建模理论,结合真实数仓场景,给大家介绍下完整的数仓建模过程。
1 数仓建模在数仓建设过程中的位置
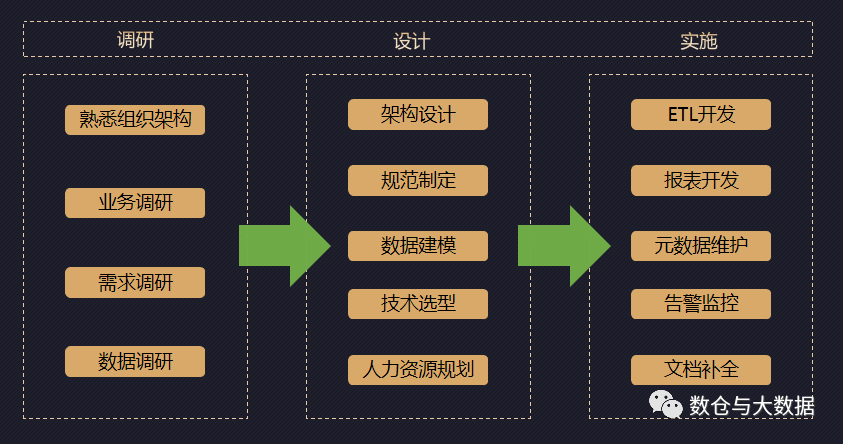
这张截图源自之前从 0 到 1 建设数据仓库的经验总结,采用的是瀑布模式的展现方式,但实际操作中经常会使用螺旋迭代模式,因为很难有人能够一步到位的考虑清楚所有细节。
通过业务调研我们熟悉了相关业务过程,需求调研我们明确了本阶段数据建设的需求、内容和边界,数据调研也就是数据探查我们对需要的数据源做了整体摸排,不清楚的就赶紧搞清楚、不对的就赶紧搞对、缺失的就想办法找补回来或者想办法补救,真要缺的太多是不是就要中止项目了至少也得重新规划。我们只是数据的搬运工,并不能凭空编造数据…
随后我们结合调研阶段的成果,做了五大架构设计、落实了技术选型、制定了数仓规范并分发给所有参与者。
接下来我们就进入到了数仓建模阶段,数仓建模对于数仓建设的成败能起到决定性的作用。
经常的我会把数据仓库类比成一个可以自运行的生态系统,当然我们拿人类自己来类比是最恰当了:人需要吃饭数仓也需要周期性的去源端获取数据,人有大脑和中枢神经去控制身体数仓有调度去掌控全局,人有骨架肌肉而数仓的骨架肌肉就是数据模型。
数仓模型承载了数据存储的重要职能,我们需要从全局视角去设计,因为它本身就是一个整体,人有手有脚数仓模型也要分成多个不同的部分,人的手脚身体大脑必须协调一致才能正常活动,数据模型的不同部分也需要协调一致数仓这个生态系统才能正常运转。人体如果筋脉不通就会生病,所以 Inmon 的数据建模思路讲究的是全局思考统一设计,Kimball 的数据建模思路提出的是总线架构,殊途同归其实都是提供给大家一套整体设计的方法论去打通数据模型甚至数仓运转的奇经八脉。
2 理论联系实践的数仓建模方法探索
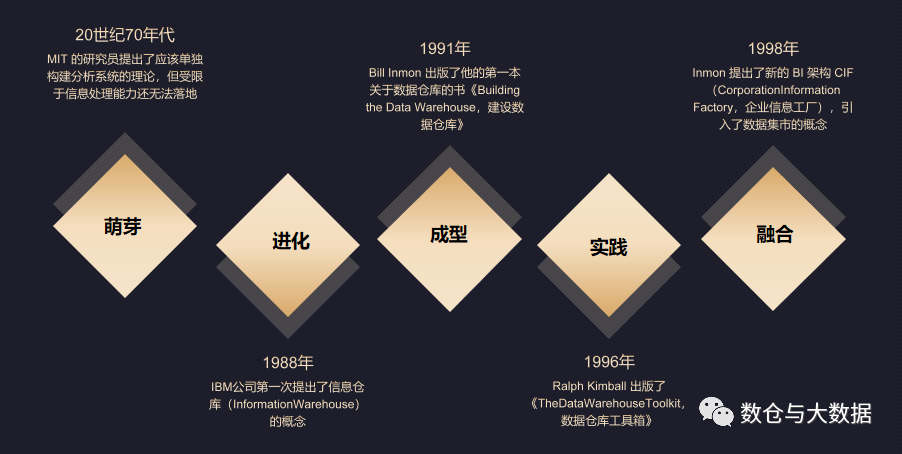

上边两页出自之前的 PPT 供大家参考。
国外的众多数据从业者经过几十年的理论研究和实践探索、多种方法论的碰撞,最终为我们留下了完整的方法论。而两大权威理论实际上包含的分别是两大不同的方法论:数仓建设方法和数仓建模方法。
Inmon 的数仓建设方法论倡导一种自上而下的瀑布式的建设过程。其数据仓库模型设计的出发点是整合数据,将各个系统中的数据从全企业视角分主题进行整合,打通所有数据源,剔除冗余、错误和不兼容,采用规范化的模型设计方法统一存储企业所有数据,为数据分析决策服务,但这种规范化的模型设计方法不太适合分析决策这种场景,所以后来又在此基础之上新增数据集市用于支撑各部门的业务应用。
