安装包资源下载:https://pan.baidu.com/s/12_wLdpwCK0-3HLgXblhWCQ 提取码: 9r33
一、华为镜像下载
Elasticsearch: https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
logstash: https://mirrors.huaweicloud.com/logstash/?C=N&O=D
kibana: https://mirrors.huaweicloud.com/kibana/?C=N&O=D
ik:https://github.com/medcl/elasticsearch-analysis-ik/releases
cerebro: https://github.com/lmenezes/cerebro/releases
二、官方文档
es: https://www.elastic.co/cn/
kibana: https://www.elastic.co/cn/kibana
三、Elasticsearch版本
6.x & 7.x区别十分大
6.x的API(原生API,RestFul高级)
ES即搜索(百度、github、淘宝电商!)
四、学习大纲
- es相关安装
- 生态圈
- 分词器ik
- Restful操作ES
- CRUD
- SpringBoot集成ElasticSearch(原理集成)
- 案例:爬虫爬取数据
- 实战,模拟全文检索
五、ES历史相关(Google时代)
大数据两大问题:存储+计算
一个名叫Doug Cutting的美国工程师,做了一个用于文本搜索的函数库(软件的功能组件),命名为Lucene(Java编写)。Nutch是一个建立Lucene核心之上的网页搜索应用程序。
