MySQL的行锁是由数据库引擎实现的,但并不是所有的引擎都支持行锁,比如MyISAM引擎就不支持。不支持行锁控制并发就只能只用表锁,对于这种引擎的表,同一张表上任何时刻只能有一个更新在执行,这就会影响到业务并发度,这也是MyISAM被InnoDB替代的主要原因
行锁:顾明思义,就是针对表中行记录的锁。比如事务A更新了一行,这时候事务B也要更新这一行,就需要等待事务A提交完之后才能执行更新。
两阶段锁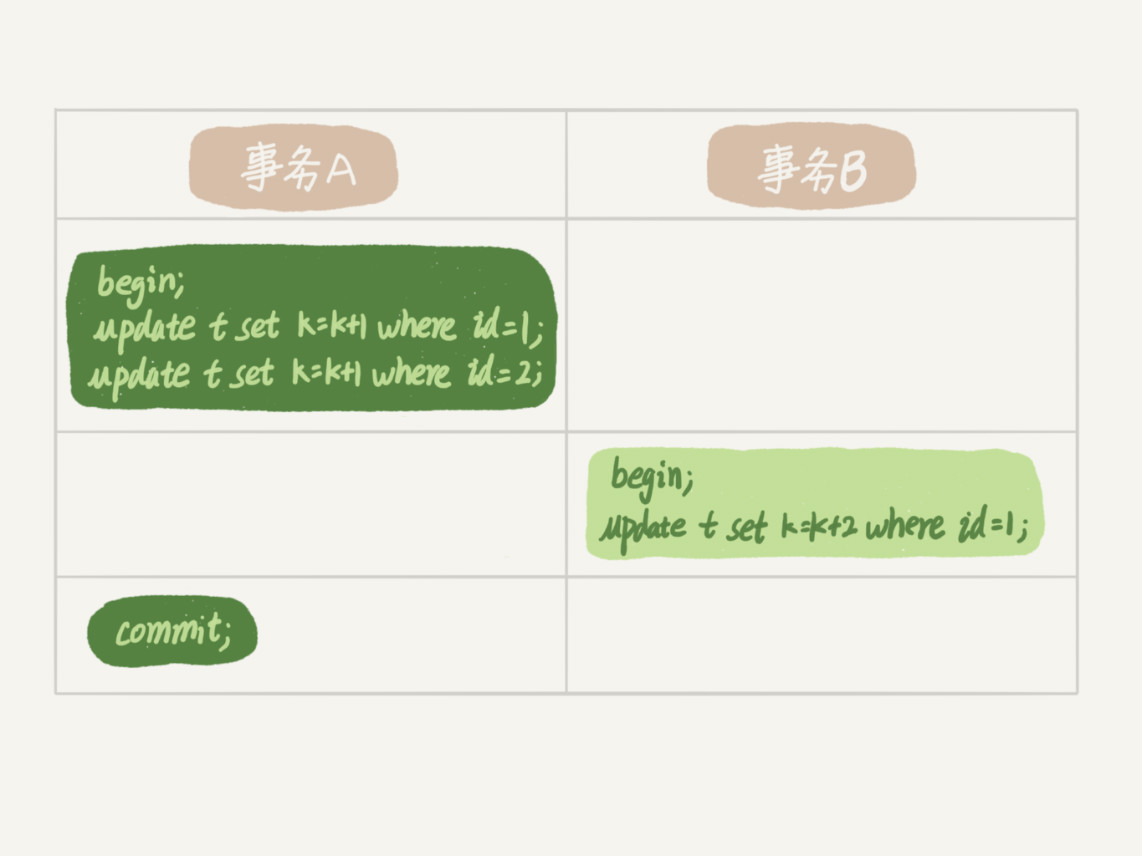
上边的图中,两个事务的执行情况是什么样的呢?
事实是事务A commit之前,事务B会被阻塞。也就是说事务A持有的两个记录的行锁都是在事务提交的时候才会释放。这就是两阶段锁协议。
在InnoDB中行锁是在需要的时候加上的,但并不是不需要了就立刻释放,而是在事务提交的时候才会释放,这就是两阶段锁协议
得出一个结论,当我们的一个事务执中需要锁多个行,那么我们要把最可能造成锁冲突的、最可能影响并发度的锁尽量往后放。
假设你负责实现一个电影票在线交易业务,顾客 A 要在影院 B 购买电影票。
我们简化一点,这个业务需要涉及到以下操作:
1、从顾客 A 账户余额中扣除电影票价;
2、给影院 B 的账户余额增加这张电影票价;
3、记录一条交易日志。
也就是说,要完成这个交易,
我们需要 update 两条记录,并 insert 一条记录。
当然,为了保证交易的原子性,我们要把这三个操作放在一个事务中。
那么,你会怎样安排这三个语句在事务中的顺序呢?