规范化设计能够减少冗余避免数据不一致,全局兼容完整的设计能够保证数据的完整性。但是这种建模方法对建模人员的能力要求非常高,同时也需要对企业业务和数据有全面深入的了解,业务简单还好但对于复杂的业务场景难免拉长了建设周期、极大增加了模型设计的难度,以至于在一开始以这种方法实施的数据仓库大都以失败告终。
Kimball 的数仓建设方法,倡导自下而上建设,不用建设复杂的数据仓库,直接构建集市用于支撑业务需求,但当数据集市多了以后,多个数据集市间又造成了混乱和不兼容,而为了解决这种问题又提出了总线架构的概念。总线架构包含:一致性维度和一致性事实两个部分,我们集中设计和管理所有维度、统一定义各种指标,然后让所有数据集市都遵从这种一致性维度和一致性事实。
由于是直接构建数据集市,不需要过多的数据整合,Kimball 的构建方法相对于 Inmon 就会容易很多。虽然总线架构解决了多个数据集市间的兼容性问题,但这种建模方法还存在以下两个问题:1、模型的稳定性完全取决于建模师对业务场景对分析需求的理解程度。2、完全基于业务需求的建模对于需求“用不到”的数据就会被丢弃从而造成数据的缺失,本质上讲这是违背数仓建设原则的,那么我们就需要永久的保留 ODS 层的数据确保未来需要的时候有办法可以找补回来。
3 实践出真知适合自己的才是最好的

实际上我们并不会局限于某一种建模方法,我们需要在熟知各种建模理论的基础上,结合实际业务场景去选择合适的方法。
上图是我们常规的数仓建模流程,接下来我会逐个给大家讲解。我们主要采用统一调研、整体规划、分散设计、集中评审的建设思路,以及自顶向下和自下而上相结合的设计方法。
说明:这里的上和下并非架构图的上下,而是数据流向的上下游。我们称之为上游数据源下游数据应用。
我们通过三步调研,了解了业务流程、明确了中短期需求、对源端的数据质量和存储格式都有了清晰的了解。
三步调研之后,我们会制定数仓分层架构,逻辑上主要分为三层:ODS、DW、DM。目前大家常用的四层五层甚至七层本质上还是对这三层的细化。比如 ODS 层前边还能有一个 STG 层,STG 英文翻译 staging,也有说是 stage ,就是一个临时数据存放区,数据源端每次抽取或上传过来的数据(通常是增量)先入 STG 做短暂临时的存放,ETL 进行简单的清洗、合并、转换后入 ODS 层存储。DW 层还会被细分成 DWD、DWS 等,当然还有可能会构建主题宽表,那宽表是否需要再分为明细宽表和汇总宽表呢,宽表应该归属于 DW 还是 DM 呢?当然了放哪儿都行这些都不重要逻辑上能讲通就行。
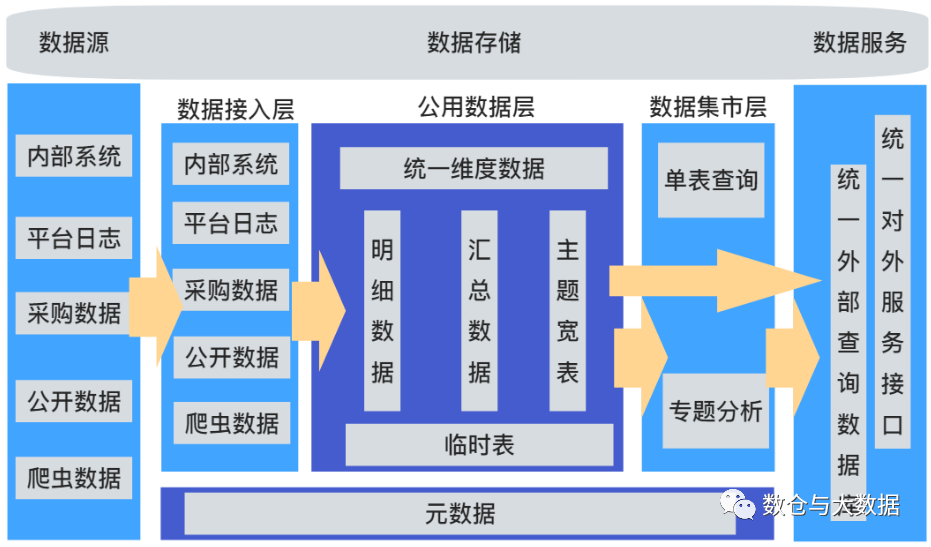
分层架构出来后,我们会根据每一层的不同用途有针对性的建模。
