
Adblocker

数据结构-核心篇之树
一 树
树是由n(n>=1)个有限结点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
树具有以下特点:
1.每个结点有零个或多个子结点;
2.没有父结点的结点为根结点;
3.每一个非根结点只有一个父结点;
4.每个结点及其后代结点整体上可以看做是一棵树,称为当前结点的父结点的一个子树;
1.1 树的相关概念
结点的度:
一个结点含有的子树的个数称为该结点的度;
叶结点:
度为0的结点称为叶结点,也可以叫做终端结点
分支结点:
度不为0的结点称为分支结点,也可以叫做非终端结点
结点的层次:
从根结点开始,根结点的层次为1,根的直接后继层次为2,以此类推
结点的层序编号:
将树中的结点,按照从上层到下层,同层从左到右的次序排成一个线性序列,把他们编成连续的自然数。
树的度:
树中所有结点的度的最大值
树的高度(深度):
树中结点的最大层次
森林:
m(m>=0)个互不相交的树的集合,将一颗非空树的根结点删去,树就变成一个森林;给森林增加一个统一的根
结点,森林就变成一棵树
孩子结点:
一个结点的直接后继结点称为该结点的孩子结点
双亲结点(父结点):
一个结点的直接前驱称为该结点的双亲结点
兄弟结点:
同一双亲结点的孩子结点间互称兄弟结点
1.2 二叉树的种类
二叉树
就是度不超过2的树(每个结点最多有两个子结点)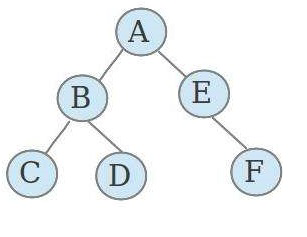
满二叉树
如果每一个层的结点树都达到最大值,则这个二叉树就是满二叉树
完全二叉树
叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树
二 二叉搜索树
2.1 代码实现
package com.ycc.data.structure.tree;import cn.itcast.algorithm.linear.Queue;/*** 二叉搜索树* 二叉树 拥有两个孩子 ,二叉搜索树 左孩子小于根节点,右孩子大于根节点** @author liaozx* @description* @create 2020-11-27 10:29*/public class BinarySearchTree<Key extends Comparable<Key>, Value> {private Node root;private int current;public class Node {//存储键public Key key;//存储值private Value value;Node left;//左孩子Node right;//右孩子public Node(Key key, Value value, Node left, Node right) {this.key = key;this.value = value;this.left = left;this.right = right;}}/*** 向树中添加元素key-value** @param key* @param value*/public void put(Key key, Value value) {root = put(root, key, value);}/*** 向指定的树node中添加key-value,并返回添加元素后新的树* 其逻辑是,新节点的key比较root的key,大于在右边,小于在左边,等于则替换** @param node* @param key* @param value* @return*/private Node put(Node node, Key key, Value value) {//如果node子树为空if (null == node) {current++;return new Node(key, value, null, null);}//如果node子树不为空,比较node结点的键和key的大小int cmp = key.compareTo(node.key);if (cmp > 0) {//如果key大于node结点的键,则继续找node结点的右子树node.right = put(node.right, key, value);} else if (cmp < 0) {//如果key小于node结点的键,则继续找node结点的左子树node.left = put(node.left, key, value);} else {//如果key等于node结点的键,则替换node结点的值为value即可node.value = value;}return node;}/*** 查询树中指定key对应的value** @param key* @return*/public Value get(Key key) {return get(root, key);}/*** 从指定的树node中,查找key对应的值** @param node* @param key* @return*/public Value get(Node node, Key key) {//node树为nullif (node == null) {return null;}//node树不为null,比较key和node结点的键的大小int cmp = key.compareTo(node.key);if (cmp > 0) {//如果key大于node结点的键,则继续找node结点的右子树return get(node.right, key);} else if (cmp < 0) {//如果key小于node结点的键,则继续找node结点的左子树return get(node.left, key);} else {//如果key等于node结点的键,就找到了键为key的结点,只需要返回node结点的值即可return node.value;}}/*** 删除树中key对应的value** @param key*/public void delete(Key key) {delete(root, key);}//删除指定树node中的key对应的value,并返回删除后的新树public Node delete(Node node, Key key) {//node树为nullif (node == null) {return null;}//node树不为nullint cmp = key.compareTo(node.key);if (cmp > 0) {//如果key大于node结点的键,则继续找node结点的右子树node.right = delete(node.right, key);} else if (cmp < 0) {//如果key小于node结点的键,则继续找node结点的左子树node.left = delete(node.left, key);} else {//如果key等于node结点的键,完成真正的删除结点动作,要删除的结点就是node,让元素个数-1current--;//得找到右子树中最小的结点if (node.right == null) {return node.left;}if (node.left == null) {return node.right;}Node minNode = node.right;while (minNode.left != null) {minNode = minNode.left;}//删除右子树中最小的结点Node n = node.right;while (n.left != null) {if (n.left.left == null) {n.left = null;} else {//变换n结点即可n = n.left;}}//让node结点的左子树成为minNode的左子树minNode.left = node.left;//让node结点的右子树成为minNode的右子树minNode.right = node.right;//让node结点的父结点指向minNodenode = minNode;}return node;}/*** 查找整个树中最小的键** @return*/public Key min() {return min(root).key;}/*** 在指定树node中找出最小键所在的结点** @param node* @return*/private Node min(Node node) {//需要判断node还有没有左子结点,如果有,则继续向左找,如果没有,则node就是最小键所在的结点if (node.left != null) {return min(node.left);} else {return node;}}/*** 在整个树中找到最大的键** @return*/public Key max() {return max(root).key;}/*** 在指定的树node中,找到最大的键所在的结点** @param node* @return*/public Node max(Node node) {//判断node还有没有右子结点,如果有,则继续向右查找,如果没有,则node就是最大键所在的结点if (node.right != null) {return max(node.right);} else {return node;}}/*** 前序遍历 根左右* 获取整个树中所有的键** @return*/public Queue<Key> preErgodic() {Queue<Key> keys = new Queue<>();preErgodic(root, keys);return keys;}/*** 前序遍历 根左右* 获取指定树node的所有键,并放到keys队列中** @param node* @param keys*/private void preErgodic(Node node, Queue<Key> keys) {if (node == null) {return;}//把node结点的key放入到keys中keys.enqueue(node.key);//递归遍历node结点的左子树if (node.left != null) {preErgodic(node.left, keys);}//递归遍历node结点的右子树if (node.right != null) {preErgodic(node.right, keys);}}/*** 中序遍历 左根右* 使用中序遍历获取树中所有的键** @return*/public Queue<Key> midErgodic() {Queue<Key> keys = new