安装IK分词器
1.先下载ik分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases
2.我们将ik分词器上传到我们的es的plugins/ik目录下,ik文件夹需要我们自己创建
cd /usr/local/elasticsearch/plugins/ik/
unzip elasticsearch-analysis-ik-XX.zip
windos下安装也是一样的操作
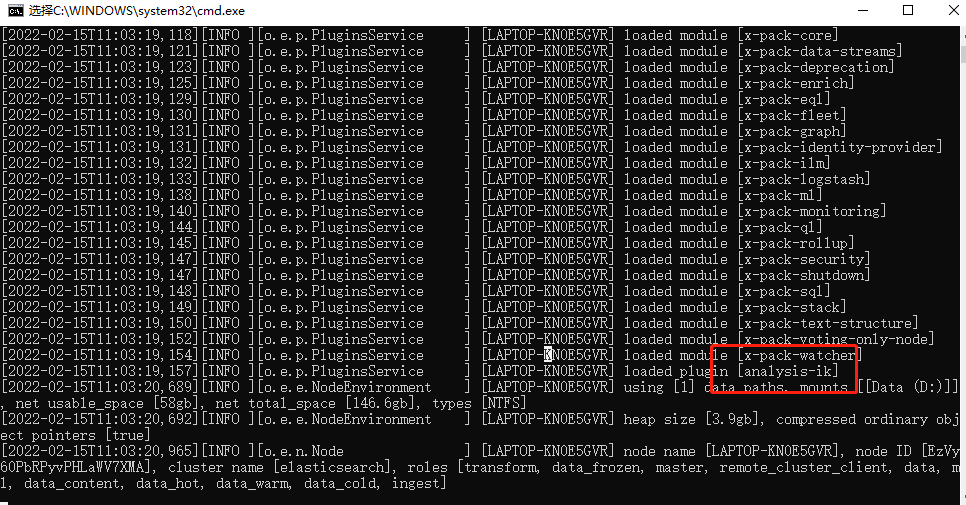
3.重启
重启的时候在日志中就可以看到关于IK分词器已经被加载进去了
测试分词器
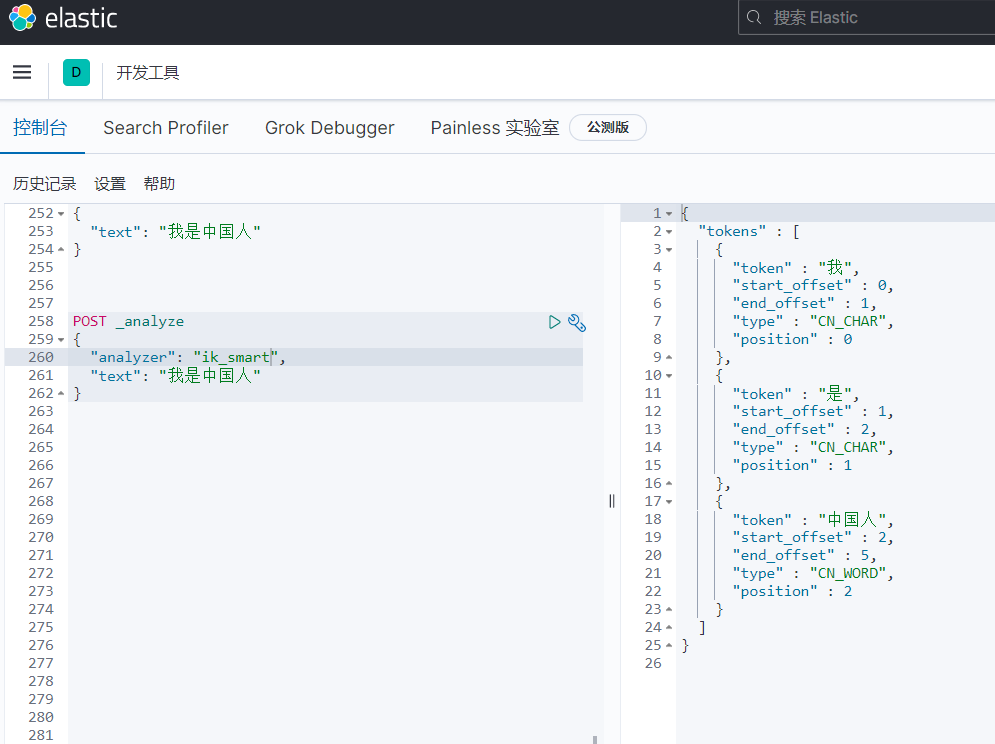
1.ik_smart
会做最粗粒度的拆分,比如会将“我是中国人”拆分为我、是、中国人。
dts
POST _analyze { “analyzer”: “ik_smart”, “text”: “我是中国人” }
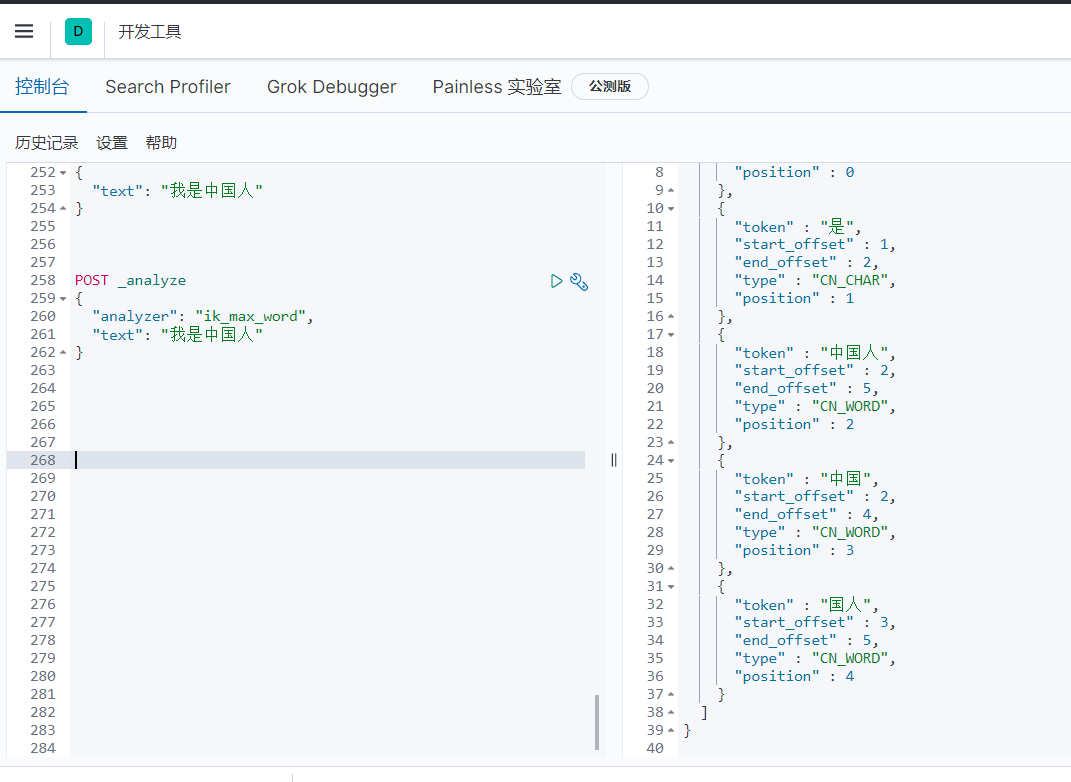
2.ik_max_word
会将文本做最细粒度的拆分,比如会将“我是中国人”拆分为“我、是、中华、中国人、中国、国人
dts