ODS 层,原始数据存储区,存储结构跟源端保持一致原则上不做清洗转换,命名上:数据来源+源端原始名称,数据保留时长取决于下游。如果 ODS-DW 过程中没有信息丢失,可以只保留 3-7 天,保留时间越短对运维人员要求越高。如果该过程有信息丢失为防止万一 ODS 层需要永久保留,保留策略有很多,比如从时间上划分为冷热数据冷数据可以归档转移到更便宜的存储,比如对数据内容上进行归类对于一段时间后就失去价值的数据直接删除即可例如系统运行日志。
DW 层,数据仓库的核心存储层,这一层数仓建模的核心,相对标准的思路是我们在明细层采用范式建模的思路自顶向下设计把 ODS 层的数据完整的整合进来,打破孤岛(ID 映射)、消除冗余,再往上层可以采用维度建模的思路,基于 DWD 层做轻度汇总、重度汇总,主要以满足业务需求为主,后期如有需求新增或变化可以基于 DWD 层的完整数据重新汇总。DW 层的数据是需要长期保留的。
当然在大数据场景下,我们通常需要考虑存储和计算开销,会去评估这些成本投入是否产生了足够的价值,明细层往往也会采用维度建模而且完全面向需求去设计,就是说短期用不到的数据我们就先不引入 DW 层了,等需要的时候再根据原始数据算。
这里需要说明一下,数据丢失远比计算错误更需要引起大家重视。由于某些原因很多大数据从业者没有认识到数据丢失的惨重后果。记得之前有一次为了降低成本老板甚至让删除一年之前的原始归档数据,结果没几天新的需求 DW 层无法满足需要重刷历史数据,幸好当时我们找借口拖着没删。
DM 层,数据集市层在逻辑上会包含多个数据集市。DWS 层汇总的通常是公用的、经常被使用的数据,绝大多数常规业务也都可以基于 DWS 直接实现,满足不了的时候我们需要根据各部门或者项目的需求去重新组织构建对应的数据集市,这一层通常也是采用维度建模方法自下而上完全面向需求去设计,数据集市往往伴随着对应的部门或项目需求而建立或者终止。
这里先做个简单的总结:
- ODS 不用建模直接用源端数据存储结构。
- DWD 范式建模,保证 ODS 到 DW 信息不丢失,如果 DWD 也采用维度建模 ODS 数据一定要长期保留。
- DWS 维度建模面向需求设计,存储一些全域经常被使用到的数据。
- DM 完全面向需求建模,生命周期跟对应需求的生命周期一致。
横向分层讲完了,那我们接下来聊聊纵向分域吧。
- 分域的目的是为了给数据或表进行归类,从而方便数据管理。
- 分域的概念也主要用在 DW 和 DM 层。
- DW 层主要面向业务过程划分数据域,数据域下边再划分多个主题,主题下边会有多个业务过程,理论上每个业务过程对应一张表,但当所有表设计好以后需要结合 ETL 过程和业务使用习惯考虑是否需要对多张表进行合并操作。
- DM 层划分数据域的方式就简单了,完全对应需求场景或者使用部门就好了。
