概述
ZooKeeper 用于 Client 和 Zab 或 Raft 之间的协调功能。即Client 向 ZooKeeper 发送读或写操作,ZooKeeper 再将操作应用到 Raft 内。
ZooKeeper 主要的工作负载为读操作。
为了提高性能 Client 会缓存集群的元数据。为了避免数据更新导致的不一致,Client 可以 watch 一个对象,当对象更新时,Client 会收到提醒。
1,数据结构
ZooKeeper 有一个层级的目录结构。因为 ZooKeeper 会被多个不相关的服务共享使用,因从需要使用命名系统来区分不同的服务信息。
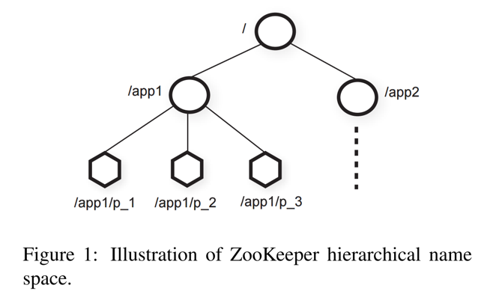
Client 可以创建两种 Znode:
- Regular Znodes:一旦创建,便永久存在,直至删除
- Ephemeral Znodes:一旦 ZooKeeper 认为创建它的 Client 断开连接,便会直接删除。因此 Client 需要发送心跳信息给 ZooKeeper 。
另外创建时可以设置 Sequential flag,其创建的结点名称后会增加一个递增计数器的值,为了避免重名。
每一个 Znode 都有一个版本号,随着 Znode 的修改而提高
client 连接到 ZooKeeper 后会初始化session。其具有关联性的 tiemout,若在 timeout 内收不到来自Client 的信息,ZooKeeper 会认为 Client 故障。Client 也可以关闭连接。
watches 是被关联到 session 的一次性触发器,一旦触发或 session 关闭,将会直接注销。
2,Client API
CRATE(PATH, DATA, FLAG):创建 Znode。若存在相同的PATH返回错误。DELETE(PATH, VERSION):若VERSION与 Znode 的版本号与一致时删除。EXIST(PATH, WATCH): 判断 Znode 是否存在,WATCH标志可以设置 watch(是否存在都可以设置)。GETDATA(PATH, WATCH):WATCH标志可以在 Znode 存在时设置 watch。SETDATA(PATH, DATA, VERSION):若VERSION与 Znode 的版本号与一致时更新。getChildren(path, watch):返回路径下的子节点集合。sync(path):等待操作开始时所有没有同步的更新传播到 client 连接到的服务器。 该 path 当前被忽略。
所有的方法在 API 中都有一个同步版本和一个异步版本。异步API使应用程序可以并行执行多个未完成的 ZooKeeper 操作和其他任务。ZooKeeper client 保证按顺序调用每个操作的相应回调。
若 VERSION 为 -1 时不执行检查。若不一致,出现 **unexpected version error**
3,一致性保证
因为在 Raft 只有 Leader 才有最新的日志,因此要想满足线性一致性条件,那么请求只能发往 Leader 所在的 Server。因此当集群中服务器增多时,Leader的负担更大。
ZooKeeper 放弃了线性一致性,使得全部操作不会在 Leader 中进行。
ZooKeeper 的一致性保证为:
- ZooKeeper 保证写请求是线性一致性的,其写请求只会发送给 Leader。
- 对于任意一个客户端的请求,ZooKeeper 保证按顺序执行,称为 FIFO 客户端序列。
对于读请求,ZooKeeper 不需要发给 Leader,但是保证读取到的序列是递增的。因此对于单个 Client 的请求而言,是线性一致性的。
