DelayedWorkQueue是ScheduledThreadPoolExecutor自己内部实现的延迟队列, DelayedWorkQueue是一个基于堆的数据结构,类似于DelayQueue和PriorityQueue。在执行定时任务的时候,每个任务的执行时间都不同,所以 DelayedWorkQueue的工作就是按照执行时间的升序来排列,执行时间距离当前时间越近的任务在队列的前面(维护了一个小顶堆)
有关堆树的具体性质以及堆的插入、删除、堆化操作可以阅读之前的文章《堆树》
ScheduledThreadPoolExecutor中为什么要使用DelayedWorkQueue?
- 定时任务执行时需要取出最近要执行的任务,所以任务在队列中每次出队时一定要是当前队列中执行时间最靠前的,所以自然要使用优先级队列。
- DelayedWorkQueue是一个优先级队列,它可以保证每次出队的任务都是当前队列中 执行时间最靠前的,由于它是基于堆树结构的队列,根据堆树的性质:父节点小于(大于)其子节点,并且堆树结构在执行插入和删除操作时的最坏时间复杂度是 O(logN),堆树可以达到上述目的。
DelayedWorkQueue的属性

INITIAL_CAPACITY:初始化数组长度
queue:数组实现的队列,用来存放线程池提交过来的任务
size:数组元素个数
leader:执行队列头任务的leader线程
available:当较新的任务在队列的头部可用时或者新线程可能需要成为leader,则通过该 条件发出信号
// 初始化数组长度private static final int INITIAL_CAPACITY = 16;// 使用数组来储存线程池提交的任务private RunnableScheduledFuture<?>[] queue = new RunnableScheduledFuture<?>[INITIAL_CAPACITY];// 使用lock来保证多线程并发安全问题private final ReentrantLock lock = new ReentrantLock();// 队列中储存元素的大小private int size = 0;//特指队列头任务所在leader线程private Thread leader = null;//当较新的任务在队列的头部可用时,或者新线程可能需要成为leader,则通过该条件发出信号private final Condition available = lock.newCondition();
注意这里的leader,对于多线程的网络模型来说:所有线程会有三种身份中的一种:leader和follower,以及一个干活中的状态:proccesser。它的基本原则就是,永远最多只有一个leader。而所有follower都在等待 成为leader。线程池启动时会自动产生一个Leader负责等待网络IO事件,当有一个事 件产生时,Leader线程首先通知一个Follower线程将其提拔为新的Leader,然后自己 就去干活了,去处理这个网络事件,处理完毕后加入Follower线程等待队列,等待下 次成为Leader。这种方法可以增强CPU高速缓存相似性,及消除动态内存分配和线程间的数据交换。
入队方法
DelayedWorkQueue 提供了 put/add/offer 三个插入元素方法。与普通阻塞队列相比,这三个添加方法都是调用offer方法,那是因为它没有队列已满的条件,也就是说可以不断地向DelayedWorkQueue中添加元素,当元素个数超过数组长度时,数组会进行扩容。
public void put(Runnable e) {offer(e);}public boolean add(Runnable e) {return offer(e);}
offer()入队
我们来看一看offer()方法的具体实现
- 如果当前队列已满(size >= queue.length),调用grow()进行扩容
- 队列未满,size+1
- 判断添加的元素是否是第一个,是则不需要堆化
- 添加的元素不是第一个,则需要堆化siftUp
- 如果堆顶元素刚好是此时被添加的元素,则唤醒调用take()方法中被阻塞的线程消费
public boolean offer(Runnable x) {if (x == null)throw new NullPointerException();RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;final ReentrantLock lock = this.lock;lock.lock();try {int i = size;//队列已满,扩容50%if (i >= queue.length)grow();size = i + 1;//若队列为空,直接将任务放到队头if (i == 0) {queue[0] = e;setIndex(e, 0);//队列不为空,任务放入队列后需要进行堆化,重新调整为小顶堆} else {siftUp(i, e);}//堆顶任务刚好为添加的任务,则唤醒线程takeif (queue[0] == e) {leader = null;available.signal();}} finally {lock.unlock();}return true;}

grow()数组扩容
可以看出,扩容50%,扩容后的长度为原来的1.5倍
private void grow() {int oldCapacity = queue.length;int newCapacity = oldCapacity + (oldCapacity >> 1); // grow 50%if (newCapacity < 0) // overflownewCapacity = Integer.MAX_VALUE;queue = Arrays.copyOf(queue, newCapacity);}
siftup()堆化
新添加的元素先会加到当前数组的尾部,然后一步步和上面的父亲节点比较,若小于父亲节点则和父亲节点互换位置,循环比较直至大于父亲节点才结束循环。
