内存、函数、堆和栈
内存
我们的程序无时无刻不在跟内存打交道。在下面这个把 “hello world!” 赋值给 s 的简单语句中,就跟只读数据段(RODATA)、堆、栈分别有深度交互:let s = "hello world".to_string();
首先,“hello world” 作为一个字符串常量(string literal),在编译时被存入可执行文件的 .RODATA 段(GCC)或者 .RDATA 段(VC++),然后在程序加载时,获得一个固定的内存地址。当执行 “hello world”.to_string() 时,在堆上,一块新的内存被分配出来,并把 “hello world” 逐个字节拷贝过去。当我们把堆上的数据赋值给 s 时,s 作为分配在栈上的一个变量,它需要知道堆上内存的地址,另外由于堆上的数据大小不确定且可以增长,我们还需要知道它的长度以及它现在有多大。最终,为了表述这个字符串,我们使用了三个 word:第一个表示指针、第二个表示字符串的当前长度(11)、第三个表示这片内存的总容量(11)。在 64 位系统下,三个 word 是 24 个字节。
看下图,更直观一些:
栈
栈是程序运行的基础。每当一个函数被调用时,一块连续的内存就会在栈顶被分配出来,这块内存被称为帧(frame)。
我们知道,栈是自顶向下增长的,一个程序的调用栈最底部,除去入口帧(entry frame),就是 main() 函数对应的帧,而随着 main() 函数一层层调用,栈会一层层扩展;调用结束,栈又会一层层回溯,把内存释放回去
在调用的过程中,一个新的帧会分配足够的空间存储寄存器的上下文。在函数里使用到的通用寄存器会在栈保存一个副本,当这个函数调用结束,通过副本,可以恢复出原本的寄存器的上下文,就像什么都没有经历一样。此外,函数所需要使用到的局部变量,也都会在帧分配的时候被预留出来。

堆
栈虽然使用起来很高效,但它的局限也显而易见。当我们需要动态大小的内存时,只能使用堆,比如可变长度的数组、列表、哈希表、字典,它们都分配在堆上。
堆上分配内存时,一般都会预留一些空间,这是最佳实践。
比如你创建一个列表,并往里添加两个值:let mut arr = Vec::new();arr.push(1);arr.push(2);
这个列表实际预留的大小是 4,并不等于其长度 2。这是因为堆上内存分配会使用 libc 提供的 malloc() 函数,其内部会请求操作系统的系统调用,来分配内存。系统调用的代价是昂贵的,所以我们要避免频繁地 malloc()。
对上面的代码来说,如果我们需要多少就分配多少,那列表每次新增值,都要新分配一大块的内存,先拷贝已有数据,再把新的值添加进去,最后释放旧的内存,这样效率很低。所以在堆内存分配时,预留的空间大小 4 会大于需要的实际大小 2;