Queue<>();midErgodic(root, keys);return keys;}/*** 中序遍历 左根右* 使用中序遍历,获取指定树node中所有的键,并存放到key中** @param node* @param keys*/private void midErgodic(Node node, Queue<Key> keys) {if (node == null) {return;}//先递归,把左子树中的键放到keys中if (node.left != null) {midErgodic(node.left, keys);}//把当前结点node的键放到keys中keys.enqueue(node.key);//在递归,把右子树中的键放到keys中if (node.right != null) {midErgodic(node.right, keys);}}/*** 后序遍历 左右根* 使用后序遍历,把整个树中所有的键返回** @return*/public Queue<Key> afterErgodic() {Queue<Key> keys = new Queue<>();afterErgodic(root, keys);return keys;}/*** 后序遍历 左右根* 使用后序遍历,把指定树node中所有的键放入到keys中** @param node* @param keys*/private void afterErgodic(Node node, Queue<Key> keys) {if (node == null) {return;}//通过递归把左子树中所有的键放入到keys中if (node.left != null) {afterErgodic(node.left, keys);}//通过递归把右子树中所有的键放入到keys中if (node.right != null) {afterErgodic(node.right, keys);}//把node结点的键放入到keys中keys.enqueue(node.key);}/*** 使用层序遍历,获取整个树中所有的键** @return*/public Queue<Key> layerErgodic() {//定义两个队列,分别存储树中的键和树中的结点Queue<Key> keys = new Queue<>();Queue<Node> nodes = new Queue<>();//默认,往队列中放入根结点nodes.enqueue(root);while (!nodes.isEmpty()) {//从队列中弹出一个结点,把key放入到keys中Node n = nodes.dequeue();keys.enqueue(n.key);//判断当前结点还有没有左子结点,如果有,则放入到nodes中if (n.left != null) {nodes.enqueue(n.left);}//判断当前结点还有没有右子结点,如果有,则放入到nodes中if (n.right != null) {nodes.enqueue(n.right);}}return keys;}//获取整个树的最大深度public int maxDepth() {return maxDepth(root);}//获取指定树node的最大深度private int maxDepth(Node node) {if (node == null) {return 0;}//node的最大深度int max = 0;//左子树的最大深度int maxL = 0;//右子树的最大深度int maxR = 0;//计算node结点左子树的最大深度if (node.left != null) {maxL = maxDepth(node.left);}//计算node结点右子树的最大深度if (node.right != null) {maxR = maxDepth(node.right);}//比较左子树最大深度和右子树最大深度,取较大值+1即可max = maxL > maxR ? maxL + 1 : maxR + 1;return max;}//获取树中元素的个数public int size() {return current;}}
2.2 折纸代码实现
package com.ycc.data.structure.tree.test;import com.ycc.data.structure.line.MyLinedQueue;/*** @author liaozx* @date 2020-11-27*/public class PaperFolding {public static void main(String[] args) {//构建折痕树Node tree = createTree(3);//遍历折痕树,并打印printTree(tree);}//3.使用中序遍历,打印出树中所有结点的内容;private static void printTree(Node tree) {if (tree == null) {return;}printTree(tree.left);System.out.print(tree.item + ",");printTree(tree.right);}//2.构建深度为N的折痕树;private static Node createTree(int N) {Node root = null;for (int i = 0; i < N; i++) {if (i == 0) {//1.第一次对折,只有一条折痕,创建根结点;root = new Node("down", null, null);} else {//2.如果不是第一次对折,则使用队列保存根结点;MyLinedQueue<Node> queue = new MyLinedQueue<>();queue.enQueue(root);//3.循环遍历队列:while (!queue.isEmpty()) {//3.1从队列中拿出一个结点;Node tmp = queue.deQueue();//3.2如果这个结点的左子结点不为空,则把这个左子结点添加到队列中;if (tmp.left != null) {queue.enQueue(tmp.left);}//3.3如果这个结点的右子结点不为空,则把这个右子结点添加到队列中;if (tmp.right != null) {queue.enQueue(tmp.right);}//3.4判断当前结点的左子结点和右子结点都不为空,如果是,则需要为当前结点创建一个 值为down的左子结点,一个值为up的右子结点。if (tmp.left == null && tmp.right == null) {tmp.left = new Node("down", null, null);tmp.right = new Node("up", null, null);}}}}return root;}//1.定义结点类private static class Node {//存储结点元素String item;//左子结点Node left;//右子结点Node right;public Node(String item, Node left, Node right) {this.item = item;this.left = left;this.right = right;}}}
三 堆
堆是计算机科学中一类特殊的数据结构的统称,堆通常可以被看做是一棵完全二叉树的数组对象。它对应的数组是按层存储,如图
特点:
父节点索引:i,左孩子索引:2i ,右孩子索引:2i+1,即8号球(索引:4)、7号球(索引:5)、14号球(索引:2)。
原理是他是完全二叉树。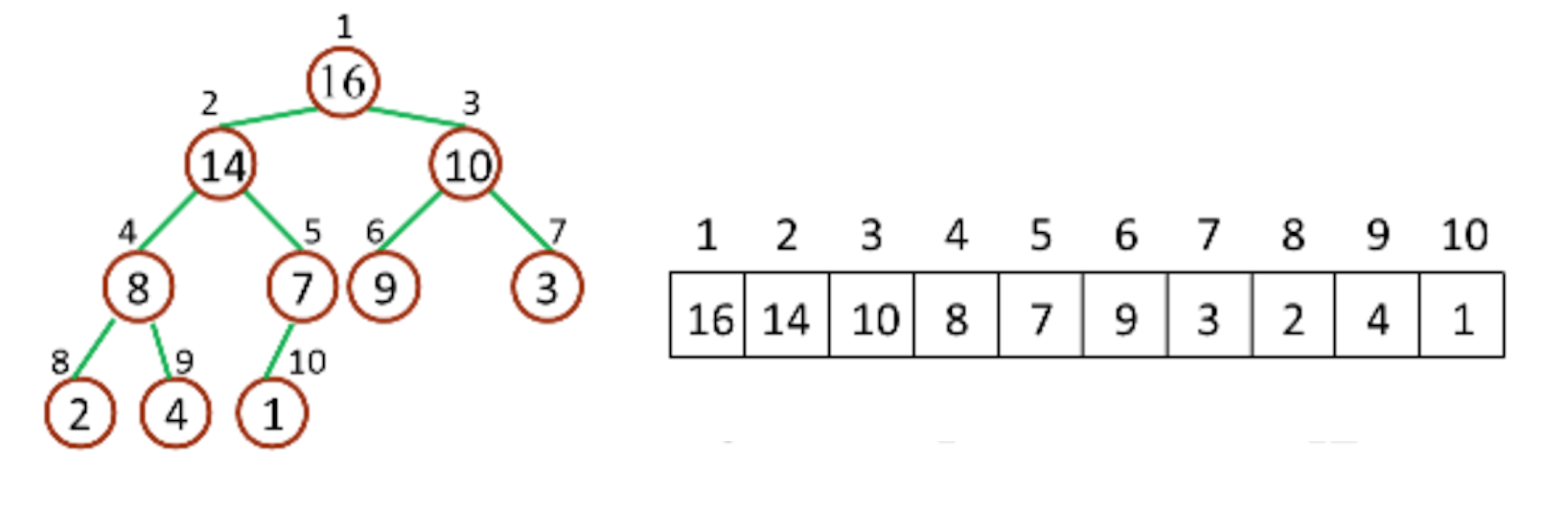
大顶堆:父节点大于子节点,二叉树的根(堆顶)最大。
小顶堆:父节点小于子节点,二叉树的根(堆顶)最小。
3.1 大顶堆
3.1.1 实现原理
主要实现功能有:
- 新增元素:insert
- 删除最大元素:delMax
要实现上面两个功能需要理解两个堆化步骤:
上浮:
下面我们在该堆中插入一个新的元素26:
比较父节点的新节点的大小,如果新元素更大则交换两个元素的位置,这个操作就相当于把该元素上浮了一下
递归该操作直到26到了一个满足堆条件的位置,此时就完成了插入的操作: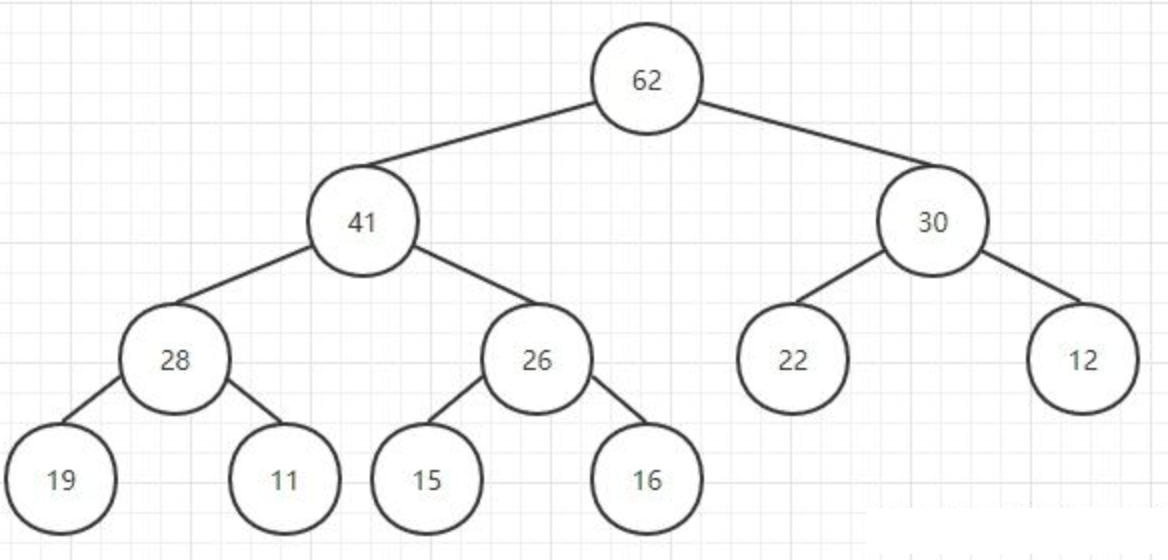
下沉:
取出堆中的最大元素,最后一个元素替换掉栈顶元素,然后把最后一个元素删除掉.取出62元素。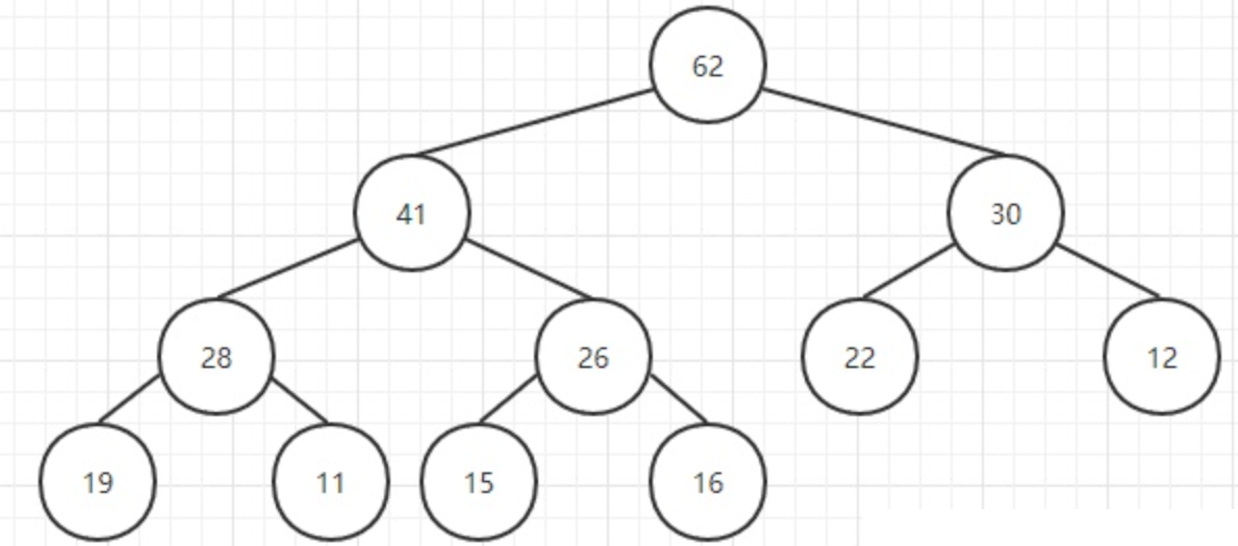
用最后元素替换掉栈顶元素,然后删除最后一个元素:
然后比较其孩子结点的大小:
如果不满足堆的条件,那么就跟孩子结点中较大的一个交换位置:
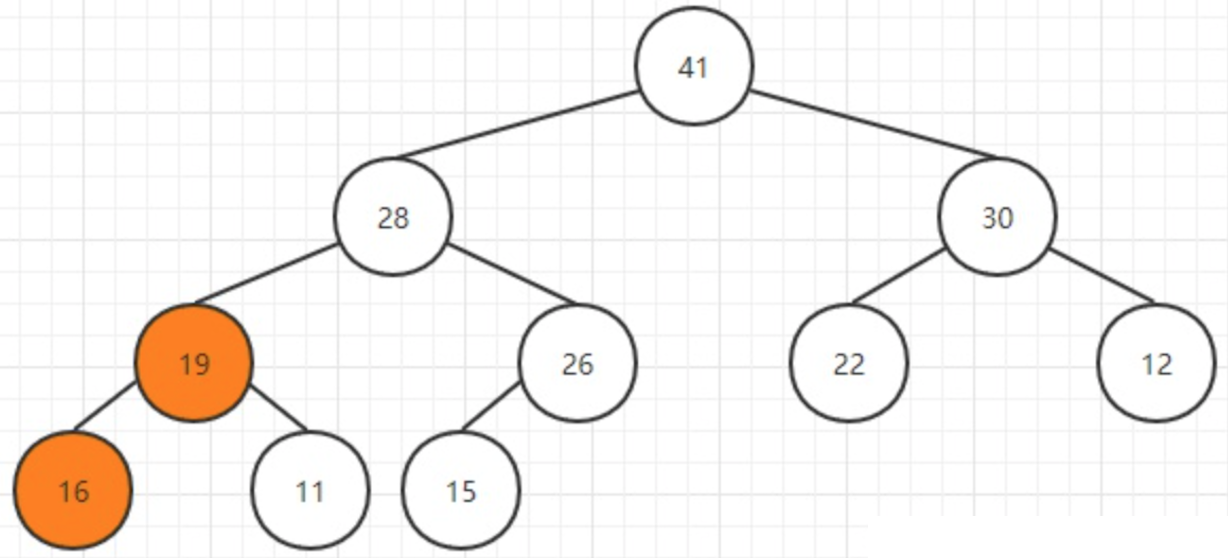
3.1.2代码实现
大顶堆的实现,
package com.ycc.data.structure.heap;/*** 大顶堆** @author liaozx* @date 2020-11-27*/public class MaxHeap<T extends Comparable<T>> {//存储堆中的元素private final T[] items;//记录堆中元素的个数private int current;public MaxHeap(int capacity) {this.items = (T[]) new Comparable[capacity + 1];this.current = 0;}/*** 判断堆中索引i处的元素是否小于索引j处的元素* i<j** @param i* @param j* @return*/private boolean less(int i, int j) {return items[i].compareTo(items[j]) < 0;}/*** 交换堆中i索引和j索引处的值** @param i* @param j*/private void swap(int i, int j) {T temp = items[i];items[i] = items[j];items[j] = temp;}/*** 往堆中插入一个元素** @param t*/public void insert(T t) {items[++current] = t;siftUp(current);}/*** 使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置** @param