问题
es多个节点jvm heap 持续使用率超过80%,但是负载其实很低,参考https://elasticsearch.cn/article/361,做了Heap Dump分析,成功解决。
Heap Dump分析
下载MAT
由于head dump文件接近30个G,所以直接在服务器上进行第一次解析,然后下载索引文件和数据至本地查看。
所需工具 Eclipse MAT(分别下载 windows和linux版本),可以下载Stand-alone版本,无需安装eclipse即可使用,但是最低需要jdk11,若不想修改全局变量,可做如下修改
windows
## 修改配置文件MemoryAnalyzer.ini## 指定jdk路径-vmC:\Java\jdk-11.0.2\bin\javaw.exe-startupplugins/org.eclipse.equinox.launcher_1.6.200.v20210416-2027.jar--launcher.libraryplugins/org.eclipse.equinox.launcher.win32.win32.x86_64_1.2.200.v20210429-1609-vmargs-Xmx1024m
linux
## 修改ParseHeapDump.sh #export JAVA_HOME=/opt/soft/jdk/jdk1.8.0_66/ #export PATH=$JAVA_HOME/bin:$PATH "$(dirname -- "$0")"/MemoryAnalyzer -consolelog -application org.eclipse.mat.api.parse "$@"解析hprof文件
修改配置文件MemoryAnalyzer.ini
