虚拟机规划
每个虚拟机1核两线程,4G内存,40G磁盘
| hadoop1 | hadoop2 | hadoop3 | hadoop4 | hadoop5 | |
|---|---|---|---|---|---|
| jdk8 | √ | √ | √ | √ | √ |
| NameNode | √ | ||||
| 2nn | √ | ||||
| DataNode | √ | √ | √ | √ | √ |
| ResourceManager | √ | ||||
| DataManager | √ | √ | √ | √ | √ |
| Hive | √ 客户端 | √ metastore | √ metastore | ||
| HiveServer2 | √ | ||||
| Hue | √ | ||||
| Flume | √ | ||||
| DataX | √ | ||||
| Airflow | √ | ||||
| Atlas | √ | ||||
| Griffin | √ | ||||
| impala | √ | √ | √ | √ | √ |
| MySQL | √ |
准备阶段
- 创建虚拟机hadoop1,配置静态ip192.168.80.101,克隆4台虚拟机,关闭防火墙,关闭selinux,配置ssh免密登录,同步时间
- 在hadoop2上安装mysql 用命名root 密码12345678,创建hive用户,密码12345678,授予远程登录权限
- 在hadoop1上安装Hadoop-2.9.2,配置hdfs集群,mapreduce集群,yarn集群,分发到其他集群
- 在hadoop2上安装hive,新建hive-site.xml,配值相关属性
- 在hadoop2上安装flume
- 在hadoop5上安装hue
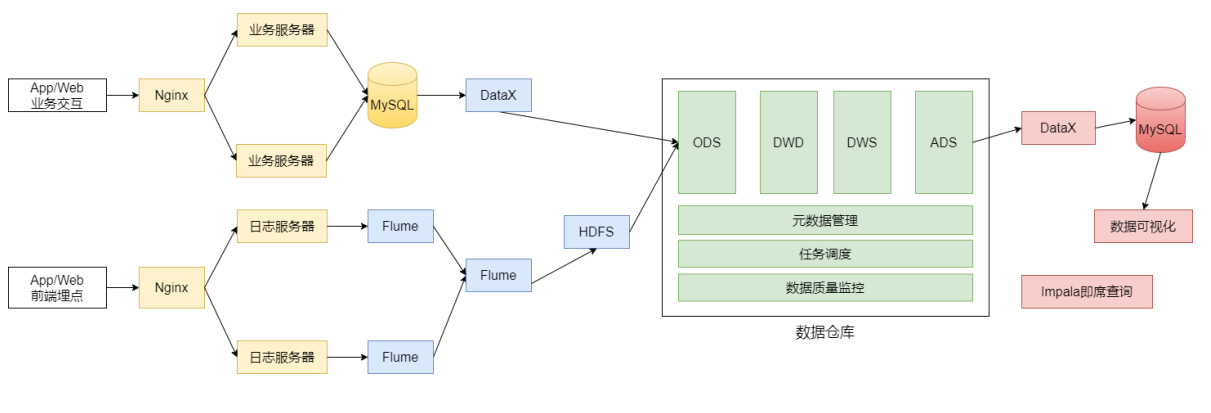
逻辑结构图
日志采集flume-ng agent --conf /opt/lagou/servers/flume-1.9/conf \--conf-file /data/lagoudw/conf/flume-log2hdfs3.conf -name a1 -Dflume.root.logger=INFO,console
- 问题
flume采集数据后,在hdfs查看文件大小不对,并且会报don’t find datanode from 的错误
- 原因
参考https://www.aboutyun.com//forum.php/?mod=viewthread&tid=11252&extra=page%3D1&page=1&
- Hadoop对正在写入的文件,不保证可见,当文件大小超过block size 后,这个block size的数据才可以被看到,后续大小小于block size的块也不能查看
- flume正在写入的文件默认会有.tmp后缀,如果flume配置的滚动方式只有文件大小,则当 文件较小时,一直是临时文件,这时对文件的查看是错误的,数据也是读取不到的,只有临时文件转为正式文件,存储在各个datanode上,才能正确读取
- 所以flume的滚动方式,除了设置rollSize,还应该设置rollInterval,保证经过一段时间后,临时文件会变成正式文件。由此带来的小文件问题,可以后续再合并。
dwd从ods加载数据
问题
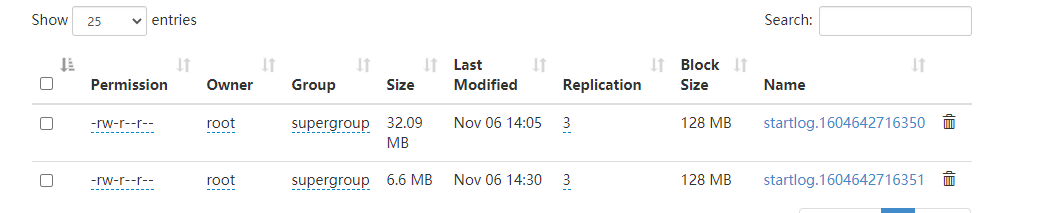
如果我的2020-07-21这个分区的文件是两个,就会报错,
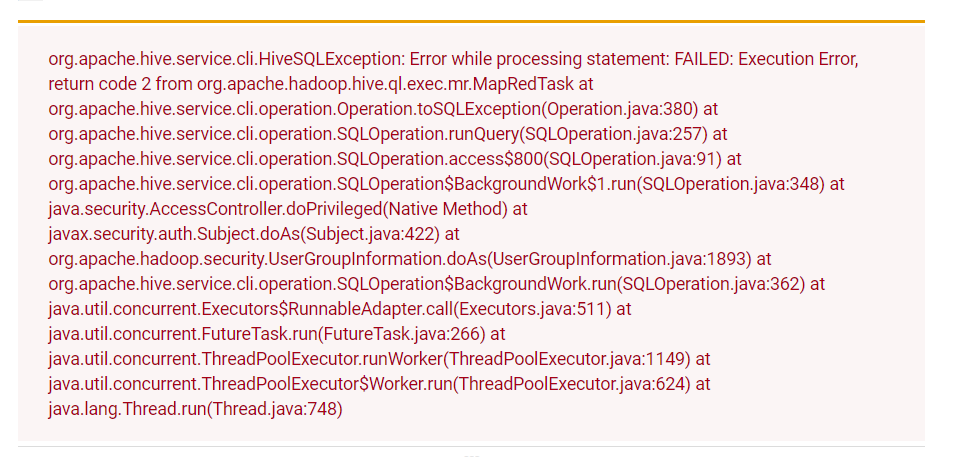
/tmp/root/hive.log
2020-11-07T11:42:20,829 INFO [Thread-37] mapred.LocalJobRunner: map task executor complete.2020-11-07T11:42:20,829 WARN [Thread-37] mapred.LocalJobRunner: job_local2060836000_0002java.lang.Exception: java.io.IOException: java.lang.reflect.InvocationTargetExceptionat org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:491) ~[hadoop-mapreduce-client-common-2.9.2.jar:?]at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:551) ~[hadoop-mapreduce-client-common-2.9.2.jar:?]Caused by: java.io.IOException: java.lang.reflect.InvocationTargetExceptionat org.apache.hadoop.hive.io.HiveIOExceptionHandlerChain.handleRecordReaderCreationException(HiveIOExceptionHandlerChain.java:97) ~[hive-exec-2.3.7.jar:2.3.7]