k*/private void siftUp(int k) {//通过循环,不断的比较当前结点的值和其父结点的值,如果发现父结点的值比当前结点的值小,则交换位置while (k > 1) {//比较当前结点和其父结点if (less(k / 2, k)) {swap(k / 2, k);}//上级节点k = k / 2;}}/*** 删除堆中最大的元素,并返回这个最大元素** @return*/public T delMax() {T max = items[1];//交换索引1处的元素和最大索引处的元素,让完全二叉树中最右侧的元素变为临时根结点swap(1, current);//最大索引处的元素删除掉items[current] = null;//元素个数-1current--;//通过下沉调整堆,让堆重新有序siftDown(1);return max;}/*** 使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置** @param k*/private void siftDown(int k) {//通过循环不断的对比当前k结点和其左子结点2*k以及右子结点2k+1处中的较大值的元素大小,如果当前结点小,则需要交换位置while (2 * k <= current) {//获取当前结点的子结点中的较大结点int max;//记录较大结点所在的索引if (2 * k + 1 <= current) {if (less(2 * k, 2 * k + 1)) {max = 2 * k + 1;} else {max = 2 * k;}} else {max = 2 * k;}//比较当前结点和较大结点的值if (!less(k, max)) {break;}//交换k索引处的值和max索引处的值swap(k, max);//变换k的值k = max;}}}
测试代码
package com.ycc.data.structure.heap.test;import com.ycc.data.structure.heap.MaxHeap;/*** @author liaozx* @date 2020-11-27*/public class MaxHeapTest {public static void main(String[] args) {MaxHeap<String> heap = new MaxHeap<String>(20);heap.insert("1");heap.insert("2");heap.insert("3");heap.insert("4");heap.insert("5");heap.insert("6");heap.insert("7");String del;while ((del = heap.delMax()) != null) {System.out.print(del + ",");}}}
3.2 小顶堆
3.2.1 实现原理
主要实现功能有:
- 新增元素:insert
- 删除最小元素:delMin
要实现上面两个功能需要理解两个堆化步骤:
上浮:
参考大顶堆
下沉:
参考大顶堆
3.2.2 代码实现
package com.ycc.data.structure.heap;/*** 小顶堆** @author liaozx* @date 2020-11-27*/public class MinHeap<T extends Comparable<T>> {//存储堆中的元素private final T[] items;//记录堆中元素的个数private int current;/*** 从1开始** @param capacity*/public MinHeap(int capacity) {this.items = (T[]) new Comparable[capacity + 1];this.current = 0;}//判断堆中索引i处的元素是否小于索引j处的元素private boolean less(int i, int j) {return items[i].compareTo(items[j]) < 0;}//交换堆中i索引和j索引处的值private void swap(int i, int j) {T tmp = items[i];items[i] = items[j];items[j] = tmp;}//往堆中插入一个元素public void insert(T t) {items[++current] = t;siftUp(current);}//使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置private void siftUp(int k) {//通过循环比较当前结点和其父结点的大小while (k > 1) {if (less(k, k / 2)) {swap(k, k / 2);}k = k / 2;}}//删除堆中最小的元素,并返回这个最小元素public T delMin() {T min = items[1];swap(1, current);//最小索引处的元素删除掉items[current] = null;current--;siftDown(1);return min;}//使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置private void siftDown(int k) {//通过循环比较当前结点和其子结点中的较小值while (2 * k <= current) {//1.找到子结点中的较小值int min;if (2 * k + 1 <= current) {if (less(2 * k, 2 * k + 1)) {min = 2 * k;} else {min = 2 * k + 1;}} else {min = 2 * k;}//2.判断当前结点和较小值的大小if (less(k, min)) {break;}swap(k, min);k = min;}}}
测试代码
package com.ycc.data.structure.heap.test;import com.ycc.data.structure.heap.MinHeap;/*** @author liaozx* @date 2020-11-27*/public class MinHeapTest {public static void main(String[] args) {MinHeap<String> heap = new MinHeap<String>(20);heap.insert("7");heap.insert("4");heap.insert("2");heap.insert("1");heap.insert("3");heap.insert("5");heap.insert("6");String del;while ((del = heap.delMin()) != null) {System.out.print(del + ",");}}}
四 优先队列
优先队列也是一种队列,只不过不同的是,优先队列的出队顺序是按照优先级来的,底层数据结构就是基于二叉堆的。
4.1 最大优先队列
可以获取并删除队列中最大的值
package com.ycc.data.structure.heap;/*** 最大优先队列** @author liaozx* @date 2020-11-27*/public class MaxPriorityQueue<E extends Comparable<E>> {private final MaxHeap<E> maxHeap;public MaxPriorityQueue() {maxHeap = new MaxHeap<E>(20);}public void enqueue(E e) {maxHeap.insert(e);}public E dequeue() {return maxHeap.delMax();}}
4.2 最小优先队列
可以获取并删除队列中最小的值
package com.ycc.data.structure.heap;/*** 最小优先队列** @author liaozx* @date 2020-11-27*/public class MinPriorityQueue<E extends Comparable<E>> {private final MinHeap<E> minHeap;public MinPriorityQueue() {minHeap = new MinHeap<E>(20);}public void enqueue(E e) {minHeap.insert(e);}public E dequeue() {return minHeap.delMin();}}
4.3 索引优先队列
最大优先队列和最小优先队列,他们可以分别快速访问到队列中最大元素和最小元素,但是他们有一个缺点,就是没有办法通过索引访问已存在于优先队列中的对象。但是我们可以给元素关联一个key,然后通过这个key查询这个value。
4.3.1 最小索引优先队列原理
- 索引关联
| 元数据
T[]items | 数组的索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 将来需堆化存储 | | :—-: | :—-: | :—-: | :—-: | :—-: | :—-: | :—-: | :—-: | :—-: | :—-: | :—-: | :—-: | :—-: | :—-: | | | value | S | O | R | T | E | X | A | M | P | L | E | 真实的数据无序的 | | 因为上面的数据,不能堆化,如果堆化,则会上浮或者下沉操作,即数据与索引的对应关系发生change,因此我们要堆化索引即可,如下图所示(最小的数据的索引在最上面): | | | | | | | | | | | | | | |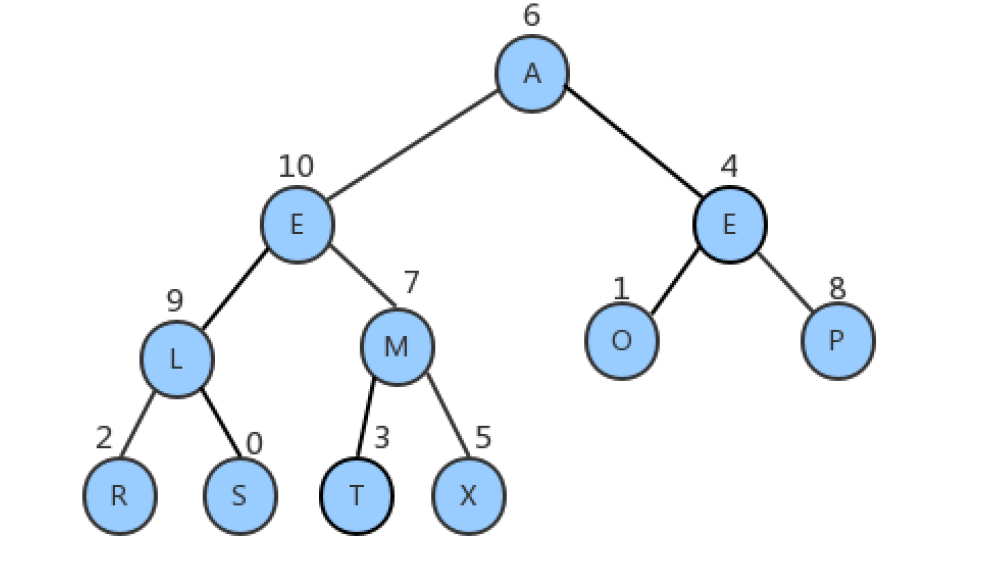
将上面的索引保存到下面的数组中
⏬ | | | | | | | | | | | | | | | pq存数据索引 | 数组的索引 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 堆从1开始,不是0 | | | 存储items索引 | 6 | 10 | 4 | 9 | 7 | 1 | 8 | 2 | 0 | 3 | 5 | 堆化后的索引 | | 如果我们查询S元素,即遍历pq,判断value=0,即获取了s元素,但是这个效率很低,需要我们去遍历。
