Set 集合
1. set集合概述和特点
set集合概述:
set集合是一个接口 Interface Set
set集合继承Collection
泛型
set集合特点:
不包含重复元素的集合
没有带索引的方法, 所以不能使用普通for循环获取索引遍历
代码实现:
public static void main(_String[] args) {
// 创建Set集合对象
// Set是一个接口不能直接实例化,需要找到对应的实现类HashSet
// HashSet: 该实现类对集合的迭代顺序不作任何保证
Set<_String_> set = new HashSet<>()_;
// set 集合添加元素<br /> set.add_(_"hello"_)_;<br /> set.add_(_"world"_)_;<br /> set.add_(_"java"_)_;<br /> set.add_(_"java"_)_;<br /> System._out_.println_(_set_)_;<br /> // [world, java, hello] 因为HashSet迭代顺序不作任何保证,并且添加重复元素不输出<br /> <br /> // 遍历set集合<br /> Iterator_<_String_> _it = set.iterator_()_;<br /> while _(_it.hasNext_()){<br /> _String s = it.next_()_;<br /> System._out_.println_(_s_)_; _}<br /> _System._out_.println_(_"---------------"_)_;<br /> for _(_String s : set_){<br /> _System._out_.println_(_s_)_;<br /> // world java hello<br /> // 和添加的顺序不一致 ,是因为HashSet迭代顺序不作任何保证 _} }_
2.哈希值
哈希值:是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
Object类中有一个方法可以直接获取对象的哈希值 —> hashCode() 返回int值
public int hashCode() : 返回对象的哈希码值
对象(Object)的哈希值特点:
同一对象多次调用hashCode() 方法返回的哈希值是相同的
默认情况下, 不同对象的哈希值是不同的
重写hashCode()方法, 可以实现让不同对象的哈希值相同
代码实现:
// 创建一个教师类
public class Teacher {
_private int age;
private String name;
public Teacher() { }
public Teacher(int age, String name) { this.age = age; this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
// 重写hashCode()方法 返回值为0
@Override
public int hashCode() { return 0; } }
—————————————————————————-
// Object类中有一个方法可以直接获取对象的哈希值 —> hashCoed() 返回int值
public class HashDemo {
public static void main(String[] args) {
Teacher t = new Teacher(21,”李畅”);
// 使用hashCode()获取哈希码值,同一个对象多次调用该方法,哈希值也相同
System._out.println(_t.hashCode()); // 460141958
System._out.println(_t.hashCode()); // 460141958
System._out.println(“——————————“);
// 默认情况下,不同对象调用hashCode()方法返回的哈希值是不同的,哪怕参数一致
// 通过方法重写, 可以实现不同对象的哈希值相同的
Teacher t1 = new Teacher(_21,”李畅”);
System._out.println(_t1.hashCode()); // 1163157884
System._out.println(“——————————“);
// 字符串和int都可以直接使用Object 的hashCode()获取哈希值
System.out.println(“hello”.hashCode()); // 99162322
System.out.println(“world”.hashCode()); // 113318802
System.out.println(“java”.hashCode()); // 3254818
System.out.println(“—————————-“);
// 字符串重写了hashCode()方法
System.out.println(“重地”.hashCode()); // 1179395
System.out.println(“通话”.hashCode()); // 1179395 } }
3.HashSet 集合的概述和特点
HashSet 集合特点
1. 底层数据结构是哈希表1. 对集合的第二代顺序不做任何保证 , 不保证存储和取出的元素顺序一致1. 没有带索引的方法, 所以不能使用普通for循环获取索引遍历1. 由于是Set集合 , 所以是不包含重复元素的集合
代码实现:
public class HashCodeDemo {
_public static void main(String[] args) {
// 创建HashSet集合对象
HashSet<_String_> hs = new HashSet<>();
// 调用add()方法 直接添加元素无索引, 和ArrayList.add()有索引
hs.add(“hello”);
hs.add(“world”);
hs.add(“java”);
hs.add(“java”);
System._out.println(_hs);
// [world, java, hello], hashSet不保证顺序性,但是保证元素不重复输出
// 因为没有索引,使用增强for循环
for (String s: hs){
System._out.println(_s); } } }_
4.HashSet 集合保证元素唯一性源码分析
HashSet集合添加一个元素的过程
1. **先通过hashCode()计算元素哈希值**1. **在通过十六进制计算哈希值得出地址**1. **先判断计算出的地址是否有元素,没有则存储**1. **地址如果有元素在通过equals()方法判断元素内容是否**1. **如果和原存在地址元素内容相同不存储,不同则存储**