POST _analyze { “analyzer”: “ik_max_word”, “text”: “我是中国人” }
自定义词库
使用场景
在利用ik分词的过程中,当ik的分词规则不满足我们的需求了,这个时候就可以利用ik的自定义词库进行匹配,比如最火的常用的网络用语;我们输入乔碧罗殿下正常的情况下,是不会识别整个词语的,返回的都是分开的。我们识别整个词语就需要自定义词库
1、自定义词库方式一(新建dic文件)
(1)到elasticsearch/plugins中寻找ik插件所在的目录
(2)在ik中的config文件中添加词库
stata
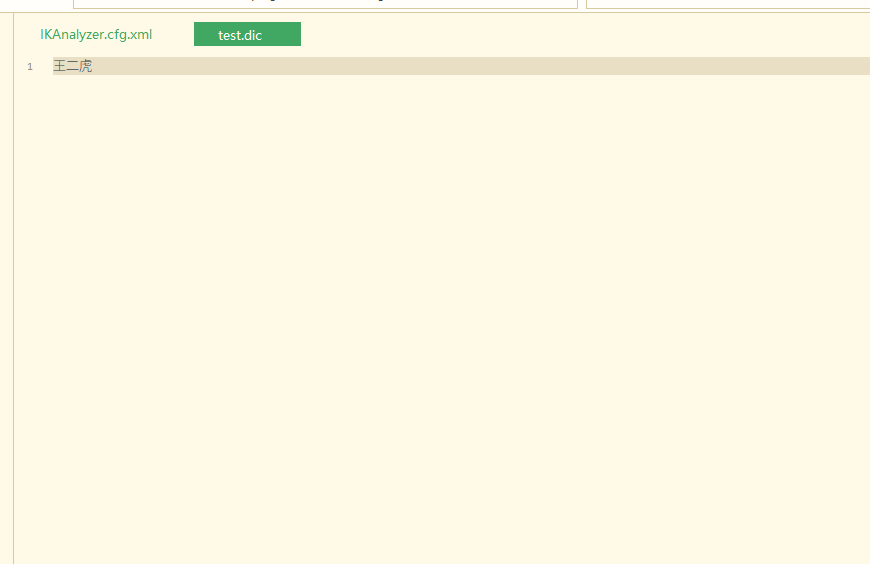
创建目录 mkdir ciku 创建文件 vim test.dic #编辑test.dic 注意每个词语一行
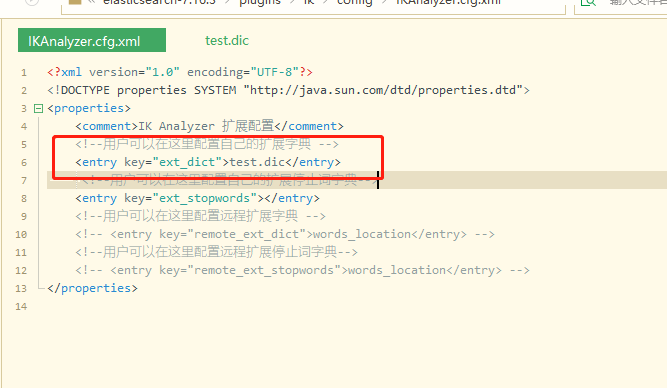
(3)修改ik配置
awk
vim /**/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
(4)重启ElasticSearch
效果
我们输入乔碧罗殿下正常的情况下,是不会识别整个词语的,返回的都是分开的。当我们在词库文件中写上乔碧罗殿下就会返回下面的效果

若有收获,就点个赞吧
0 人点赞