2003年,Google发表一篇技术学术论文,公开介绍了自己的谷歌文件系统GFS(Google File System),为了存储海量搜索数据而设计的专用文件系统。
2004年,Doug Cutting基于Google的GFS论文,实现了分布式文件存储系统,命令为NDFS(Nutch Distributed File System)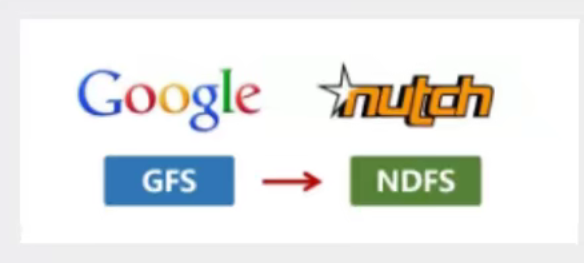
2004年,Google发表了一盘技术学术论文,介绍了自己的MapReduce编程模型,用于大规模数据集(大于1TB)并行分析运算。
2006年,Yohoo雅虎公司,招聘了Doug Cutting……..
Hadoop实际上是Doug Cutting他儿子的黄色玩具大象的名字,其logo就是一只奔跑的黄色大象。
2006年,Google发布了论文,介绍了分布式数据库存储系统 BigTable,用于处理海量数据的非关系型数据库,Doug Cutting在自己的Hadoop系统,又引入了BigTable,命名为HBase。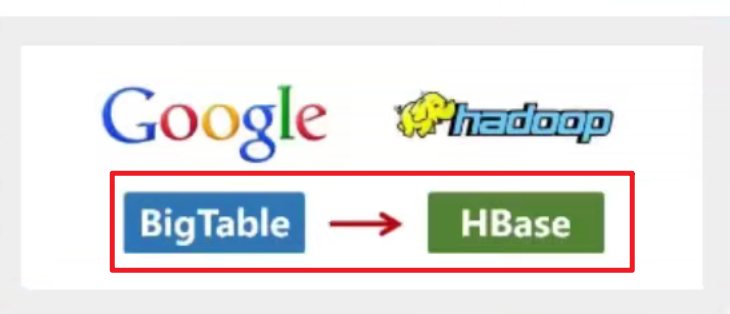
Hadoop基本都有Google影子…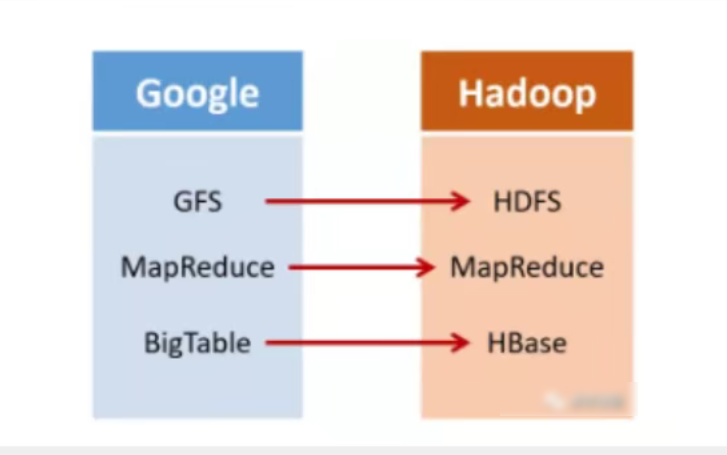
2008年1月,Hadoop成功上位,正式成为Apache基金会的顶级项目;
2008年2月,Yahoo宣布建立了一个拥有1w内核的Hadoop集群,将自己的搜索引擎产品部署在上面
2008年7月,Hadoop打破世界纪录,成为了最快排序1TB数据的系统,用时209S……
Lucence
Lucence是一套信息检索工具包(jar包),不包含搜索引擎系统
-索引结束
-读写索引的工具
-排序
-索引规则
-工具类
Lucence&ElasticSearch关系
ElasticSearch是基于Lucence做了一些封装和增强
六、Elasticsearch概述