- 获取数组最后一个节点的父节点下标
- 比较新插入节点的任务开始时间与其父节点的任务开始时间,若大于其父节点任务开始时间,则符合小顶堆的要求,直接退出
- 若不满足,则子节点与父节点互换位置
- 循环执行上面操作,直到该堆树满足小顶堆
根据key节点与它的父节点任务开始时间判断,如果key节点的执行时间小于父节点,则将两个节点交换,使执行时间靠前的节点排列在队列的前面。private void siftUp(int k, RunnableScheduledFuture<?> key) {while (k > 0) {//获取数组最后一个节点的父节点下标int parent = (k - 1) >>> 1;RunnableScheduledFuture<?> e = queue[parent];//比较新插入节点的任务开始时间与其父节点的任务开始时间,若大于其父节点任务开始时间,则符合小顶堆的要求,直接退出if (key.compareTo(e) >= 0)break;//否则父节点下移queue[k] = e;setIndex(e, k);k = parent;}//找到当前插入的位置queue[k] = key;setIndex(key, k);}
出队方法
DelayedWorkQueue 提供了以下几个出队方法
- take(),等待获取队列头元素
- poll() ,立即获取队列头元素
- poll(long timeout, TimeUnit unit) ,超时等待获取队列头元素
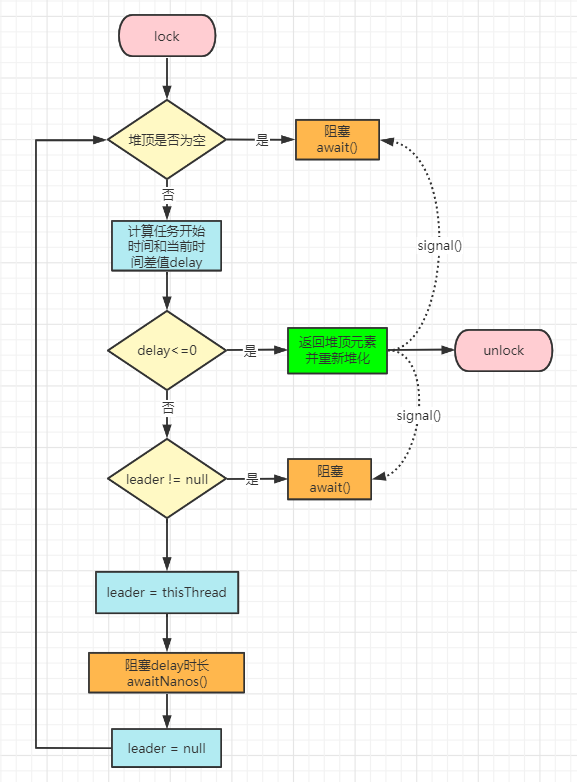
take()
Worker工作线程启动后就会循环消费阻塞队列中的任务,因为定时线程池的keepAliveTime=0,所以消费任务其只调用了DelayedWorkQueue的take()方法:
- 获取堆顶元素,判断堆顶元素是否是空,空的则阻塞线程 available.await(),放入条件等待队列中。
- 堆顶元素不为空,则获取任务开始执行时间delay,delay <= 0说明到了执行时间(执行时间小于当前时间),finishPoll()堆顶元素出队并重新堆化
- delay > 0还没到执行时间(执行时间大于当前时间),判断leader线程是否为空,不为空则说明有其他线程成为leader,等待执行下次堆顶中到来的新任务,当前线程将阻塞等待,直到leader执行完任务唤醒。
- leader线程为空,当前take线程设置为leader,并阻塞等待delay时长。
- 当前leader线程等待delay时长自动唤醒,放弃leader身份(leader = null),重新进行for循环再一次判断delay,重复上述操作
跳出循环后判断leader为空并且堆顶元素不为空,则唤醒其他take线程,最后是否锁。
public RunnableScheduledFuture<?> take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {for (;;) {//获取队头任务RunnableScheduledFuture<?> first = queue[0];//如果任务为空,则放入条件等待队列中if (first == null)available.await();else {//获取任务的执行时间long delay = first.getDelay(NANOSECONDS);//如果delay<=0,说明任务开始执行时间小于当前时间,返回堆顶任务,重新堆化if (delay <= 0)return finishPoll(first);first = null;//leader线程不为空,则说明有其他线程已经成为leader,等待下次执行任务,当前线程阻塞if (leader != null)available.await();//leader线程为空,将当前线程设置为leader线程else {Thread thisThread = Thread.currentThread();leader = thisThread;try {//阻塞等待delay时长available.awaitNanos(delay);//线程唤醒后让出leader身份,可以去获取任务} finally {if (leader == thisThread)leader = null;}}}}} finally {if (leader == null && queue[0] != null)//唤醒被阻塞的线程available.signal();lock.unlock();}}
线程具体如何进入条件等待队列进行阻塞和被唤醒,可以看我之前的文章《阻塞队列-ArrayBlockingQueue》
leader线程的作用:
当一个线程变成leader线程时,只需要等待下一次的延迟时间,而不是leader线程的其他线程被阻塞,需要等leader线程执行完任务才唤醒其他被阻塞的线程。
举例来说,如果没有leader,那么在执行take()时,都要执行available.awaitNanos(delay),假设当前线程执行了该段代码,这时还没有signal,第二个线程也执行了该段代码,则第二个线程也要被阻塞。多个这时执行该段代码是没有作用的,因为只能有一个线程会从take中返回queue[0](因为有lock),其他线程这时再返回for循环执行时取的queue[0],已经不是之前的queue[0]了,然后又要继续阻塞。
finishPoll()
堆顶元素出堆,具体方法是将数组的第一个元素和最后一个元素互换位置,然后向下进行堆化
private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {int s = --size;RunnableScheduledFuture<?> x = queue[s];queue[s] = null;if (s != 0)siftDown(0, x);setIndex(f, -1);return f;}
从根节点开始向下堆化