因此我们还有一个辅助数组,存pq的索引。 | | | | | | | | | | | | | | | qp存pq的索引 | 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | items的索引 | | | 存pq的索引 | 9 | 6 | 8 | 10 | 3 | 11 | 1 | 5 | 7 | 4 | 2 | 存储pq的索引 | | 既然qp数组存储了pq的索引,那么我们很容易定位元素。比如我们需要更新s的值,那么元素S对应的索引是0,我们根据0从qp中获取pq的索引,即9。 | | | | | | | | | | | | | |
4.3.1 最小索引优先队列代码实现
package com.ycc.data.structure.heap;public class IndexMinPriorityQueue<T extends Comparable<T>> {/*** 普通数组 存储堆中的元素*/private final T[] items;/*** 二叉堆,保存每个元素在items数组中的索引,pq数组需要堆有序*/private final int[] pq;/*** 普通数组 保存qp的逆序,pq的值作为索引,pq的索引作为值*/private final int[] qp;//记录堆中元素的个数private int current;public IndexMinPriorityQueue(int capacity) {this.items = (T[]) new Comparable[capacity + 1];this.pq = new int[capacity + 1];this.qp = new int[capacity + 1];this.current = 0;//默认情况下,队列中没有存储任何数据,让qp中的元素都为-1;for (int i = 0; i < qp.length; i++) {qp[i] = -1;}}//判断堆中索引i处的元素是否小于索引j处的元素private boolean less(int i, int j) {return items[pq[i]].compareTo(items[pq[j]]) < 0;}//交换堆中i索引和j索引处的值private void swap(int i, int j) {//交换pq中的数据int tmp = pq[i];pq[i] = pq[j];pq[j] = tmp;//更新qp中的数据,pq[i]即为items元素的索引,即qp[元素索引]存储pq的索引qp[pq[i]] = i;qp[pq[j]] = j;}//判断k对应的元素是否存在public boolean contains(int k) {return qp[k] != -1;}//往队列中插入一个元素,并关联索引ipublic void insert(int i, T t) {//判断i是否已经被关联,如果已经被关联,则不让插入if (contains(i)) {return;}//元素个数+1current++;//把数据存储到items对应的i位置处items[i] = t;//把i对应的索引,存储到pq中,即在末尾存储元数据的索引pq[current] = i;//通过qp来记录,pq存储元数据(元数据对应的索引)的索引qp[i] = current;//通过堆上浮完成堆的调整siftUp(current);}//删除队列中最小的元素,并返回该元素关联的索引public int delMin() {//获取最小元素关联的索引int minIndex = pq[1];//交换pq中索引1处和最大索引处的元素swap(1, current);//删除qp中对应的内容qp[pq[current]] = -1;//删除pq最大索引处的内容pq[current] = -1;//删除items中对应的内容items[minIndex] = null;//元素个数-1current--;//下沉调整siftDown(1);return minIndex;}//删除索引i关联的元素public void delete(int i) {//找到i在pq中的索引int k = qp[i];//交换pq中索引k处的值和索引N处的值swap(k, current);//删除qp中的内容qp[pq[current]] = -1;//删除pq中的内容pq[current] = -1;//删除items中的内容items[k] = null;//元素的数量-1current--;//堆的调整siftDown(k);siftUp(k);}//把与索引i关联的元素修改为为tpublic void changeItem(int i, T t) {//修改items数组中i位置的元素为titems[i] = t;//找到i在pq中出现的位置int k = qp[i];//堆调整siftDown(k);siftUp(k);}/*** 使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置** @param k*/private void siftUp(int k) {while (k > 1) {if (less(k, k / 2)) {swap(k, k / 2);}k = k / 2;}}//使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置private void siftDown(int k) {while (2 * k <= current) {//找到子结点中的较小值int min;if (2 * k + 1 <= current) {if (less(2 * k, 2 * k + 1)) {min = 2 * k;} else {min = 2 * k + 1;}} else {min = 2 * k;}//比较当前结点和较小值if (less(k, min)) {break;}swap(k, min);k = min;}}}
五 AVL树
AVL树是高度平衡的而二叉树。它的特点是:AVL树中任何节点的两个子树的高度最大差别为1。
右图:7的左子树(即2为根的树)高度为:3 ,右子树(即8为根的树)的高度为:1,则高度差2>1即不是平衡树。
5.1 实现原理
5.1.1 失衡的情况分析


总的来说,AVL树失去平衡时的情况一定是LL、LR、RL、RR这4种之一,它们都由各自的定义:
LL:LeftLeft,也称为”左左”。插入或删除一个节点后,根节点的左子树的左子树还有非空子节点,导致”根的左子树的高度”比”根的右子树的高度”大2,导致AVL树失去了平衡。
例如,在上面LL情况中,由于”根节点(8)的左子树(4)的左子树(2)还有非空子节点”,而”根节点(8)的右子树(12)没有子节点”;导致”根节点(8)的左子树(4)高度”比”根节点(8)的右子树(12)”高2。
LR:LeftRight,也称为”左右”。插入或删除一个节点后,根节点的左子树的右子树还有非空子节点,导致”根的左子树的高度”比”根的右子树的高度”大2,导致AVL树失去了平衡。
例如,在上面LR情况中,由于”根节点(8)的左子树(4)的左子树(6)还有非空子节点”,而”根节点(8)的右子树(12)没有子节点”;导致”根节点(8)的左子树(4)高度”比”根节点(8)的右子树(12)”高2。
RL:RightLeft,称为”右左”。插入或删除一个节点后,根节点的右子树的左子树还有非空子节点,导致”根的右子树的高度”比”根的左子树的高度”大2,导致AVL树失去了平衡。
例如,在上面RL情况中,由于”根节点(8)的右子树(12)的左子树(10)还有非空子节点”,而”根节点(8)的左子树(4)没有子节点”;导致”根节点(8)的右子树(12)高度”比”根节点(8)的左子树(4)”高2。
RR:RightRight,称为”右右”。插入或删除一个节点后,根节点的右子树的右子树还有非空子节点,导致”根的右子树的高度”比”根的左子树的高度”大2,导致AVL树失去了平衡。
例如,在上面RR情况中,由于”根节点(8)的右子树(12)的右子树(14)还有非空子节点”,而”根节点(8)的左子树(4)没有子节点”;导致”根节点(8)的右子树(12)高度”比”根节点(8)的左子树(4)”高2。
_
如果在AVL树中进行插入或删除节点后,可能导致AVL树失去平衡。AVL失去平衡之后,可以通过旋转使其恢复平衡,下面分别介绍”LL(左左),LR(左右),RR(右右)和RL(右左)”这4种情况对应的旋转方法。
5.1.2 选择平衡分析
LL的旋转:
LL失去平衡的情况,可以通过一次旋转让AVL树恢复平衡。如下图:
RR的旋转:
理解了LL之后,RR就相当容易理解了。RR是与LL对称的情况!RR恢复平衡的旋转方法如下:
LR的旋转:
LR失去平衡的情况,需要经过两次旋转才能让AVL树恢复平衡。如下图:
RL的旋转:
RL是与LR的对称情况!RL恢复平衡的旋转方法如下:
5.2 代码实现