其实现为:Leader 会给 Log 条目标上 zxid,即 Log 对应的条目号。若 Client 上一个请求读取的 Server 最后日志的 zxid为 idx ,后续发送的请求读取的 Server 最后日志的 zxid 要 大于等于 idx 。客户端通过记录最新的 zxid 实现。
因此对于 Sync 操作,其会发送给 Leader,读取最新的状态信息给 Client。避免了两台 Client 共享同一配置,对应的 ZooKeeper 副本进度不一致的问题。类似于 flush。
对于更新 Znode,其操作需要:
- 更改配置时,其他 Client 不允许使用正在更改的配置。
- 若在配置完成更新前宕机,其他 Client 不允许使用半更新的配置。
其根据 Znode 的存在实现,需要更新配置时
- 删除某一Ready file
- 等待 ZooKeeper 更新全部保存了配置的 Znode
- 再次创建 Ready file,表示完成
同时 Client 在读取配置前,需要检测 Znode 是否存在和 watch 。
4,配置管理
ZooKeeper 将 Zr 作为 Client 的启动参数设置,当 Client 加入 ZooKeeper 中会首先读取并更新 Zr 下的配置数据。
使用 ephemeral 节点创建 Client 的状态信息(session),其会放在 Zr 下。当 Client 断开时,其对应的 Znode 会自动删除。
实现
ZooKeeper通过在组成服务的每台服务器上复制 ZooKeeper 数据来提供高可用性。
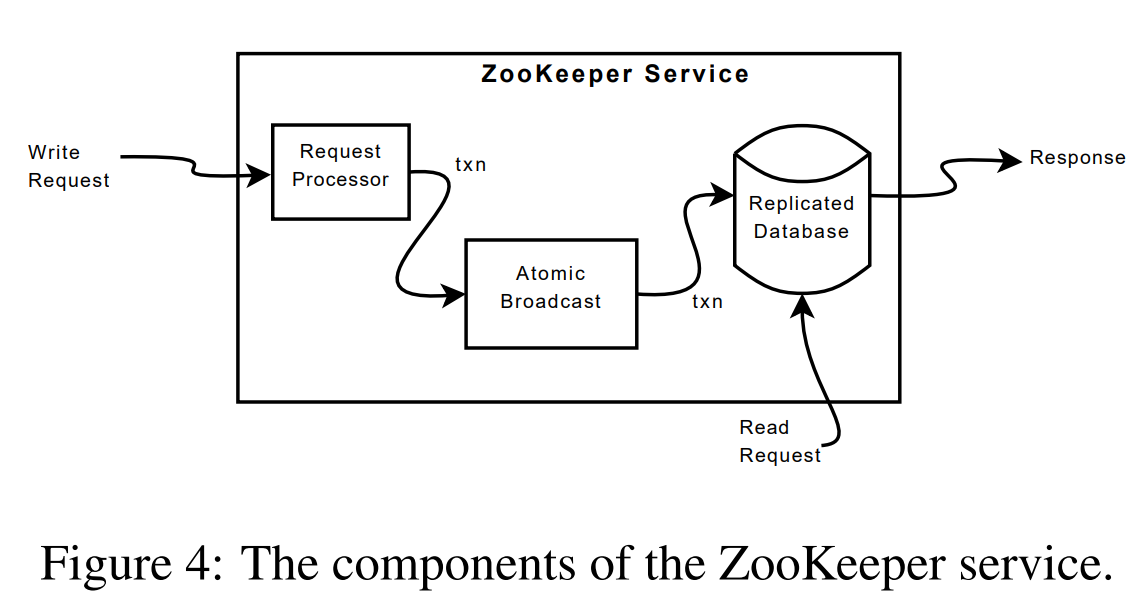
收到请求后,服务器会进行 Prepare (Request Processor) 。若为写请求,则会使用 agreement protocol(原子广播的一种实现)将其提交到 ZooKeeper 数据库中。
领导者收到写请求后,它将计算应用写操作时系统的状态,并将其转换为捕获该新状态的事务。 因为可能存在尚未应用到数据库的未完成事务,所以必须计算未来的状态。
因为有多个client发送请求,所以 Leader 根据接收队列来处理请求。可能会存在多个请求对同一 data 进行 update。
若后面的请求,是根据之前的状态进行更改的,直接应用会错误。所以leader收到请求后,要对请求进行状态计算(备份),判断后面的请求是否是根据前一状态进行更改的。如果是直接错误,否则更新。
其实现就是SETDATA(PATH, DATA, VERSION)
1,请求
Client 发送的每个请求都会返回 zxid。zxid 定义了请求相对于写入请求的 offset(例如 Raft 日志的 Index)。
写请求发送给 Leader 并按顺序执行。收到写请求时,ZooKeeper 会发送通知并输出有关的 watch。
Server 收到 Client 发送的读请求时会检查 Client 的 zxid 和自己的 zxid,若 Client 的 zxid 比较新时,服务器在更新到较新的 zxid 前不会与 Client 建立 session。
默认读操作可能会读取到较久的值,若需要读取最新的数据。则可以发送 sync 请求。
sync 原语是异步执行的,由 Leader 进行排序,保证 sync 之前的 pending writes 全部执行结束。
在实现中,由于使用的是 Leader 的协议,直接放置在 Leader 请求队列末尾即可。
为了使该机制正常工作,follower 必须确保 leader 仍然是 leader。 如果有提交的 pending 事务,则服务器不会怀疑该领导者。 如果待处理队列为空,则领导者需要发出一个空事务来提交并把 sync置于该事务之后。 它具有很好的属性,即当领导者处于负载状态时,不会生成额外的广播流量。 在我们的实现中,设置 timeout 是为了使 leader 在 follower 放弃他们之前意识到他们不再是 leader,因此它们就不会发布空事务。
看不懂….