Elasticsearch简称es,是一个开源的高扩展的分布式全文检索引擎,它可近乎实时的存储、检索数据,可以扩展百台服务器,处理PB级别(大数据时代)的数据。
es使用的Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,目的就是可以通过RestFul风格来隐藏Lucene的复杂性,从而使全文搜索变得简单。
七、ES & Solr的差别(性能比对)
7.1.ES
ElasticSearch是一个实时分布式搜索和分析引擎,它用于全文搜索、结构化搜索、分析以及将三者混合使用。
维基百科使用ElasticSearch提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou-type)和搜索纠错(did-you-mean)等搜搜建议功能。
StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。
Github使用ElasticSearch检索1300亿行的代码。
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论是在开源还是在专有领域,Lucene可被认为迄今为止最先进、性能最好的、功能最全的搜索引擎库。
Elasticsearch使用java开发并使用了Lucene作为核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RestFul API来隐藏Lucene的复杂性,从而让全文的搜索变得简单。
7.2.Solr
Solr是Apache下的一个顶级的开源项目,采用java开发,基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr索引的实现方法很简单,用POST方法向Solr服务器发送一个描述Field以及内容的XML文档,Solr根据xml文档添加、删除、更新索引。Solr搜索只需要发送Http GET请求,然后对Solr返回xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr基于Lucene开发企业级搜索服务器,实际上封装了lucene,Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件、生成索引;可以通过提出查找请求,并得到范湖返回结构。
7.3.lucene
在Java环境里lucene是一个成熟的免费的开源工具,就其本身而言,Lucene是当前以及最近几年最受欢迎的免费JAVA信息检索库。
Lucene是一个全文检索引擎的架构,全文搜索引擎本质就是搜索引擎,国外代表性的有Google、Fast/AllTheWeb、AltaVista、Inktomi、Teoma等,国内著名就是百度。他们都是通过从互联网上提取各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户。
7.4.ES VS Solr
(1)当单纯的对已有的数据进行搜索时,Solr更快。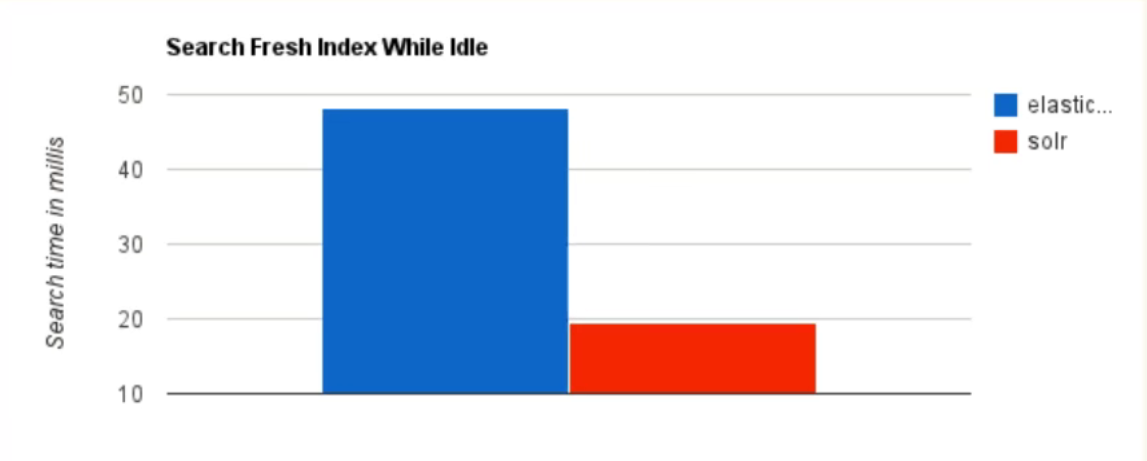
(2)当实时建立索引时,Solr会产生Io阻塞,查询性能较差,ElasticSearch据有明显的优势。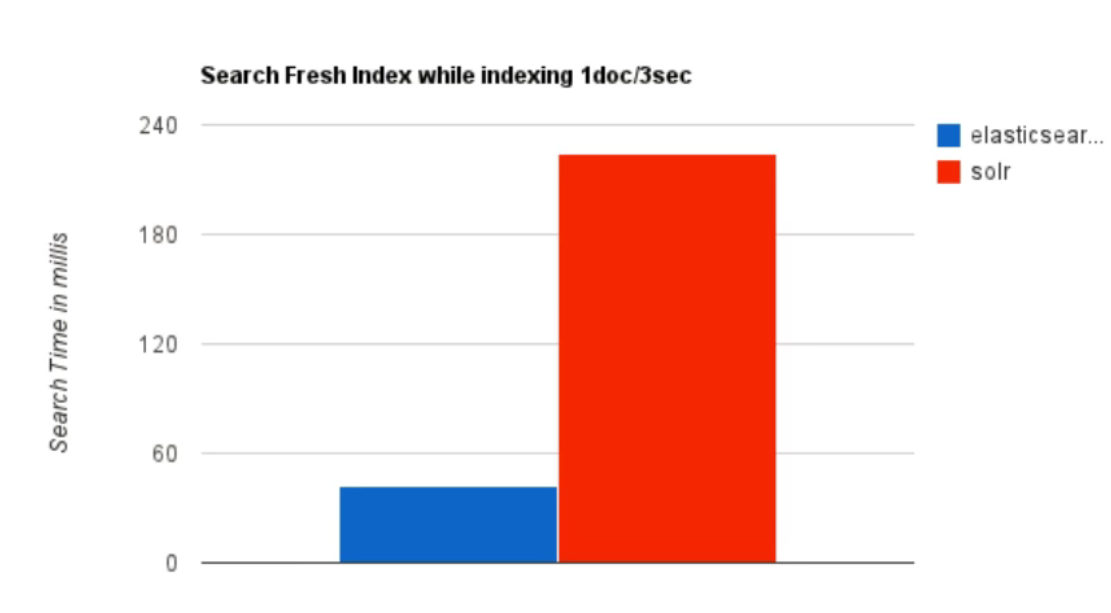 (3)随着数据量的增加,Solr的搜索效率会变得更低,而ElasticSearch却没有明显的变化。
(3)随着数据量的增加,Solr的搜索效率会变得更低,而ElasticSearch却没有明显的变化。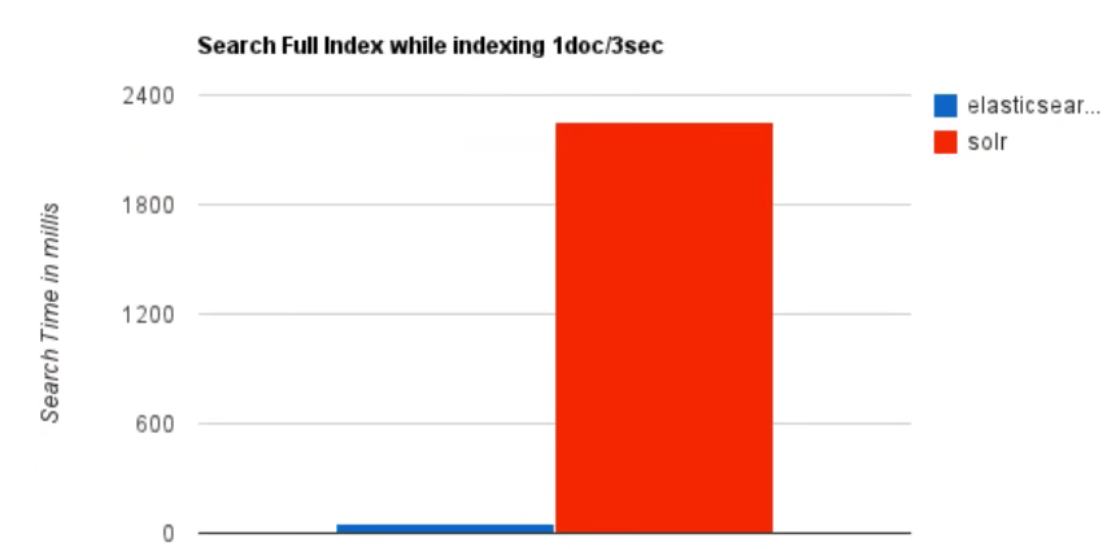