分层和分域的概念讲完后,我们接下来需要制定相应的模型设计和使用规范。具体到落地阶段了,那么很多事情我们就必须把它明确下来,上边我们提到的内容在具体细节上可能会有多种选择,比如 ODS 数据保留策略、DWD 采用何种建模方法、有无主题宽表以及宽表归属哪一层等等,这些都需要通过规范去明确从而避免多人协作过程中的混乱。更具体的内容可以参考文末推荐阅读里的相关历史文章。
对于一致性维度、一致性事实的保障策略,也需要通过规范去明确和约束,确保同一个维度或度量在数仓的所有地方有相同的含义。我们也要通过规范教会大家如何才能建设出来统一高质量的数据模型。
以上的统一调研、整体规划(分层架构、规范制定、主题域划分)后,我们进入了分散设计的阶段。
分散设计
到这里,由于数仓模型设计的复杂性,我们需要多人合作共同完成建模工作,这时候架构师或者建模师可以结合之前分层分域的成果,按层按域将模型设计任务进行拆解后分发给不同的人完成。我们通常可以这样拆分:ODS 层可以按源端类型拆分、DW 层可以按数据域分成多块、DM 层就按数据集市拆分。这样核心建模师只需要完成 DW 层即可,每人分别负责不同的数据域,ODS 层甚至可以分配给 ETL 工程师负责这样刚好顺便熟悉了源端存储结构以及对数据质量的探查,DM 层完全可以分配给 BI 工程师通常会开发成单表查询的模式。这样子做完分工后,在模型设计规范的统一指导和架构师或总建模师的协调下,相信最终是可以设计出一套统一完善且相互兼容的数仓模型的。
统一评审
虽然我们有完善的模型设计规范做指导,但考虑到各个部分建模者的不同情况,设计上难免会有疏漏,这就需要最终的统一评审环节。我们可以逐层分域的去评审,参与方主要有以下角色:架构师、总建模师、该模块主建模师、业务专家、数据运维、ETL 工程师。
交付与迭代
统一评审结束后,我们最终会形成一套完整的数据模型设计文档,通常是逻辑模型。
我们根据逻辑模型生成物理模型,然后交付给 ETL 工程师负责后续的数据开发。我们通常需要 ETL 工程师除了具备基本的开发能力外,还要有一定的数据探查、数据建模能力,确保在数据开发阶段能够发现原有模型设计的不足并及时反馈,比如现有模型如果使得 ETL 开发变的异常复杂或者程序性能低下,这时候通常就需要考虑修改模型设计了。我们经常使用的维度退化和宽表“模型”就是最常见的为了提高程序执行效率而做的规范化方面的妥协。
The End !
这里还有部分理论资料:数据仓库第四版、数据仓库工具箱、企业信息工厂、阿里大数据之路、DAMA 2.0 。
如有需要,本公众号对话框后台回复数字 1 即可获取。
扩展阅读:
数据仓库详细介绍(二.架构)
数据仓库详细介绍(三.规范)心法篇

数仓与大数据
体系化的总结归纳数据仓库相关知识、大数据相关知识,为广大圈内同仁,提供一套完备的学习资料。
公众号
留个微信,大家不妨交个朋友,共同交流。同时,欢迎关注、分享、转载。


若有收获,就点个赞吧
0 人点赞