2,备份
ZooKeeper 的快照称为模糊快照。因为不会Lock ZooKeeper 的状态进行备份,而是采用 DFS 方式的扫描,以原子方式读取每个 Znode 的数据喝元数据生成快照。因此在快照生成过程中其状态可能与 ZooKeeper 任意时间点的状态不一致。
这一点 ZooKeeper 要求 Zab 重新执行快照开始后传递的所有信息解决。因为ZooKeeper 的状态变更是幂等的。
3,Client Failure
为了检测 Client 的 Failure,ZooKeeper 使用了 timeout。在 timeout 时间内没有 Server 收到 Client session 对应的信息,则判定为Failure。
Client 若无法与之前的 Server 建立连接,则会选择其他 Server。
Client 会在活动不足时发送请求,即在会话闲置了 s/3 ms 后发送请求,如果在 2s/3 ms 内未收到 Server 的回复,则替换到新服务器(s为session timeour)。
应用
主要用途:
- TEST-AND-SET:例如在VM FT中作为共享存储使用
- Config info:存储配置信息
- Master:
- 选举出新的Master,并完成状态的替换
- Master发布工作、Worker接收工作
1,Mini-Transactions
下列代码提供了原子性操作,但不是通常所见的事务,称为 Mini-Transactions。
其 TEST-AND-SET 可以根据设置 0/1 一个简单锁实现。
for {x, v := getData("f")if setData("f", x + 1, v) {break}}
2,Non-Scalable Lock(不可扩展锁)
// 1,创建锁,若创建成功则表示拿到锁
if create("f", ephem = T)
return
// 2,否则等待锁释放
if exists("f", watch = T)
wait
// 重试
goto 1
问题:
- 持有锁的Client 刚释放掉,就调用
exists,造成无法收到通知,造成获取锁使其错误(因为 watch时 锁已经不存在了, 除非存在请求去获取锁) - 会造成惊群效应,因为在同一时刻只有一个 Client 能获取锁,且锁的释放会通知所有的等待锁的 Client 发送请求,其复杂度是
#card=math&code=%5Csum_%7Bi%3D1%7D%5En%3Dn%2An%2F2%3DO%28n%5E2%29&id=EcKDS)
- 仅实现互斥锁(没有实现读写锁等模式)
3,Scalable Lock
步骤:
create seq “f”:创建一个临时有序文件List f*:获取目录下的文件IF no lower #file, return:若不存在更小的数字,表示获取了锁并返回IF exists(next lower #, WATCH = T) WAIT:等待前一个文件的创建 Client 锁,并等待它释放GOTO 2:可能 watch 文件的 Client 挂掉了,但是锁被更前面的 Client 获取,因此需要重新执行
优点:
- 删除一个 Znode 只会唤醒一个 Client,没有惊群效应
- 没有轮询或超时
- 可以通过浏览 ZooKeeper 数据可以看到锁争用的数量,中断锁定以及调试锁相关的问题。
锁并不确保原子性,若 Client 在执行过程中崩溃了,下一个 Client 获取锁拿到的是被修改一半的数据。
应用:
- Soft Lock 可以用于保护一些不重要的数据。例如 MapReduce 中,每个任务只有一个 Worker 执行。
- 使用锁来选举出一个 Master

若有收获,就点个赞吧
0 人点赞