但如果只有一个文件,就可以执行
如果不使用with tmp as
创建一个过度表,可以执行
insert overwrite table dwd.dwd_test partition(dt='2020-07-23')select split(str,' ')[7] line FROM ods.ods_start_log where dt='2020-07-23';insert overwrite table dwd.dwd_start_log partition(dt='2020-07-23')selectget_json_object(str, '$.attr.device_id'),get_json_object(str, '$.attr.area'),get_json_object(str, '$.attr.uid'),get_json_object(str, '$.attr.app_v'),get_json_object(str, '$.attr.event_type'),get_json_object(str, '$.attr.os_type'),get_json_object(str, '$.attr.channel'),get_json_object(str, '$.attr.language'),get_json_object(str, '$.attr.brand'),get_json_object(str, '$.app_active.json.entry'),get_json_object(str, '$.app_active.json.action'),get_json_object(str, '$.app_active.json.error_code')from dwd.dwd_test where dt='2020-07-23';
原因还未找到
datax 导出数据
export_member_active_count.json
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/ads.db/ads_member_active_count/dt=$do_date/*",
"defaultFS": "hdfs://hadoop1:9000",
"column": [{
"type": "string",
"value": "$do_date"
}, {
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "replace",
"username": "hive",
"password": "12345678",
"column": ["dt", "day_count", "week_count", "month_count"],
"preSql": [
""
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop2:3306/dwads?useUnicode=true&characterEncoding=utf-8",
"table": [
"ads_member_active_count"
]
}]
}
}
}]
}
}
export_member_active_count.sh
#!/bin/bash
JSON=/data/lagoudw/script/member_active
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" $JSON/export_member_active_count.json
MySQL见表时需要注意,有时需要联合主键 PRIMARY KEY (dt,add_date)
核心交易数据分析
- 在MySQL创建数据库ebiz,执行sql脚本,插入业务数据
- 在hdfs创建对应的目录,在hive中创建对应的表
- 使用datax从MySQL导入hdfs。

若有收获,就点个赞吧
0 人点赞
