1. 命名
网络爬虫也可称作网络蜘蛛、蚂蚁、自动索引程序( automatic indexer ) ,或(在 FOAF 软件中)称为网络疾走( web scutter )。
—维基百科
2. 概述
网络爬虫始于一张被称作种子的统一资源地址(URL)列表。当网络爬虫访问这些统一资源定位器时,它们会甄别出页面上所有的超链接,并将它们写入一张“待访列表”,即所谓爬行疆域。此疆域上的URL将會被按照一套策略循环來访问。如果爬虫在执行的过程中复制归档和保存网站上的信息,这些档案通常储存,使他们可以較容易的被查看。阅读和浏览他们儲存的网站上並即时更新的信息,這些被儲存的網頁又被稱為“快照”。越大容量的網頁意味着网络爬虫只能在给予的时间内下载越少部分的网页,所以要优先考虑其下载。高变化率意味着网页可能已经被更新或者被取代。一些服务器端软件生成的 URL(统一资源定位符)也使得网络爬虫很难避免检索到重复内容。
但是互联网的资源卷帙浩繁,这也意味着网络爬虫只能在一定时间内下载有限数量的网页,因此它需要衡量優先順序的下载方式。有時候網頁出現、更新和消失的速度很快,也就是說网络爬虫下载的网页在幾秒後就已经被修改或甚至删除了。这些都是网络爬虫设计師们所面临的两个问题。
再者,服务器端软件所生成的统一资源地址数量庞大,以致网络爬虫难免也會采集到重复的内容。根据超文本傳輸協定,无尽组合的参数所返回的页面中,只有很少一部分确实传回正確的内容。例如:數張快照陈列室的网站,可能通过几个参数,让用户选择相关快照:其一是通过四种方法对快照排序,其二是关于快照分辨率的的三种选择,其三是两种文件格式,另加一个用户可否提供内容的选择,这样对于同样的结果会有 48 种(432)不同的统一资源地址与其关联。这种数学组合替网络爬虫造成了麻烦,因为它们必须越过这些无关脚本变化的组合,寻找不重复的内容。
—维基百科
3. 流层
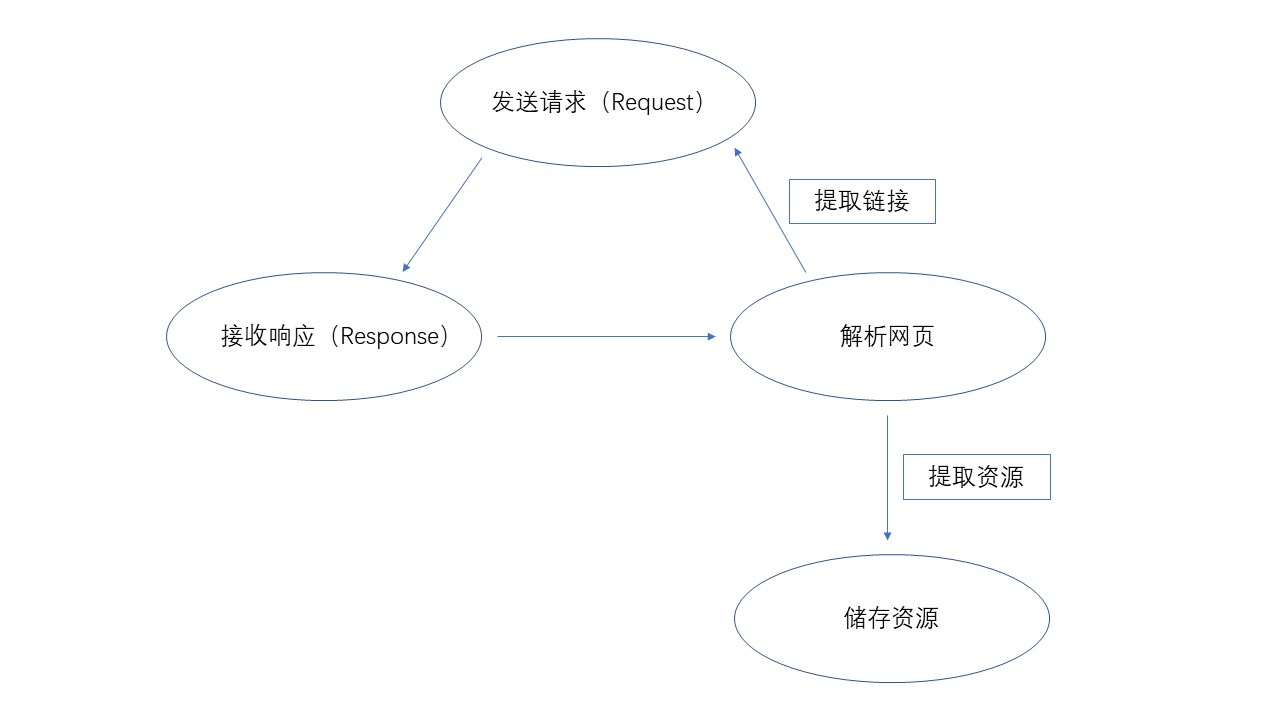
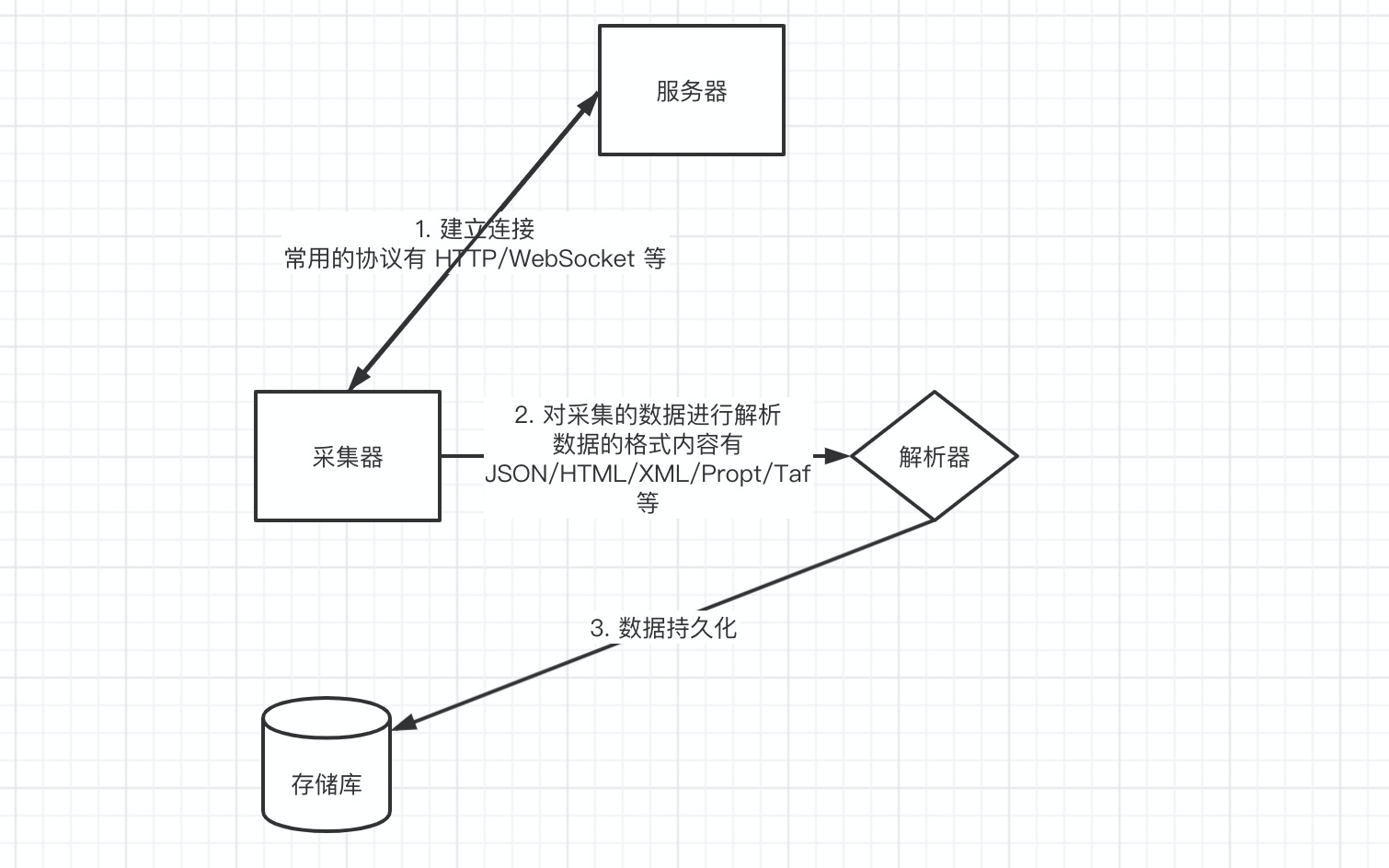
上面图展现的为处理爬虫的基本流层,但是其本质就是数据采集种的一种。我觉得的数据采集图,如下图示:
4. 注意
1. 性能骚扰
Web 服务器默认接受人类访问,受限于编写水平和目的,网络爬虫将会为 Web 服务器带来巨大的资源的开销。
2. 法律风险
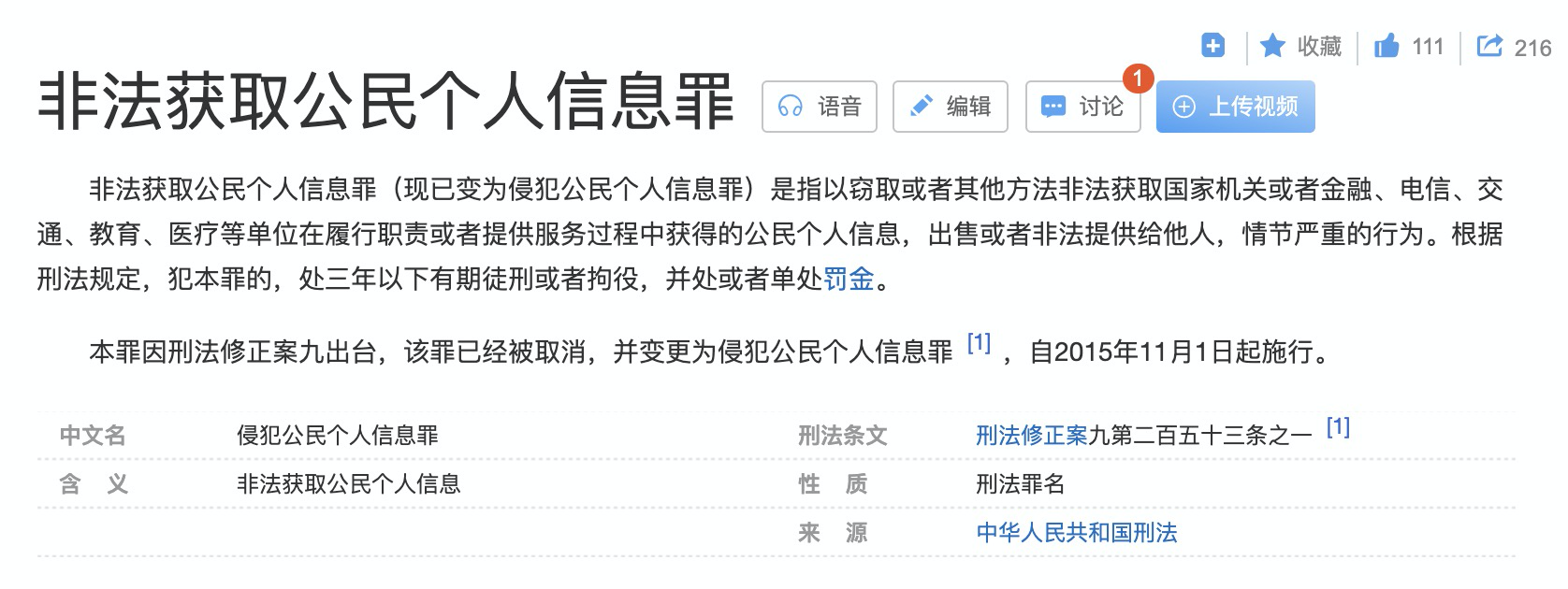