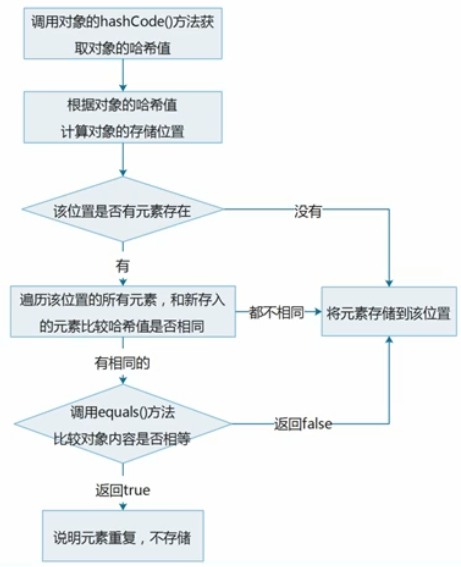
HashSet集合存储元素:
保证元素唯一性, 需要重写hashCode()和equals()方法
HashSet通过哈希值/16 得到元素地址,在根据哈希值和字符串内容是否相等
逻辑运行符:
a && b 如果 a 为true 则 b不执行
a || b 如果 a或者b有一个为true 则为true
5.HashSet 集合存储学生对象并遍历
需求: 创建一个存储学生对象的集合, 存储多个学生对象 , 使用程序实现在控制台遍历该集合
要求:学生对象的成员变量值相同, 我们就认为是同一个对象
思路:
1. 定义学生类1. 创建HashSet集合对象1. 创建学生对象1. 把学生添加到集合1. 遍历集合(增强for)
6. 保证元素唯一性, 需要重写hashCode()和equals()方法
// 定义学生类
public class Student {
_private String name;
private int age;
public Student() { }
public Student(String name, int age) {
this.name = name;
this.age = age; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
// 保证元素唯一性,一键生成alt+ insert需要重写的hashCode()和equals()方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null; }
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result; } }
—————————————————————————————-_
public class HashSetDemo {
_public static void main(String[] args) {
//创建HashSet集合对象
HashSet<_Student_> hs = new HashSet<>();
//创建学生对象
Student s1 = new Student(“Tom”, 23);
Student s2 = new Student(“Jack”, 21);
Student s3 = new Student(“Colin”, 25);
Student s4 = new Student(“Tom”, 23);
//把学生添加到集合
hs.add(s1);
hs.add(s2);
hs.add(s3);
hs.add(s4);
//遍历集合(增强for)
for (Student student : hs) {
System._out.println(_student.getName() + “,” + student.getAge()); } } }_
6. LinkedHashSet 集合概述和特点
LinkedHashSet
LinkedHashSet
所以LinkedHashSet
总结:
1. 哈希表和链表实现的Set接口,具有可预测的迭代顺序1. 由链表保证元素有序性 , 也就是说元素的存储和取出顺序是一致的1. 由哈希表保证元素唯一性,也就是没有重复的元素
LinkedHashSet集合练习:
存储字符串并遍历:
// 创建LinkedHashSet对象
LinkedHashSet<_String> lhs = new LinkedHashSet<>();
// 添加元素
lhs.add(“hello”);
lhs.add(“world”);
lhs.add(“java”);
lhs.add(“java”);
System._out.println(_lhs); // [hello, world, java]
// 遍历该循环
for (String s : lhs){ System._out.println(_s); // hello world java }_
7. TreeSet 集合概述和特点
TreeSet
TreeSet
TreeSet
1. natural ordering 的 **Comparable**<T>自然排序接口
—> 针对TreeSet() 空树组无参构造
2. 使用**Comparator**<T> 比较器接口,进行比较功能 --> 针对TreeSet<E> 含有树组无参构造
—> 针对TreeSet(Compatator<? super E> comparator) 空树组含有比较器的接口
总结:
1. 元素有序,但是这里的顺序不是存储和取出的顺序, 而是按照一定的自然规则排序(例如:a-z),**具体排序方式取决于构造方法**1. **TreeSet() ** 空树组无参构造,自然排序1. **TreeSet(Compatator comparator)** 空树组带参构造,含有比较器1. 没有带索引的方式, 所以不能使用普通for循环遍历1. 由Set集合底层是哈希表保证元素唯一性,也就是没有重复的元素
TreeSet 集合练习:
存储整数并遍历:
// 因为是整数类型,创建对象应该使用对应的整数包装类类型Integer
TreeSet<_Integer> treeSet = new TreeSet<_Integer_>();
// 添加元素
treeSet.add(1);
treeSet.add(3);
treeSet.add(2);
treeSet.add(3);
// 打印该集合,发现顺序按照自然逻辑比较,并且不包含重复元素
System._out.println(_treeSet); // [1, 2, 3]
// 增强for遍历该集合
for (int i : treeSet){ System._out.println(_i); // 1 2 3}_
总结: HashSet集合以及TreeSet集合的区别
1. HashSet<>不保证集合中元素的顺序,但是HashSet<>的子类LinkedHashSet对顺序有排序,因为底层除了哈希表还有链表1. TreeSet<>集合可以使用自然排序或者排序器对元素排序
8. 自然排序Comparable的使用
使用Comparable自然排序
1. 存储学生对象并遍历, 创建TreeSet集合使用无参构造方法1. 要求 : 按照年龄从小到大排序 , 年龄相同时,按照姓名的字母顺序排序
总结:
1. **用TreeSet集合存储自定义对象,无参构造方法使用的时自然排序对元素进行排序的**1. **带参构造方法使用自然排序,是让元素所属的类(Student)必须实现Comparable接口,并且重写compareTo(Student s),参数是定义类和对象**1. **重写方法时,必须按照排序规则的需求使用排序方法分为主要条件和次要条件**