# 防止oom -Xmx10240m执行如下命令
mat/ParseHeapDump.sh [oom.prof] org.eclipse.mat.api:suspects mat/ParseHeapDump.sh [oom.prof] org.eclipse.mat.api:overview mat/ParseHeapDump.sh [oom.prof] org.eclipse.mat.api:top_components将生成的文件和oom.prof拷贝到本地,使用mat打开即可分析,也可以只下载三个分析报告的zip文件,解压后使用浏览器查看。
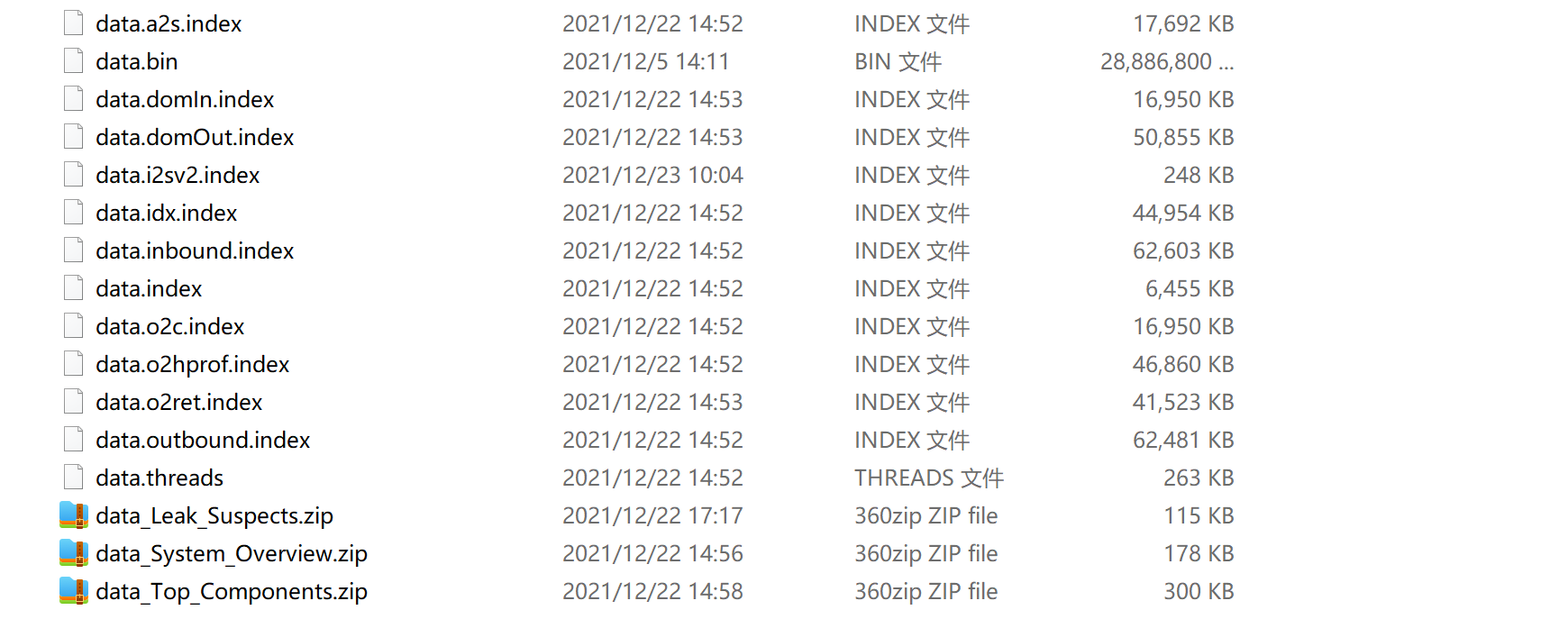
分析报告


可以看到大量org.apache.lucene.analysis.Analyzer$TokenStreamComponents 实列被缓存,不能释放
点击dominator_tree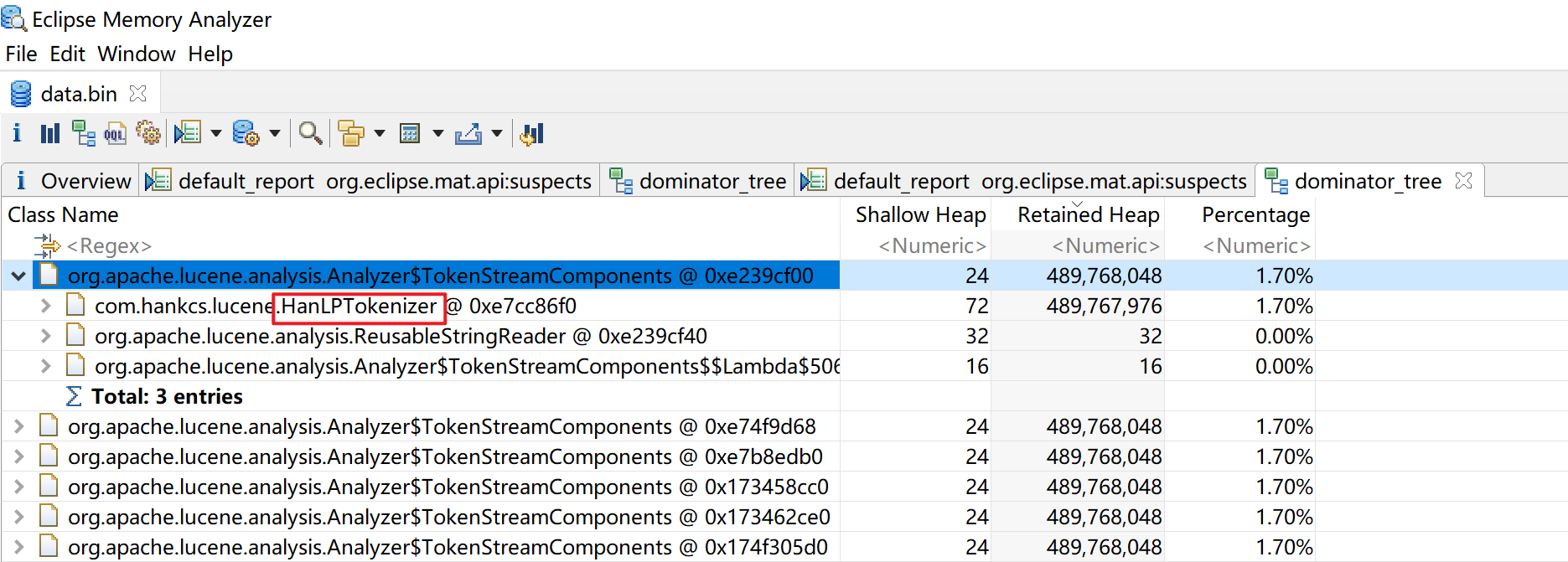
可以看到是HanLPTokenizer在调用,这是一个分词插件,鉴于应用主要使用的是ik分词器,如直接移除这个插件,重启es后,恢复正常。
参考文档
https://elasticsearch.cn/article/361
https://elasticsearch.cn/question/3183
https://www.cnblogs.com/zhangchiblog/p/14193311.html

若有收获,就点个赞吧
0 人点赞
