总体
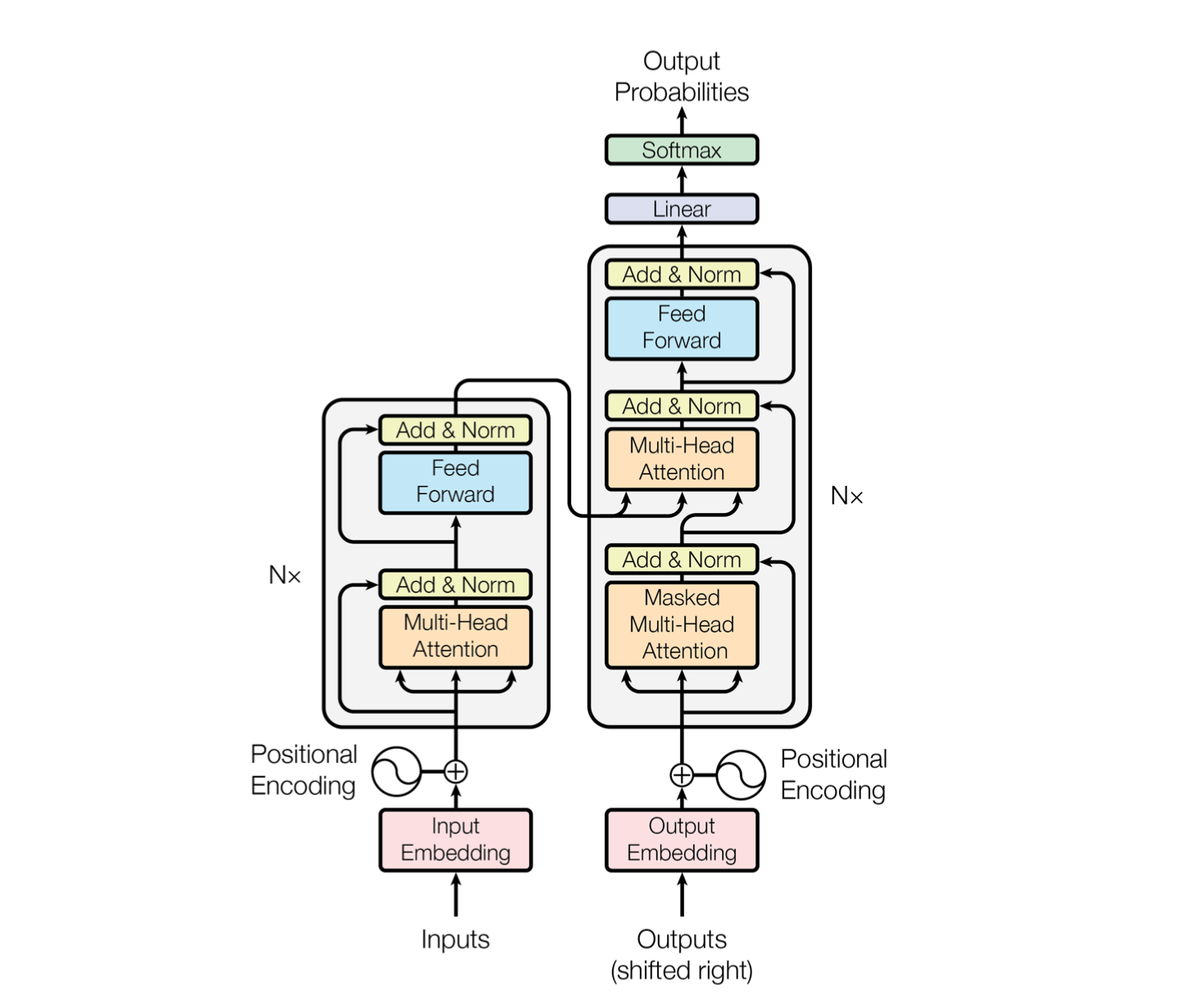
输入输出序列说明
输入序列 ,其中
,其中 为输入符号表中的序号。
为输入符号表中的序号。
输入句子长度为
目标序列 ,其中
,其中 为目标符号表中的序号。
为目标符号表中的序号。
目标句子长度M
输入词嵌入
输入序列词嵌入 ,其中,为输入序列长度,
,其中,为输入序列长度, 为词嵌入维度。
为词嵌入维度。
句子长度
每个单词 编码后长度
输入位置编码
- 词嵌入编码后,都还是整数 表达能力有限
- 维度和词嵌入编码相同
- 词嵌入编码 和 位置编码直接相加
- 输入

- 输入序列中输入符号对应的位置序号
- 就是单词的 位置序号
根据位置进行编码
其中
 为目标序列长度, 为词嵌入维度
为目标序列长度, 为词嵌入维度- 句子长度
- 单词编码后的维度





目标序列位置编码
- 目标位置编码


- 目标句子的长度
编码器Encoder
N x
- N 个编码器 堆叠
编码器结构:
- 第一层 输入来自词嵌入层 和 位置编码

- 后面的编码器层
- 前一层的输出是下一层的输入

- 每层输入、输出的形状

 编码器层
编码器层 编码器层数
编码器层数编码器层

输入向量序列

- 形状
- 形状
- 得到 查询向量 序列

- 形状
- 形状
- 得到 键向量 序列

- 形状
- 形状
得到 值向量 序列

- 形状
- 形状
输入线性层的
 就是
就是 
- 输入到 Scaled Dot-Product Attention 的 是 经过线性层之后的
- 形状还是
- nn.Linear(d_model, d_k * n_heads)
- 源码中的hidden_size 就是 d_model 嵌入层的维度
- 经过一个 head 将 d_model 转成 d_k 维度
- n个头 就是 d_k * n_heads维度
- 形状还是
- MatMul