package com.ycc.data.structure.tree;/*** https://www.cnblogs.com/skywang12345/p/3577479.html** @author liaozx* @description 平衡二叉树* @create 2020-11-27 11:02*/public class AVLTree<T extends Comparable<T>> {private Node<T> root; // 根结点// AVL树的节点(内部类)private class Node<T extends Comparable<T>> {// 关键字(键值)private T key;// 高度private int height;// 左孩子private Node<T> left;// 右孩子private Node<T> right;public Node(T key) {this.key = key;}}// 构造函数public AVLTree() {root = null;}/** 获取树的高度*/private int height(Node<T> tree) {if (tree != null)return tree.height;return 0;}public int height() {return height(root);}/** 比较两个值的大小*/private int max(int a, int b) {return a > b ? a : b;}public Node<T> search(T key) {return search(root, key);}/** (递归实现)查找"AVL树x"中键值为key的节点*/private Node<T> search(Node<T> x, T key) {if (x == null)return x;int cmp = key.compareTo(x.key);if (cmp < 0)return search(x.left, key);else if (cmp > 0)return search(x.right, key);elsereturn x;}public Node<T> iterativeSearch(T key) {return iterativeSearch(root, key);}/** (非递归实现)查找"AVL树x"中键值为key的节点*/private Node<T> iterativeSearch(Node<T> x, T key) {while (x != null) {int cmp = key.compareTo(x.key);if (cmp < 0)x = x.left;else if (cmp > 0)x = x.right;elsereturn x;}return x;}/** 查找最小结点:返回tree为根结点的AVL树的最小结点。*/private Node<T> minimum(Node<T> tree) {if (tree == null)return null;while (tree.left != null)tree = tree.left;return tree;}public T minimum() {Node<T> p = minimum(root);if (p != null)return p.key;return null;}/** 查找最大结点:返回tree为根结点的AVL树的最大结点。*/private Node<T> maximum(Node<T> tree) {if (tree == null)return null;while (tree.right != null)tree = tree.right;return tree;}public T maximum() {Node<T> p = maximum(root);if (p != null)return p.key;return null;}/** LL:左左对应的情况(右单旋转)。** 10* * ** * ** 6 15* ** ** 4* ** ** 2*** 10* * ** 4 15* * ** 2 6* ** 1*** 返回值:旋转后的根节点*/private Node<T> lLRotation(Node<T> k2) {//获取左节点,然后k1即将升为根节点Node<T> k1 = k2.left;//k1的右节点,变成k2的左子节点k2.left = k1.right;//k1升级为根节点,即上级节点k1.right = k2;//k2的树高度k2.height = max(height(k2.left), height(k2.right)) + 1;//k1的树高度k1.height = max(height(k1.left), k2.height) + 1;return k1;}/** RR:右右对应的情况(左单旋转)。** 返回值:旋转后的根节点*/private Node<T> rRRotation(Node<T> k1) {//获取右节点,然后k2即将升为根节点Node<T> k2 = k1.right;//k1即将变成左子节点,且k1的有孩子,即k2的左孩子k1.right = k2.left;//k1 变成更节点k2.left = k1;k1.height = max(height(k1.left), height(k1.right)) + 1;k2.height = max(height(k2.right), k1.height) + 1;return k2;}/** LR:左右对应的情况(左双旋转)。*** 10* ** ** 6* ** ** 8* 返回值:旋转后的根节点** 左右先掰直,即先左旋变成LL,然后在在右旋*/private Node<T> leftRightRotation(Node<T> k3) {k3.left = rRRotation(k3.left); //先左旋,掰直成左斜杠return lLRotation(k3);//再右旋,掰弯成倒三角平衡了}/** RL:右左对应的情况(右双旋转)。** 返回值:旋转后的根节点*/private Node<T> rightLeftRotation(Node<T> k1) {k1.right = lLRotation(k1.right);//先右旋,掰直成右斜杠return rRRotation(k1);//再左旋,掰弯成倒三角平衡了}public void insert(T key) {root = insert(root, key);}/** 将结点插入到AVL树中,并返回根节点** 参数说明:* tree AVL树的根结点* key 插入的结点的键值* 返回值:* 根节点** 16* * ** * ** 10 20* * ** * ** 6 14* ** ** 4*/private Node<T> insert(Node<T> tree, T key) {if (tree == null) {// 新建节点tree = new Node<T>(key);} else {int cmp = key.compareTo(tree.key);if (cmp < 0) {// 应该将key插入到"tree的左子树"的情况tree.left = insert(tree.left, key);// 插入节点后,若AVL树失去平衡,则进行相应的调节。if (height(tree.left) - height(tree.right) == 2) {if (key.compareTo(tree.left.key) < 0) // 比左孩子小(如上图 4<6) 则是左左,即右旋tree = lLRotation(tree);//右旋else //左右 即8>6tree = leftRightRotation(tree);//左双旋}} else if (cmp > 0) { // 应该将key插入到"tree的右子树"的情况tree.right = insert(tree.right, key);// 插入节点后,若AVL树失去平衡,则进行相应的调节。if (height(tree.right) - height(tree.left) == 2) {if (key.compareTo(tree.right.key) > 0) //比右边孩子大 则是右右,即左旋tree = rRRotation(tree);//左旋elsetree = rightLeftRotation(tree);//右双旋}} else { // cmp==0System.out.println("添加失败:不允许添加相同的节点!");}}tree.height = max(height(tree.left), height(tree.right)) + 1;return tree;}public void remove(T key) {Node<T> z;if ((z = search(root, key)) != null)root = remove(root, z);}/** 删除结点(z),返回根节点** 参数说明:* tree AVL树的根结点* z 待删除的结点* 返回值:* 根节点*/private Node<T> remove(Node<T> tree, Node<T> z) {// 根为空 或者 没有要删除的节点,直接返回null。if (tree == null || z == null)return null;int cmp = z.key.compareTo(tree.key);if (cmp < 0) {// 待删除的节点在"tree的左子树"中tree.left = remove(tree.left, z);// 删除节点后,若AVL树失去平衡,则进行相应的调节。if (height(tree.right) - height(tree.left) == 2) {Node<T> r = tree.right;if (height(r.left) > height(r.right))tree = rightLeftRotation(tree);elsetree = rRRotation(tree);}} else if (cmp > 0) {// 待删除的节点在"tree的右子树"中tree.right = remove(tree.right, z);// 删除节点后,若AVL树失去平衡,则进行相应的调节。if (height(tree.left) - height(tree.right) == 2) {Node<T> l = tree.left;if (height(l.right) > height(l.left))tree = leftRightRotation(tree);elsetree = lLRotation(tree);}} else { // tree是对应要删除的节点。// tree的左右孩子都非空if ((tree.left != null) && (tree.right != null)) {if (height(tree.left) > height(tree.right)) {// 如果tree的左子树比右子树高;// 则(01)找出tree的左子树中的最大节点// (02)将该最大节点的值赋值给tree。// (03)删除该最大节点。// 这类似于用"tree的左子树中最大节点"做"tree"的替身;// 采用这种方式的好处是:删除"tree的左子树中最大节点"之后,AVL树仍然是平衡的。Node<T> max = maximum(tree.left);tree.key = max.key;tree.left = remove(tree.left, max);} else {// 如果tree的左子树不比右子树高(即它们相等,或右子树比左子树高1)// 则(01)找出tree的右子树中的最小节点// (02)将该最小节点的值赋值给tree。// (03)删除该最小节点。// 这类似于用"tree的右子树中最小节点"做"tree"的替身;// 采用这种方式的好处是:删除"tree的右子树中最小节点"之后,AVL树仍然是平衡的。