// 创建一个学生类
// 没有实现Comparable接口所以抛出异常,该泛型类接口只针对需要实现的类提供自然排序
// 所以该类如果想使用自然排序,必须实现该泛型类接口, 泛型是该类
public class Student implements Comparable<_Student> {
private String name;
private int age;
public Student() { }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
public Student(String name, int age) {
this.name = name;
this.age = age; }
// 实现了Comparable
@Override
public int compareTo
// 该方法如果return的值是0 默认所有元素是一致的 — return 0;
// 该方法如果return的值是1 将所有元素是按照升序输出的 — return 1;
// 该方法如果return的值是-1 将所有元素是按照降序输出的 — return -1;
// 按照年龄从小到大排序,this.age表示前一个元素减去后一个元素排序比较
int num = this.age - s.age;
// 按照年龄从大到小排序
// int num1 = s.age - this.age;
// 年龄相同时,按照姓名的字母顺序排序
// 该代码逻辑当前一个元素的年龄减去后一个元素的年里为0时,表示年龄相等,所以比较姓名
return num == 0? this.name.compareTo(s.name) : num; } }
——————————————————————————————————————————————-_
public class TreeSetDemo01 {
_public static void main(String[] args) {
// 创建TreeSet集合,泛型为学生
TreeSet<_Student_> treeSet = new TreeSet<_Student_>();
// 创建Student对象
Student s1 = new Student(“Tom”, 21);
Student s2 = new Student(“Mark”, 22);
Student s3 = new Student(“Jack”, 20);
Student s4 = new Student(“Colin”, 20);
Student s5 = new Student(“Colin”, 20);
// 添加元素
treeSet.add(s1);
treeSet.add(s2);
treeSet.add(s3);
treeSet.add(s4);
treeSet.add(s5);
// ClassCastException抛出异常,该类需要继承Comparale接口以及重写compareTo()方法
for (Student s : treeSet) { System._out.println(_s.getName() + “,” + s.getAge()); } } }
// 输出结果为:_Colin,20 Jack,20 Tom,21 Mark,22
9. 比较器排序Comparator的使用
1. 存储学习对象并遍历,创建TreeSet集合使用带参构造方法1. 要求 : 按照年龄从小到大排序 , 年龄相同时,按照姓名的字母顺序排序
总结:
1. **用TreeSet集合存储自定义对象,带参构造方法使用的比较器对元素进行排序的**1. **1. **重写方法时,必须按照排序规则的需求使用排序方法分为主要条件和次要条件**
// 创建一个学生类
public class Student{
_private String name;
private int age;
public Student() { }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
public Student(String name, int age) {
this.name = name;
this.age = age; }
—————————————————————————————————
/ 存储学习对象并遍历,创建TreeSet集合使用带参构造方法
要求 : 按照年龄从小到大排序 , 年龄相同时,按照姓名的字母顺序排序/
public class ComparatorDemo {
public static void main(String[] args) {
// 创建排序器TreeSet对象,带参构造方法
// 使用指定比较器TreeSet<>(Comparator<? super E> comparator)
TreeSet<_Student_> treeSet = new TreeSet<>(new Comparator<_Student_>() {
// 通过匿名内部类创建Comparator对象,重写compare()方法
// 因为compare()该方法在ComparatorDemo测试类中,this关键字的指向是ComparatorDemo这个测试类,不是treeSet集合
// 同理应该向compare()这个方法中传递两个参数,进行比较,不能调用this
@Override
public int compare(Student s1, Student s2) {
// 按照年龄从小到大排序,s1这个实例对象
int num = s1.getAge() - s2.getAge();
// 年龄相同时,按照姓名的字母顺序排序
return num == 0 ? s1.getName().compareTo(s2.getName()) : num; } });
// 创建Student对象
Student s1 = new Student(“Tom”, 21);
Student s2 = new Student(“Mark”, 22);
Student s3 = new Student(“Jack”, 20);
Student s4 = new Student(“Colin”, 20);
Student s5 = new Student(“Colin”, 20);
// 添加元素
treeSet.add(s1);
treeSet.add(s2);
treeSet.add(s3);
treeSet.add(s4);
treeSet.add(s5);
for (Student s : treeSet) {
System._out.println(_s.getName() + “,” + s.getAge()); } } }_