服务器上的数据有产权归属,网络爬虫获取数据后牟利将会带来法律的风险。
3. 隐私泄露
网络爬虫可能具备突破简单访问的控制能力,获取被保护的数据,从而泄露个人隐私。
4. Robots 协议
Robots 是网站跟爬虫间的协议,用简单直接的 txt 格式文本方式告诉对应的爬虫被允许的权限,也就是说 robots.txt 是搜索引擎中访问网站的时候要查看的第一个文件。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在 robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
— 百度百科
为什么需要 Robots 协议?
网站内容的所有者是网站管理员,搜索引擎应该尊重所有者的意愿,为了满足以上等等,就需要提供一种网站和爬虫进行沟通的途径,给网站管理员表达自己意愿的机会。有需求就有供应,robots 协议就此诞生。
举个存在 robots.txt 文件网站的例子
User-agent: BaiduspiderDisallow: /baiduDisallow: /s?Disallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: GooglebotDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: MSNBotDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: Baiduspider-imageDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: YoudaoBotDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: Sogou web spiderDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: Sogou inst spiderDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: Sogou spider2Disallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: Sogou blogDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: Sogou News SpiderDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: Sogou Orion spiderDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: ChinasoSpiderDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: SosospiderDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: yisouspiderDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: EasouSpiderDisallow: /baiduDisallow: /s?Disallow: /shifen/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: *Disallow: /
| User-agent | 指定对哪些爬虫生效 |
|---|---|
| Disallow | 指定要屏蔽的网址 |
| 产品名称 | User-Agent |
|---|---|
| 网页搜索 | Baiduspider |
| 移动搜索 | Baiduspider |
| 图片搜索 | Baiduspider-image |
| 视频搜索 | Baiduspider-video |
| 新闻搜索 | Baiduspider-news |
| 百度搜索 | Baiduspider-favo |
| 百度联盟 | Baiduspider-cpro |
| 商务搜索 | Baiduspider-ads |
5. 总结
学习爬虫一定要按照现在的定义的规则下进行爬虫,不然就很容易触犯法律。俗话说的好,爬虫写的好,牢饭少不了😐😐。其实这片文章就是跟小白普及一下,爬虫需要注意的地方,不要触犯法律,毕竟技术无罪😌。
后面的文章主要是告诉用户如何去采集网站的数据,举例采用的代码语言为 Java,不要再说爬虫用 Python 了,但凡支持 Socket 连接的语言都可以爬虫,只是库多少,使用方不方便的问题了。
6. 参考文献

若有收获,就点个赞吧
0 人点赞