Node<T> min = maximum(tree.right);tree.key = min.key;tree.right = remove(tree.right, min);}} else {Node<T> tmp = tree;tree = (tree.left != null) ? tree.left : tree.right;tmp = null;}}return tree;}/** 销毁AVL树*/private void destroy(Node<T> tree) {if (tree == null)return;if (tree.left != null)destroy(tree.left);if (tree.right != null)destroy(tree.right);tree = null;}public void destroy() {destroy(root);}/** 打印"二叉查找树"** key -- 节点的键值* direction -- 0,表示该节点是根节点;* -1,表示该节点是它的父结点的左孩子;* 1,表示该节点是它的父结点的右孩子。*/private void print(Node<T> tree, T key, int direction) {if (tree != null) {if (direction == 0) // tree是根节点System.out.printf("%2d is root\n", tree.key, key);else // tree是分支节点System.out.printf("%2d is %2d's %6s child\n", tree.key, key, direction == 1 ? "right" : "left");print(tree.left, tree.key, -1);print(tree.right, tree.key, 1);}}public void print() {if (root != null)print(root, root.key, 0);}}
5.3总结分析
AVL更平衡,结构上更加直观,时间效能针对读取而言更高;维护稍慢,空间开销较大。
六 2-3树
一棵2-3查找树要么为空,要么满足满足下面两个要求。
2-结点:
含有一个键(及其对应的值)和两条腿,左腿接指向2-3树中的键都小于该结点,右腿接指向的2-3树中的键都大于该结点。
3-结点:
含有两个键(及其对应的值)和三条腿,左腿接指向的2-3树中的键都小于该结点,中腿接指向的2-3树中的键都
位于该结点的两个键之间,右腿接指向的2-3树中的键都大于该结点。
6.1 树实现原理
6.1.2 插入原理
- 向2-结点中插入新键,则变成3-结点

- 向一棵只含有一个3-结点的树中插入新键,即满四进二

- 向一个父结点为2-结点,子节点为3-结点中插入新键
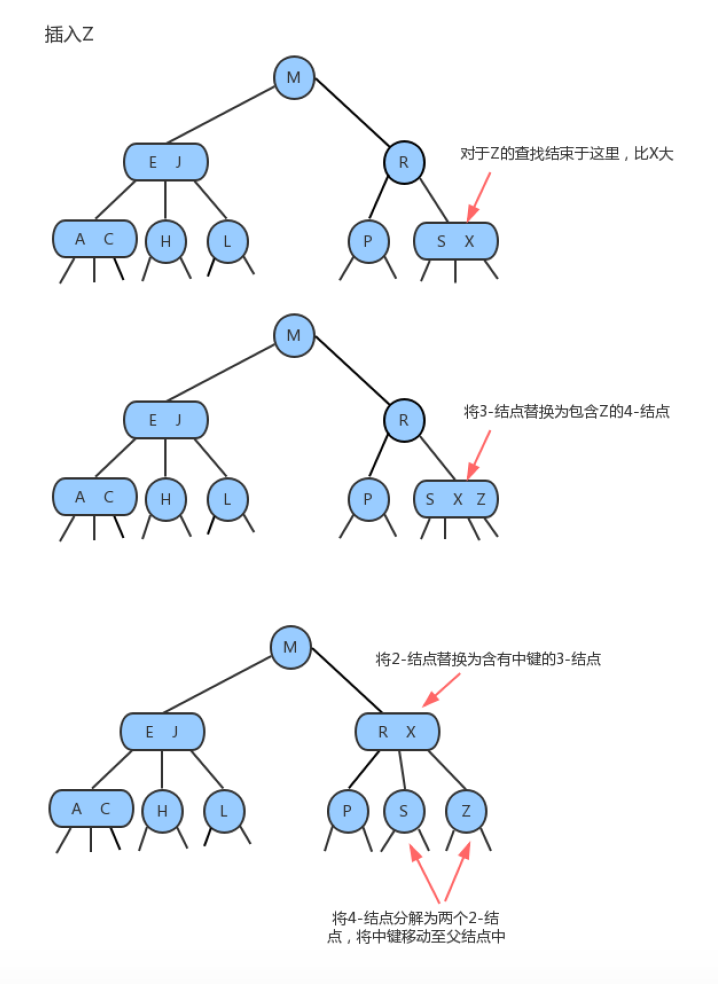

6.2 代码实现
6.3 总结分析
- 任意空链接到根结点的路径长度都是相等的。
- 4-结点变换为3-结点时,树的高度不会发生变化,只有当根结点是临时的4-结点,分解根结点时,树高+1。
- 2-3树与普通二叉查找树最大的区别在于,普通的二叉查找树是自顶向下生长,而2-3树是自底向上生长。
七 红黑树
红黑树主要是对2-3树进行编码,红黑树背后的基本思想是用标准的二叉查找树(完全由2-结点构成)和一些额外的信息(替换3-结点)来表示2-3树。
我们将树中的链接分为两种类型:红链接:将两个2-结点连接起来构成一个3-结点; 黑链接:则是2-3树中的普通链接。
红黑树是含有红黑链接并满足下列条件的二叉查找树:
1. 红链接均为左链接;
2. 没有任何一个结点同时和两条红链接相连;
3. 该树是完美黑色平衡的,即任意空链接到根结点的路径上的黑链接数量相同;
7.1 实现原理
7.1.1 插入原理
向单个2-结点中插入新键

- 颜色反转
当一个结点的左右子结点的color都为RED时,也就是出现了临时的4-结点,此时只需要把左右子结点的颜色变为BLACK,同时让当前结点的颜色变为RED即可。
- 向一棵双键树(即一个3-结点)中插入新键
- 新键大于原树中的两个键,则插入右红子节点(左右红失衡,需要颜色反转)

- 新键小于原树中的两个键,(左左红,失衡)

- 新键介于原数中两个键之间(左右红失衡)
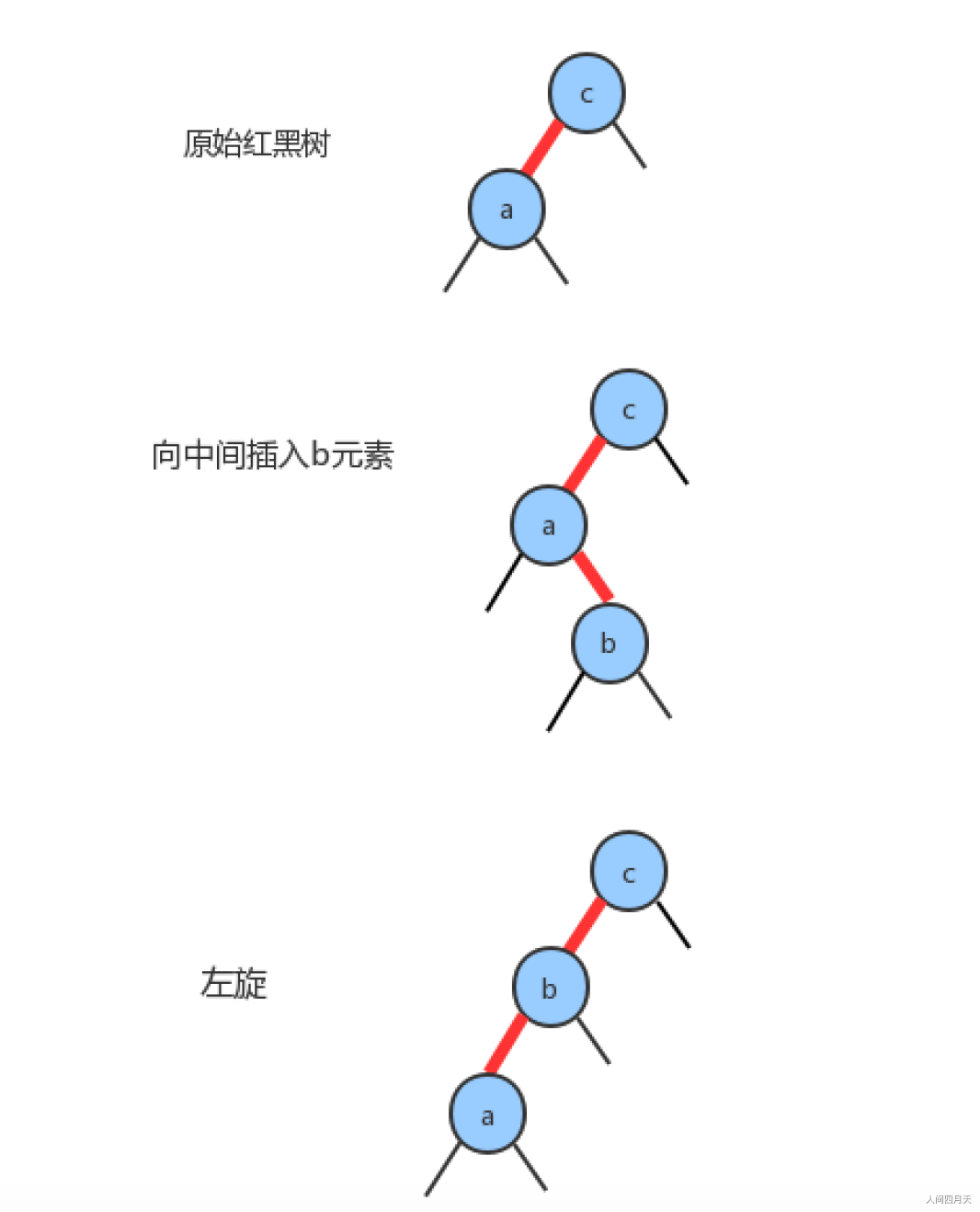
7.1.2 左旋平衡
右红是失衡的,必须调整即:
当某个结点的左子结点为黑色,右子结点为红色,此时需要左旋。
前提:当前结点为h,它的右子结点为x;
左旋过程:
- 让x的左子结点变为h的右子结点:h.right=x.left;
- 让h成为x的左子结点:x.left=h;
- 让h的color属性变为x的color属性值:x.color=h.color;
- 让h的color属性变为RED:h.color=true;

7.1.3 右旋平衡
当某个结点的左子结点是红色,且左子结点的左子结点也是红色,需要右旋
前提:当前结点为h,它的左子结点为x;
右旋过程:
- 让x的右子结点成为h的左子结点:h.left = x.right;
- 让h成为x的右子结点:x.right=h;
- 让x的color变为h的color属性值:x.color = h.color;
- 让h的color为RED;

7.1.4 失衡归纳分析
我们前面研究平衡树叶做了类似的归纳 左左,左右 右右,右左,这里也有类似总结:
- 右红
即红黑树,不允许有右红链,所以,它会及时的左旋,变成左链红,即也就避免了,右右的出现,也避免了右左的出现
- 左左红
左子树红色,左孙子树也是红色,所以它需要先右旋,即先掰弯成一个倒三角,在颜色反转
- 左右红
左子树为红色,右孙子树为红色,则需要先调整右红(1的情况),左旋,变成左左(2的情况),总结起来,是先掰直,再掰弯,再颜色反转。
7.1.5 总结
通过上面的分析,不难看出,红黑树的失衡情况要好于AVL树,因此在做插入删除操作,其红黑树的性能高些,当然查询当然AVL树的效率高些,因为我比较平衡。即成也平衡,败也平衡,凡是过犹不及(追求平衡导致频繁旋转,影响删除,插入)。
7.2 代码实现
package com.ycc.data.structure.tree;/*** 红黑二叉树** @param <Key>* @param <Value>*/public class RedBlackTree<Key extends Comparable<Key>, Value> {/*** 红色链接*/private static final boolean RED = true;/*** 黑色链接*/private static final boolean BLACK = false;/*** 根节点*/private Node root;/*** 记录树中元素的个数*/private int current;//获取树中元素的个数public int size() {return current;}/*** 判断当前节点的父指向链接是否为红色** @param x* @return*/private boolean isRed(Node x) {if (x == null) {return false;}return x.color == RED;}/*** 右红链需左旋转** @param h* @return*/private Node rotateLeft(Node h) {//找到h结点的右子结点xNode x = h.right;//找到x结点的左子结点,让x结点的左子结点称为h结点的右子结点h.right = x.left;//让h结点称为x结点的左子结点x.left = h;//让x结点的color属性变为h结点的color属性x.color = h.color;//让h结点的color属性变为REDh.color = RED;return x;}/*** 右旋** @param h* @return*/private Node rotateRight(Node h) {//找到h结点的左子结点 xNode x = h.left;//让x结点的右子结点成为h结点的左子结点h.left = x.right;//让h结点成为x结点的右子结点x.right = h;//让x结点的color属性变为h结点的color属性x.color = h.color;//让h结点的color属性为REDh.color = RED;return x;}/*** 颜色反转,相当于完成拆分4-节点** @param h*/private void flipColors(Node h) {//当前结点变为红色h.color = RED;//左子结点和右子结点变为黑色h.left.color = BLACK;h.right.color = BLACK;}/*** 在整个树上完成插入操作** @param key* @param val*/public void put(Key key, Value val) {root = put(root, key, val);//根结点的颜色总是黑色root.color = RED;}/*** 在指定树中,完成插入操作,并返回添加元素后新的树** @param h* @param key* @param val*/private Node put(Node h, Key key, Value val) {//判断h是否为空,如果为空则直接返回一个红色的结点就可以了if (h == null) {//数量+1current++;return new Node(key, val, null, null, RED);}//比较h结点的键和key的大小int cmp = key.compareTo(h.key);if (cmp < 0) {//继续往左h.left = put(h.left, key, val);} else if (cmp > 0) {//继续往右h.right = put(h.right, key, val);} else {//发生值的替换h.value = val;}//进行左旋:当当前结点h的左子结点为黑色,右子结点为红色,需要左旋if (isRed(h.right) && !isRed(h.left)) {h = rotateLeft(h);}//进行右旋:当当前结点h的左子结点和左子结点的左子结点都为红色,需要右旋if (isRed(h.left) && isRed(h.left.left)) {rotateRight(h);}//颜色反转:当前结点的左子结点和右子结点都为红色时,需要颜色反转if (isRed(h.left) && isRed(h.right)) {flipColors(h);}return h;}//根据key,从树中找出对应的值public Value get(Key key) {return get(root, key);}//从指定的树x中,查找key对应的值public Value get(Node x, Key key) {if (x == null) {return null;}//比较x结点的键和key的大小int cmp = key.compareTo(x.key);if (cmp < 0) {return get(x.left, key);} else if (cmp > 0) {return get(x.right, key);} else {return x.value;}}//结点类private class Node {//存储键public Key key;//记录左子结点public Node left;//记录右子结点public Node right;//由其父结点指向它的链接的颜色public boolean color;//存储值private Value value;public Node(Key key, Value value, Node left, Node right, boolean color) {this.key = key;this.value = value;this.left = left;this.right = right;this.color = color;}}}
八 B-树
B树中允许一个结点中包含多个key,可以是3个、4个、5个甚至更多,并不确定,需要看具体的实现。现在我们选择一个参数M,来构造一个B树,我们可以把它称作是M阶的B树,那么该树会具有如下特点:
- 每个结点最多有M-1个key,并且以升序排列;
- 每个结点最多能有M个子结点;
- 根结点至少有两个子结点;

8.1 实现原理
若参数M选择为5,那么每个结点最多包含4个键值对,我们以5阶B树为例,看看B树的数据存储。
8.2 代码实现
代码较为复杂,了解即可
package com.ycc.data.structure.tree;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.util.ArrayList;import java.util.List;import java.util.NoSuchElementException;/*** 该程序参考文章:http://blog.csdn.net/v_JULY_v/article/details/6530142/* <p>* B-tree** @author liaozx* @description* @create 2020-11-27 15:31*/public class BSubTree<T extends Comparable<T>> {private static final BSubTree<Integer> tree = new BSubTree<Integer>();private static final BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));public BTNode root;int m = 4; //此B-树的阶数。关键字数等于阶数-1。m至少为2,m必须大于等于2。int n; //n是关键字最小个数public BSubTree() {root = new BTNode(null, null);if (m >= 2) {if (m % 2 == 0) {n = m / 2 - 1;} else {n = m / 2;}} else {System.out.println("error");System.exit(0);}}public BSubTree(BTNode root) {this.root = root;if (m % 2 == 0) {n = m / 2;} else {n = m / 2 + 1;}}private static String stringInput(String inputRequest) throws IOException {System.out.println(inputRequest);return reader.readLine();}public static void main(String[] args) throws IOException {System.out.println("test B - balanced tree operations");System.out.println("*****************************");String input;Integer value;do {input = stringInput("please select: [i]nsert, [d]elete, [s]how, [e]xit");switch (input.charAt(0)) {case 'i':value = Integer.parseInt(stringInput("insert: "), 10);tree.insert(value);break;case 'd':value = Integer.parseInt(stringInput("delete: "), 10);tree.delete(value);break;case 's':System.out.println(tree.perOrder(tree.root));break;// case 'h':// System.out.println(tree.getHeight());}} while ((input.charAt(0) != 'e'));}public BTNode findNode(T information) {return findNode(information, root);} //isMember应该返回插入点private BTNode findNode(T info, BTNode node) { //不论是否找到都返回一个node。BTNode member = null;if (node.informations.size() == 0) {//这种情况存在,只有root可能member = node;//System.out.println("error");} else {if (info.compareTo(node.informations.get(node.informations.size() - 1)) > 0) { //info比节点最大的还大,则直接进入最右分支if (node.ptr.size() > 0) {//有孩子的情况,进入范围中的子节点member = findNode(info, node.ptr.get(node.informations.size()));} else {//没有子节点,直接返回nodemember = node;}} else {//没有判断没有子节点的情况,上一个if中判断了,这一个else中就忘了,怒if (node.ptr.size() > 0) {//有子节点if (info.compareTo(node.informations.get(0)) < 0) {member = findNode(info, node.ptr.get(0));} else {for (int i = 0; i < node.informations.size(); ++i) {if (info.compareTo(node.informations.get(i)) == 0) {member = node;break;} else if (info.compareTo(node.informations.get(i)) > 0 && info.compareTo(node.informations.get(i + 1)) < 0) { //只要不是最右,info比之大的,进入它的孩子节点member = findNode(info, node.ptr.get(i + 1));break;}}}} else {//没有子节点member = node;}}}return member;}public void insert(T info) {BTNode temp = findNode(info);if (temp.informations.size() != 0) {for (T i : temp.informations) {if (i.compareTo(info) == 0) {System.out.println("已存在所插入的值。");return;}}}insert(info, temp, temp.parent);return;}private void insert(T info, BTNode node, BTNode parent) {//插入一定是在叶子节点if (node == null) {//insert中的node为空应该只有一种情况,node=rootif (parent == null) {root = new BTNode(info, parent);} else {System.out.println("不应该出现的情况,请检查。");//node = new BTNode(info,parent);}} else {if (node.informations.size() == 0) {//System.out.println("这种情况应该不存在,请检查代码");//现在存在这种情况啦node.informations.add(info);} else if (node.informations.size() > 0 && node.informations.size() < m - 1) {if (info.compareTo(node.informations.get(node.informations.size() - 1)) > 0) {//info比node最右边最大的值还大,则直接插入node.informations.add(info);} else {for (int i = 0; i < node.informations.size(); ++i) {if (info.compareTo(node.informations.get(i)) < 