总结:自然比较器和比较器的区别
使用自然排序Comparable,需要该类继承 自然排序Comparable的接口,并且在该类中重写Comparable中的compareTo方法
2.使用比较器排序Comparator需要在main方法中的实例对象中new 一个匿名内部类 Comparator<..>{ 重写其中compare()方法 }案例: 成绩排序
需求: 用TreeSet集合存储多个学生信息(姓名, 语文成绩 , 数学成绩) , 并遍历该集合
Tips: 使用TreeSet有两种排序方式1. 自然排序Comparable, 无参排序, 需要类实现该排序Comparable接口, 并重写CompareTo方法1. 使用Comparator比较器, 带参排序.参数(传入比较的类 类的实例对象), 该类无需继承借口,但是需要对该类的实例对象, 创建新的匿名内部类Compatator对象, 并重写该匿名内部类的方法
要求: 按照总分从高到低出现
思路:
1. 定义学生类1. 创建TreeSet集合对象,通过比较器进行排序1. 创建学生对象1. 把学生对象添加到集合1. 遍历集合
public class Student {
_private String name;
private int mathScore;
private int chinaScore;
public Student() { }
public Student(String name, int mathScore, int chinaScore) {
this.name = name;
this.mathScore = mathScore;
this.chinaScore = chinaScore; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getMathScore() { return mathScore; }
public void setMathScore(int mathScore) { this.mathScore = mathScore; }
public int getChinaScore() { return chinaScore; }
public void setChinaScore(int chinaScore) { this.chinaScore = chinaScore; }
// 提供学生总成绩的方法
public int getSum(){ return this.chinaScore + this.getMathScore(); } }
—————————————————————————————————————————-
public class TreeSetDemo {
public static void main(String[] args) {
// 创建TreeSet集合对象, 通过比较器进行排序
// 创建匿名内部类Comparator比较器,重写compare()方法
TreeSet<_Student_> treeSet = new TreeSet<>(new Comparator<_Student_>() {
@Override
// s1是前一个对象, s2是后一个对象,对这两个对象进行比较
public int compare(Student s1, Student s2) {
// 对总成绩进行比较,总分从高到底
// int sum = (s2.getChinaScore()+s2.getMathScore())-(s1.getChinaScore()+s1.getMathScore());
int i = s2.getSum() - s1.getSum();
// 如果成绩相同,使用compareTo()方法按照名字排名
int num = i == 0? (s2.getName().compareTo(s1.getName())) : i;
return num; } });
Student s1 = new Student(“李畅”, 100, 100);
Student s2 = new Student(“赵明”, 80, 90);
Student s3 = new Student(“唐明”, 70, 50);
Student s4 = new Student(“福哥”, 40, 64);
Student s5 = new Student(“谭某”, 52, 30);
Student s6 = new Student(“徐某”, 90, 80);
treeSet.add(s1);
treeSet.add(s2);
treeSet.add(s3);
treeSet.add(s4);
treeSet.add(s5);
treeSet.add(s6);
/ Iterator
while (it.hasNext()) {
Student s = it.next();
System.out.println(s.getName() + “,” + s.getSum()) }
for (Student s : treeSet) {
System._out.println(_s.getName() + “,” + s.getSum()); } } }_
案例: 不重复的随机数
需求: 编写一个程序,获取10个 1-20之间的随机数 ,要求随机数不能重复,并在控制台输出
思路:
1. 创建Set集合对象1. 创建随机数对象1. 判断集合的长度是不是小于10如果小于: 产生一个随机数,添加到集合<br /> 回到3继续4. 遍历集合
public class SetDemo {
_public static void main(String[] args) {
// 创建Set集合对象
// Set
// 使用TreeSet集合 排序该集合
Set
// 创建随机数对象
Random random = new Random();
// 判断集合的长度是不是小于10,重复判断该集合
while (set.size() < 10) {
// 产生一个随机数, 添加到集合
/ random.nextInt()的用法
1、不带参数的nextInt()会生成所有有效的整数(包含正数,负数,0)
2、带参的nextInt(int x)则会生成一个范围在0~x(不包含X)内的任意正整数
例如:int x=new Random.nextInt(100); 则x为一个0~99的任意整数 /
// 使用random.nextInt(int bound)该方法可以控制随机数的数量
int i = random.nextInt(20) + 1;
set.add(i); }
// 遍历集合
for (Integer i : set){ System._out.println(_i); } } }_

若有收获,就点个赞吧
0 人点赞