试想如果同时有另外一个顾客 C 要在影院 B 买票,那么这两个事务冲突的部分就是语句 2 了。因为它们要更新同一个影院账户的余额,需要修改同一行数据。根据两阶段锁协议,不论你怎样安排语句顺序,所有的操作需要的行锁都是在事务提交的时候才释放的。所以,如果你把语句 2 安排在最后,比如按照 3、1、2 这样的顺序,那么影院账户余额这一行的锁时间就最少。这就最大程度地减少了事务之间的锁等待,提升了并发度。
上边的情况是解决了,但是可能会由于某个特定的活动,使数据库挂掉,整个数据库每秒钟执行事务不超过100个。
死锁和死锁检测
当并发系统中多个线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源的时候,就会导致这几个线程都进入无限等待的状态,称为死锁。
举例: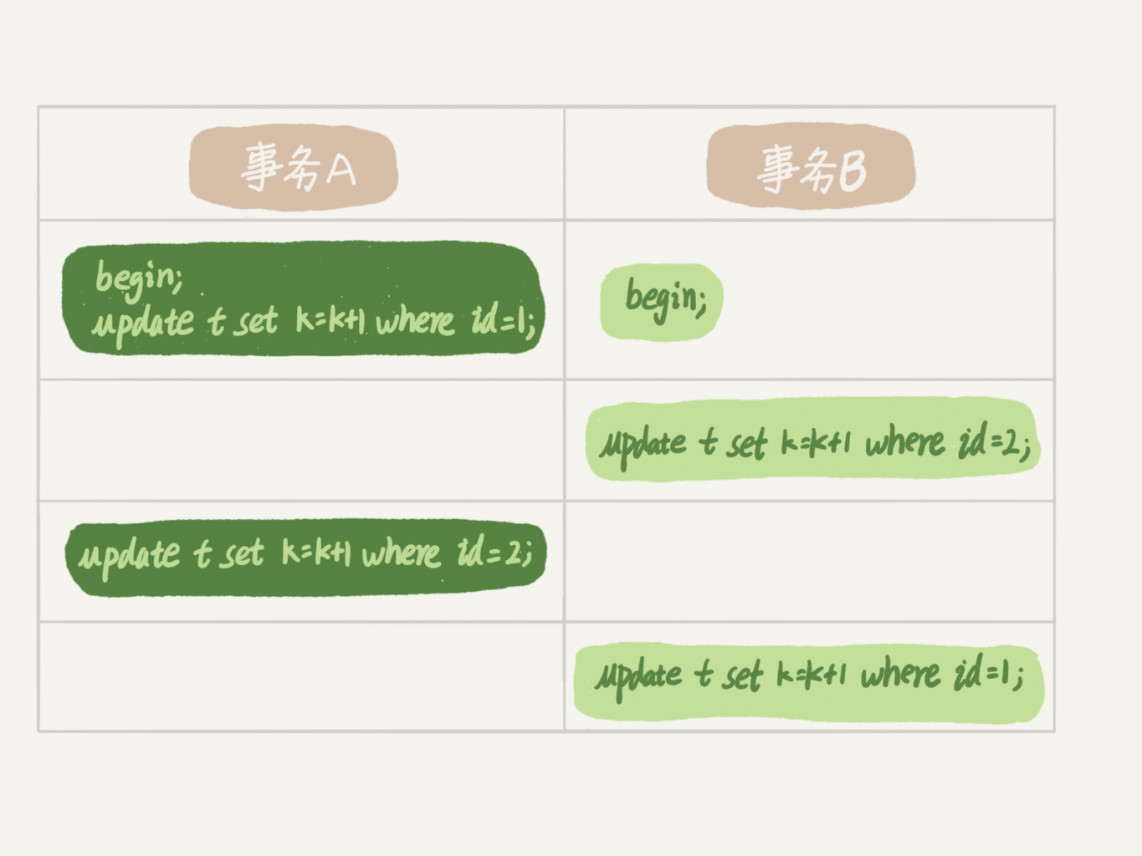
上边图中,
- 事务A在执行完第一条更新id=1语句之后,获得id=1的行锁
- 事务B执行更新id=2语句,获得id=2的行锁
- 事务A想要获得id=2的行锁,但是事务B还未提交,id=2的行锁还未释放,所以事务A被事务B阻塞
- 事务B执行更新id=1的语句,想要获得id=1的行锁,但是事务A由于被事务B阻塞因此不能提交,所以id=1的行锁还未释放,因此事务B被事务A阻塞,就发生了死锁。
出现死锁之后的两种策略
- 第一种,直接进入等待,直到锁超时。超时时间可以通过innodb_lock_wait_timeout来设置
- 第二种,死锁检测,发现死锁后,主动回滚发生死锁中的某一个事务,让其他事务得以执行。通过参数innodb_deadlock_detect=on来开启。
查看锁的超时时间 show global variables like 'innodb_lock_wait_timeout'
设置锁的超时时间
set global innodb_lock_wait_timeout=120 单位:秒
查看释放开启死锁检测
show global variables like 'innodb_deadlock_detect'开启、关闭死锁检测
SET GLOBAL innodb_deadlock_detect=TRUE/FALSE
innodb的默认锁超时时间是50s,意味着如果采用第一种策略,当发生死锁的时候,第一个执行的事务要等待50s之后才会超时退出,然后其他线程才可能继续执行。这个对于在线服务来说,这个等待时间往往是无法接受的。
但是我们也不能把这个超时时间设置为很小的值,这样出现死锁的时候,确实是可以很快的解开,但是如果不是死锁呢,而是简单的锁等待呢,可能会造成误杀。