private void siftDown(int k, RunnableScheduledFuture<?> key) {int half = size >>> 1;while (k < half) {//获取孩子节点int child = (k << 1) + 1;RunnableScheduledFuture<?> c = queue[child];int right = child + 1;//选出最小的孩子节点if (right < size && c.compareTo(queue[right]) > 0)c = queue[child = right];//若父节点小于孩子节点,堆化完成,跳出循环if (key.compareTo(c) <= 0)break;//父节点向下调整queue[k] = c;setIndex(c, k);//设置新的parent,开始下一轮堆化k = child;}//找到堆顶元素插入的位置queue[k] = key;setIndex(key, k);}
例如数组 {3, 5, 6, 7, 10, 12, 8},要删除根节点3,首先与尾节点交换位置,删除尾节点
依次向下调整直到符合堆树条件
poll()
立即获取队列头元素,当队列头任务是null,或者任务延时时间没有到,表示这个任务还不能返回,因此直接返回null。否则调用finishPoll方法,返回堆顶元素并重新堆化。
public RunnableScheduledFuture<?> poll() {final ReentrantLock lock = this.lock;lock.lock();try {RunnableScheduledFuture<?> first = queue[0];if (first == null || first.getDelay(NANOSECONDS) > 0)return null;elsereturn finishPoll(first);} finally {lock.unlock();}}
poll(long timeout, TimeUnit unit)
超时等待获取队列头元素,与take方法相比较,就要考虑设置的超时时间,如果超时时间到了,还没有获取到有用任务,那么就返回null。其他的与take方法中逻辑一样。
public RunnableScheduledFuture<?> poll(long timeout, TimeUnit unit)throws InterruptedException {long nanos = unit.toNanos(timeout);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {for (;;) {RunnableScheduledFuture<?> first = queue[0];// 如果没有任务。if (first == null) {// 超时时间已到,那么就直接返回nullif (nanos <= 0)return null;else// 否则就让线程在available条件下等待nanos时间nanos = available.awaitNanos(nanos);} else {// 获取任务的剩余延时时间long delay = first.getDelay(NANOSECONDS);// 如果延时时间到了,就返回这个任务,用来执行。if (delay <= 0)return finishPoll(first);// 如果超时时间已到,那么就直接返回nullif (nanos <= 0)return null;// 将first设置为null,当线程等待时,不持有first的引用first = null;// 如果超时时间小于任务的剩余延时时间,那么就有可能获取不到任务。// 在这里让线程等待超时时间nanosif (nanos < delay || leader != null)nanos = available.awaitNanos(nanos);else {Thread thisThread = Thread.currentThread();leader = thisThread;try {// 当任务的延时时间到了时,能够自动超时唤醒。long timeLeft = available.awaitNanos(delay);// 计算剩余的超时时间nanos -= delay - timeLeft;} finally {if (leader == thisThread)leader = null;}}}}} finally {if (leader == null && queue[0] != null)// 唤醒等待任务的线程available.signal();lock.unlock();}}
总结
使用优先级队列DelayedWorkQueue,保证添加到队列中的任务,会按照任务的延时时间进行排序,延时时间少的任务首先被获取。
- DelayedWorkQueue的数据结构是基于堆树实现的,内部维护了一个小顶堆
- DelayedWorkQueue采用数组实现堆,根节点出队,用最后叶子节点替换,然后下推至满足堆成立条件;最后叶子节点入队,然后向上推至满足堆成立条件;
- DelayedWorkQueue添加元素满了之后会自动扩容原来容量的1/2,即永远不会阻塞,最大扩容可达Integer.MAX_VALUE,所以线程池中至多有corePoolSize个工作线程正在运行;
- DelayedWorkQueue 消费元素take,在堆顶元素为空和delay >0 时,阻塞等待;
- DelayedWorkQueue 是一个生产永远不会阻塞,消费可以阻塞的生产者消费者模式;
- DelayedWorkQueue 有一个leader线程的变量,是Leader-Follower模式的变种。当一个take线程变成leader线程时,只需要等待下一次的延迟时间,而不是leader线程的其他take线程则需要等leader线程出队列了才唤醒其他take线程。

若有收获,就点个赞吧
0 人点赞