- 是句子长度 词嵌入维度

- (batch_size, num_head, seq_len, head_size) (batch_size, num_head, head_size, seq_len) —>(batch_size, num_head, seq_len, seq_len)
- Scaled 值缩放 形状不变
- softmax 值转概率 形状不变
MatMul

- 形状

- 形状
由于encoder 堆叠的关系, 保持每层的输入 输出 维度相同

- 最后的输出是每个头的concat ,所以 设置每个头的输出维度

- 最后的输出是每个头的concat ,所以 设置每个头的输出维度


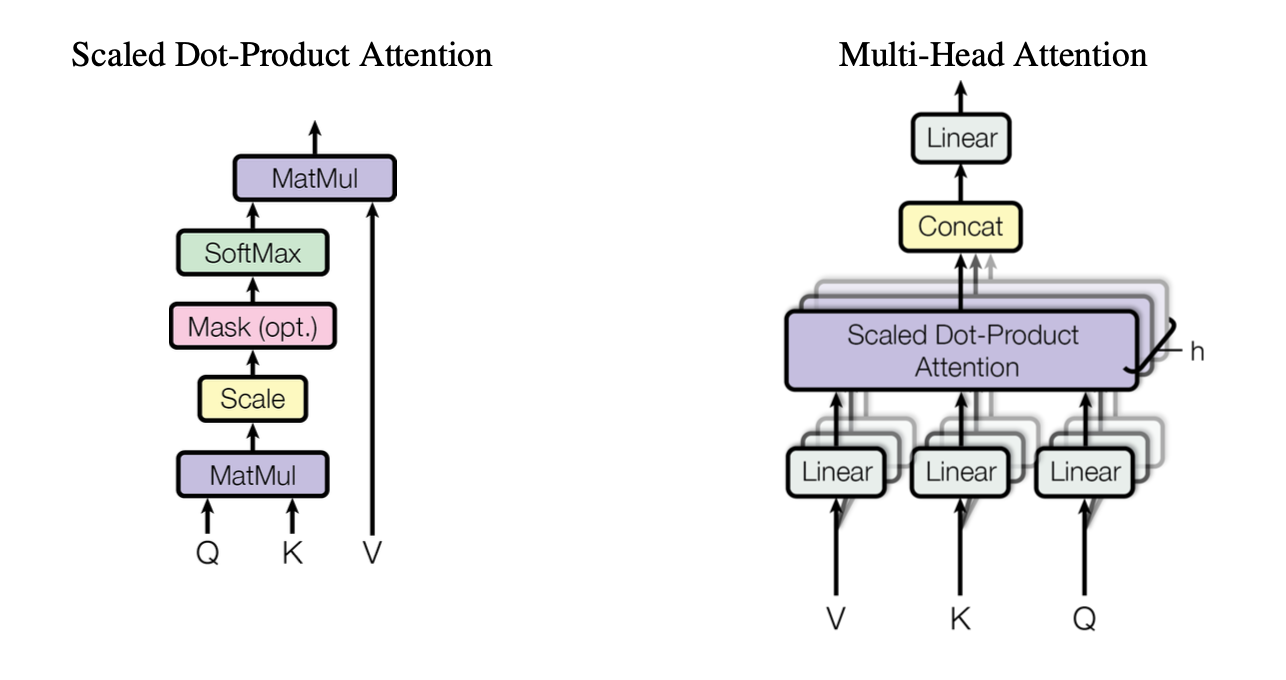
多头注意力机制

 最后输出Linear 的权重
最后输出Linear 的权重- 其中一个头

- 学习参数

编码器pad掩码
𝑒𝑛𝑐𝑝𝑎𝑑𝑚𝑎𝑠𝑘𝑗=(𝑒𝑗1,𝑒𝑗2,⋯,𝑒𝑗𝑝,⋯,𝑒𝑗𝑁)encpad_maskj=(ej1,ej2,⋯,ejp,⋯,ejN)
其中,
𝑒𝑗𝑝={𝑇𝑟𝑢𝑒,𝐹𝑎𝑙𝑠𝑒,𝑖𝑝=0𝑖𝑝≠0𝑗=1,2,⋯,𝑁ejp={True,ip=0False,ip≠0j=1,2,⋯,N
𝑒𝑛𝑐𝑝𝑎𝑑_𝑚𝑎𝑠𝑘∈ℝ𝑁×𝑁enc_pad_mask∈RN×N,𝑖𝑝ip为输入序列𝑖𝑛𝑝𝑢𝑡𝑠inputs对应位置序号。
前馈神经网络
𝐹𝐹𝑁(𝑒𝑚𝑖𝑑)=𝑅𝑒𝐿𝑈(𝑒𝑚𝑖𝑑𝑊1+𝑏1)𝑊2+𝑏2=max(0,𝑒𝑚𝑖𝑑𝑊1+𝑏1)𝑊2+𝑏2FFN(emid)=ReLU(emidW1+b1)W2+b2=max(0,emidW1+b1)W2+b2
其中,参数矩阵𝑊1∈ℝ𝑑𝑚𝑜𝑑𝑒𝑙×𝑑𝑓𝑓,𝑊2∈ℝ𝑑𝑓𝑓×𝑑𝑚𝑜𝑑𝑒𝑙W1∈Rdmodel×dff,W2∈Rdff×dmodel,偏置𝑏1∈ℝ𝑑𝑓𝑓,𝑏2∈ℝ𝑑𝑚𝑜𝑑𝑒𝑙b1∈Rdff,b2∈Rdmodel。

若有收获,就点个赞吧
0 人点赞