搜索基础设施转变后,Solr—>ElasticSearch,则50X提高性能性能!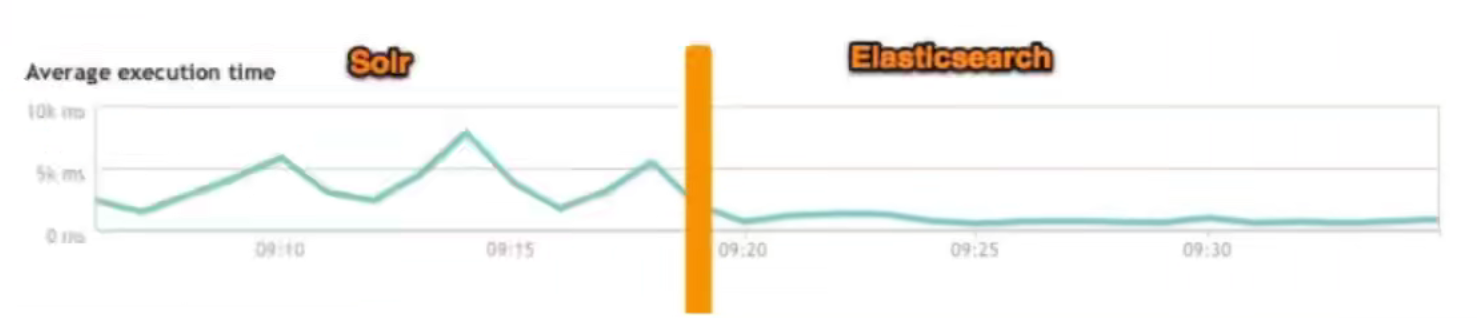
| 比对项 | Elasticsearch | Solr |
|---|---|---|
| 安装 | 开箱即用 | 相对复杂 |
| 管理 | 自带分布式协调管理功能 | 利用Zookeepr进行分布式管理 |
| 支持格式 | 仅支持Json格式 | 支持更多比如JSON、XML、CSV |
| 功能 | 注重核心功能、高级功能(三方插件提供,图形化界面Kibana支撑) | 官方提供更多 |
| 效率 | 建立索引快(查询慢) 适合于新兴的实时搜索应用 |
查询快,但是跟新索引时慢(插入删除慢) |
| 成熟 | 开发维护者较少、更新比较快,学习成本较高 | 有一个更大、更成熟的用户、开发和贡献者社区 |
八、Elasticsearch核心概念
ElastciSearch是面向文档的~
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types(7.x 8.x废弃) |
| 行(rows) | documents |
| 字段(columns) | fields |
elastcisearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又可以包含多个文档(行),每个文档中又可以包含多个字段(列)。
8.1物理设计
elasticsearch在后台把每个索引分为多个分片,每个分片可以在集群中的不同服务器间迁移。
8.2.逻辑设计
一个索引类型中,包含了多个文档,比如文档1、文档2。当索引一个篇文档时,需要通过 索引->类型->文档id 进行顺序查找。(id不必是整数,实际上它是个字符串)