除了动态大小的内存需要被分配到堆上外,动态生命周期的内存也需要分配到堆上。
上文中我们讲到,栈上的内存在函数调用结束之后,所使用的帧被回收,相关变量对应的内存也都被回收待用。所以栈上内存的生命周期是不受开发者控制的,并且局限在当前调用栈。
而堆上分配出来的每一块内存需要显式地释放,这就使堆上内存有更加灵活的生命周期,可以在不同的调用栈之间共享数据。如下图所示: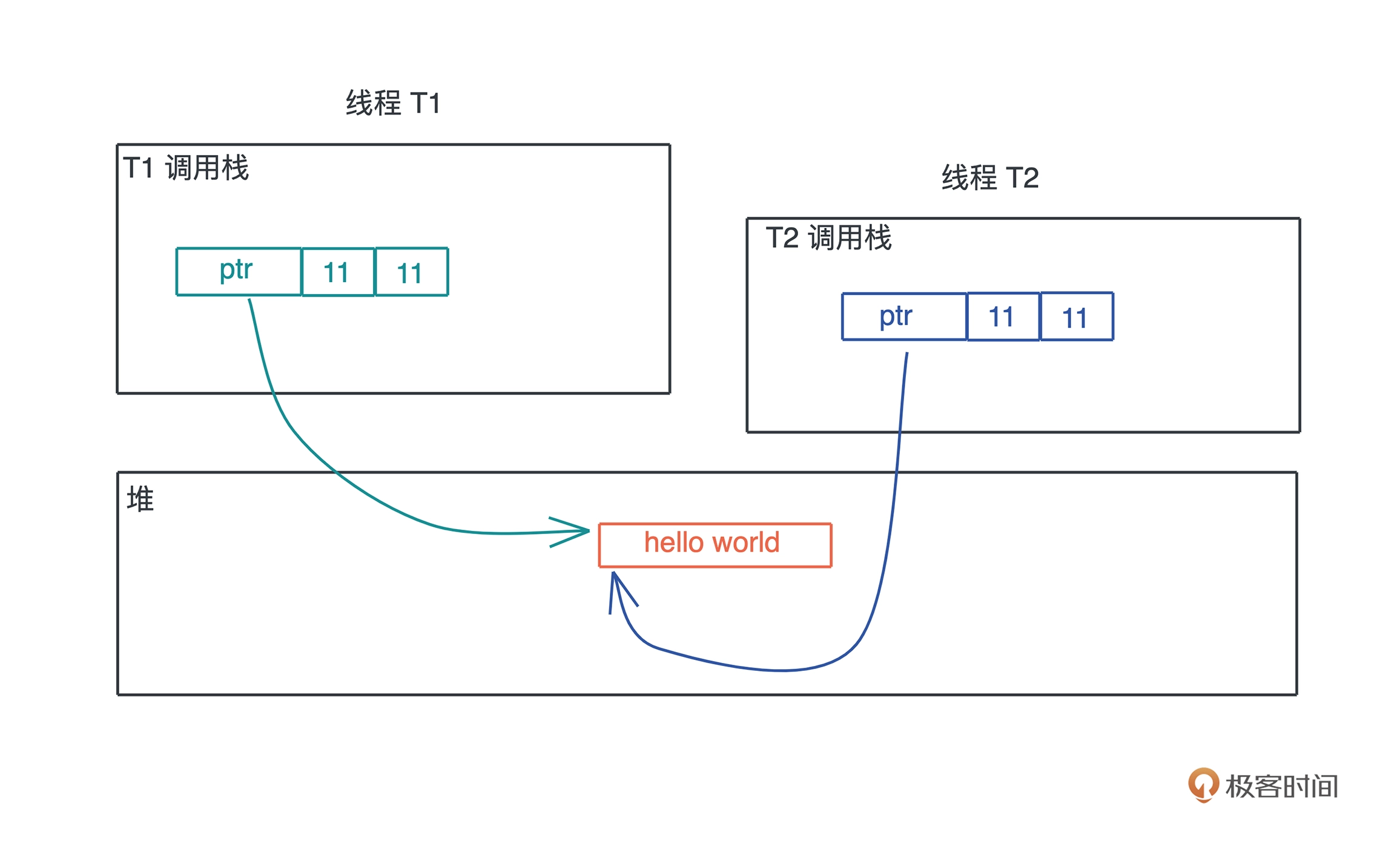
放堆上的问题然而,堆内存的这种灵活性也给内存管理带来很多挑战。如果手工管理堆内存的话,堆上内存分配后忘记释放,就会造成内存泄漏。一旦有内存泄漏,程序运行得越久,就越吃内存,最终会因为占满内存而被操作系统终止运行。如果堆上内存被多个线程的调用栈引用,该内存的改动要特别小心,需要加锁以独占访问,来避免潜在的问题。比如说,一个线程在遍历列表,而另一个线程在释放列表中的某一项,就可能访问野指针,导致堆越界(heap out of bounds)。而堆越界是第一大内存安全问题。
如果堆上内存被释放,但栈上指向堆上内存的相应指针没有被清空,就有可能发生使用已释放内存(use after free)的情况,程序轻则崩溃,重则隐含安全隐患。根据微软安全反应中心(MSRC)的研究,这是第二大内存安全问题。
GC、ARC 如何解决为了避免堆内存手动管理造成的这些问题,以 Java 为首的一系列编程语言,采用了追踪式垃圾回收(Tracing GC)的方法,来自动管理堆内存。这种方式通过定期标记(mark)找出不再被引用的对象,然后将其清理(sweep)掉,来自动管理内存,减轻开发者的负担。而 ObjC 和 Swift 则走了另一条路:自动引用计数(Automatic Reference Counting)。在编译时,它为每个函数插入 retain/release 语句来自动维护堆上对象的引用计数,当引用计数为零的时候,release 语句就释放对象。
小结
对于存入栈上的值,它的大小在编译期就需要确定。栈上存储的变量生命周期在当前调用栈的作用域内,无法跨调用栈引用。
堆可以存入大小未知或者动态伸缩的数据类型。堆上存储的变量,其生命周期从分配后开始,一直到释放时才结束,因此堆上的变量允许在多个调用栈之间引用。但也导致堆变量的管理非常复杂,手工管理会引发很多内存安全性问题,而自动管理,无论是 GC 还是 ARC,都有性能损耗和其它问题。
一句话对比总结就是:栈上存放的数据是静态的,固定大小,固定生命周期;堆上存放的数据是动态的,不固定大小,不固定生命周期。

若有收获,就点个赞吧
0 人点赞