所以正常情况下我们还是要采取第二种策略,即死锁检测,innodb的死锁检测默认是开启的,主动检测在发生死锁的时候,能快速发现并处理,但是也有额外的负担。
当每一个事务被锁住的时候,就要看看它锁依赖的线程有没有被锁住,如此循环,最后判断出释放出现了锁等待,也就是死锁。
死锁检测会有性能问题,耗费大量的CPU。
一种方法是,如果能确定业务不会发生死锁,可以临时把死锁检测关掉。但是有风险,可能会造成大量的超时。
另一种方法是,控制并发度,比如同一行最多只能有十个线程同时在更新,那么死锁检测的成本很低,就不会有性能问题。可以在客户端做并发控制。
问题
1.
两阶段锁的概念是什么? 对事务使用有什么帮助?
- 两阶段锁就是在执行sql语句的时候获得行锁,在事务提交的时候才会释放行锁,而不是不需要了就释放。
- 因此我们可以得到帮助就是,尽量把需要获得行锁的sql放在事务的后边,避免造成锁冲突,其他事务被阻塞。
2.
死锁的概念是什么? 举例说明出现死锁的情况.
- 当两个事务被互相阻塞的时候就发生了死锁
- 例A事务获得了id=1的行锁,事务B获得了id=2的行锁,事务B去获得id=1的行锁,事务B被事务A阻塞了等待事务A释放锁,然后事务A又要去获得id=2的行锁,被事务B阻塞了,两个事务互相阻塞,造成死锁
3.
死锁的处理策略有哪两种?
- 等待超时
- 死锁检测
4.
等待超时处理死锁的机制什么?有什么局限?
- 机制:当事务执行的时间超过innodb_lock_wait_timeout(默认50s)的时候自动回滚
- 局限:1:超时时间设置过长比如50s,第一个被阻塞的线程要等待50s才会超时退出,其他线程才有可能继续执行,这对于线上服务来说往往是不允许的;2: 超时时间果断比如1s,可能事务是正常等待锁,就被回滚了。
5.
死锁检测处理死锁的机制是什么? 有什么局限?
- 通过设置参数innodb_deadlock_detect=ON来开启死锁检测(默认开启)
- 机制,当一个事务被锁之后,判断它所依赖的线程有没有被阻塞,如此循环,最后判断出是否出现死锁,并主动回滚其中一条事务,使得其他事务得以继续执行。
- 局限,因为每个线程被阻塞的时候都需要循环的去判断它所依赖的线程是否被阻塞,如果同时有n个线程被阻塞,这个时间复杂度就是O(n)了。这期间会消耗大量的CPU资源,导致事务执行缓慢。
6.
有哪些思路可以解决热点更新导致的并发问题?
- 如果能保证业务不会出现死锁,可以把死锁检测关掉
- 控制并发度,在客户端做并发控制。

若有收获,就点个赞吧
0 人点赞