索引和搜索数据的最小单位就是文档,文档中有几个重要的属性:
- 自我包含,一篇文档同时包含了字段和对应的值,同时包含了key:value
- 层次性,一个文档中包含了自文档(一个json对象,fastjson进行自动转换即可)
- 结构比较灵活,文档不依赖预先定义的模式,可以动态添加新的字段
8.2.1.字段类型(mapping)
在ES中,类型有时候称为映射类型。类型是文档的逻辑容器,就像关系数据库一种,表格是行的容器。类型中对于字段的定义称为映射。8.2.2.索引
索引时映射类型的容器,es中的索引时一个非常大的文档集合,索引存储了映射类型的字段和其他设置,然后存储在各个分片上。
一个集群之上有一个节点,一个节点就是es进程,节点可以有多个索引,如何创建索引,那么索引将会有5个分片(primary shard,又称为主分片)构成的,每一个主分片会有一个副本(replica shard,又称为复制分片)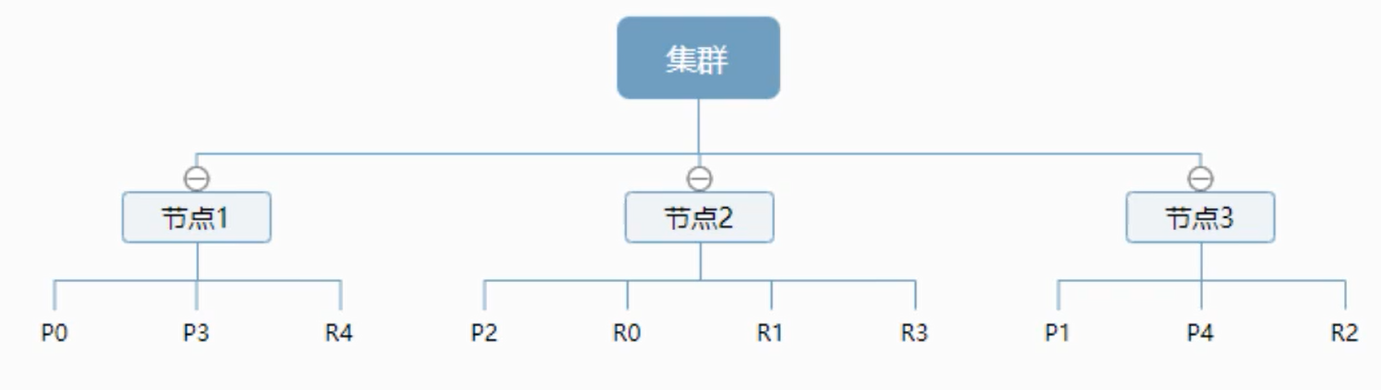
上面是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样发生了单点故障,数据则不会轻易丢失。一个分片就是一个lucene索引,一个包含了倒排索引的文件目录,倒排索引的结构使用es在不扫描全部文档的情况下,就能告诉你哪些文档包含了特定的关键。8.2.3.倒排索引
es使用的是一种称为倒排索引的结构,采用了lucene倒排索引作为底层,这种结构适用于快速的全文搜索。一个索引由文档中所有不同的列表构成,对于每一个词,都包含了它的文档列表。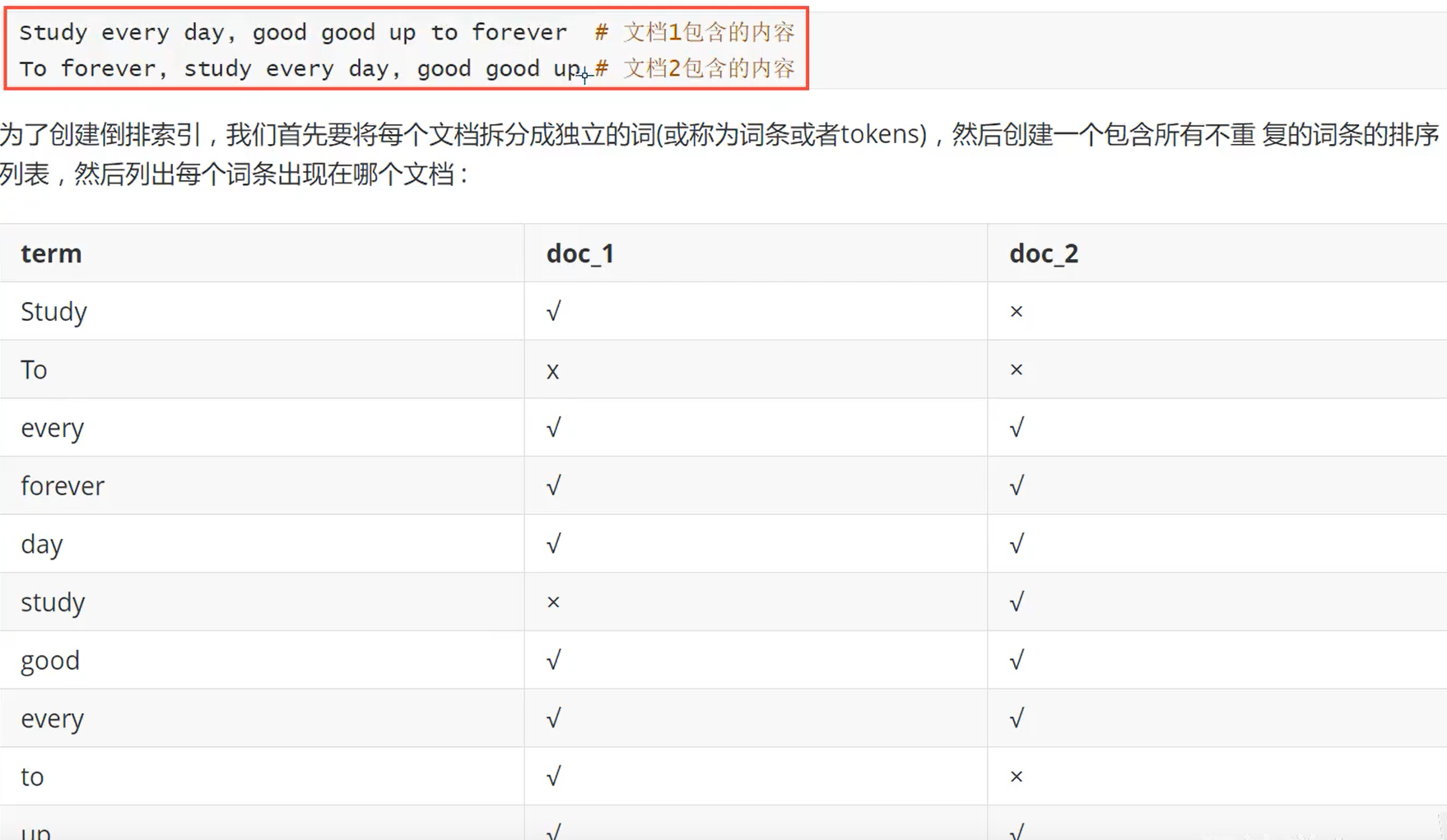
视图搜索to forever,只需要查看包含每个词条的文档~(权重score更高)
一个elasticsearch索引是由多个lucene组成!

若有收获,就点个赞吧
0 人点赞