0) {node.informations.add(i, info);break;}}}} else if (node.informations.size() == m - 1) {//需要分裂if (info.compareTo(node.informations.get(node.informations.size() - 1)) > 0) {//info比node最右边最大的值还大,则直接插入node.informations.add(info);} else {for (int i = 0; i < node.informations.size(); ++i) {if (info.compareTo(node.informations.get(i)) < 0) {node.informations.add(i, info);break;}}}split(node);} else {System.out.println("node 的size大于等于m-1,不应该出现,请检查代码");}}}public void delete(T info) {BTNode temp = findNode(info, root);if (temp.informations.size() == 0) {System.out.println("根节点为空!");return;}for (T i : temp.informations) {if (info.compareTo(i) == 0) {delete(info, temp);break;} else if (temp.informations.indexOf(i) == temp.informations.size() - 1) {//循环到最后一个值了,仍到这里,说明不存在要删除的值!System.out.println("不存在要删除的值!");}}}private void delete(T info, BTNode node) throws NoSuchElementException {if (node == null) { //其实到这里,就一定存在要删除的值了。throw new NoSuchElementException();} else {int i;for (i = 0; i < node.informations.size(); i++) {if (info.compareTo(node.informations.get(i)) == 0) {node.informations.remove(i); //删除关键字,其实要是索引向文件,也应该删除文件。break;}}if (node.ptr.size() > 0) {//删除一个非叶子节点的关键字后,如果有孩子,则判断孩子的孩子,如果孩子有孩子,则将右孩子的孩子最深左孩子的第一个值赋给删除关键字的节点//每一个关键字,一定有两个孩子if (node.ptr.get(i + 1).ptr.size() == 0) {//孩子没有孩子的时候,只将孩子的最左关键字上升。node.informations.add(i, node.ptr.get(i + 1).informations.get(0));node.ptr.get(i + 1).informations.remove(0);if (node.ptr.get(i + 1).informations.size() < n) {dManageNode(node.ptr.get(i + 1));}} else {//孩子有孩子的时候,则将右孩子的孩子最深左孩子的第一个值赋给删除关键字的节点pullRLeftNode(node, i, node.ptr.get(i + 1), i);}} else {//如果没有孩子,要判断该节点关键字数量是否大于最小值if (node.informations.size() >= n) {//大于等于就没事,不用动return;} else {//叶子节点中关键字数小于n,需要继续判断兄弟节点是否饱满dManageNode(node);}}}}public String perOrder(BTNode node) {String result = "";if (node.ptr.size() > 0) {int i = 0;for (BTNode n : node.ptr) {result += perOrder(n);if (i < node.informations.size()) {result += node.informations.get(i).toString() + ",";++i;}}} else {//叶子节点if (node.informations.size() > 0) {for (T t : node.informations) {result += t.toString() + ",";}} else {//叶子节点没有空值的时候,除非是根节点,根节点为空值的时候,说句话意思意思result += "B-树为空!";}}return result;}public void split(BTNode node) {//进到这里的node都是m个关键字,需要提出m/2if (node == null) {System.out.println("error");} else {if (node.informations.size() != m) {System.out.println("error");} else {if (node.parent == null) {//node是root时T temp = node.informations.get(n);//这里正好root = new BTNode(temp, null);node.informations.remove(n);//加进去了就要删掉!root.ptr.add(node);node.parent = root;splitNewNode(node, n, root);} else {//一个非根节点T temp = node.informations.get(n);node.parent.informations.add(node.parent.ptr.indexOf(node), temp);node.informations.remove(n);splitNewNode(node, n, node.parent);if (node.parent.informations.size() >= m) {split(node.parent);}}}}}public void splitNewNode(BTNode node, int n, BTNode parent) {BTNode newnode = new BTNode(node.informations.get(n), node.parent);newnode.informations.addAll(node.informations.subList(n + 1, node.informations.size()));node.informations.removeAll(node.informations.subList(n, node.informations.size()));//newnode.parent=node.parent;//新增节点的父节点node.parent.ptr.add(node.parent.ptr.indexOf(node) + 1, newnode); //新增节点加到父节点上if (node.ptr.size() > 0) { //处理新增节点的孩子newnode.ptr.addAll(node.ptr.subList(n + 1, node.ptr.size()));node.ptr.removeAll(node.ptr.subList(n + 1, node.ptr.size()));for (BTNode bn : newnode.ptr) { //子节点移到了新节点上,但是子节点的父节点没有处理!!!T_Tbn.parent = newnode;}}}public void combine(BTNode lnode, BTNode rnode) {if (lnode.informations.size() < n) {lnode.informations.add(lnode.parent.informations.get(lnode.parent.ptr.indexOf(lnode)));lnode.parent.informations.remove(lnode.parent.ptr.indexOf(lnode));} else if (rnode.informations.size() < n) {rnode.informations.add(0, rnode.parent.informations.get(lnode.parent.ptr.indexOf(lnode)));rnode.parent.informations.remove(lnode.parent.ptr.indexOf(lnode));} else {System.out.println("error");}lnode.informations.addAll(rnode.informations);lnode.ptr.addAll(rnode.ptr);for (BTNode n : rnode.ptr) {n.parent = lnode;}lnode.parent.ptr.remove(lnode.parent.ptr.indexOf(lnode) + 1);if (lnode.parent.parent == null && lnode.parent.informations.size() == 0) {//父节点是根节点lnode.parent = null; //lnode为新的根节点root = lnode;return;}if (lnode.parent.informations.size() < n) {dManageNode(lnode.parent);}}public void lrotate(BTNode lnode, BTNode rnode) {lnode.informations.add(lnode.parent.informations.get(lnode.parent.ptr.indexOf(lnode)));lnode.parent.informations.remove(lnode.parent.ptr.indexOf(lnode));lnode.parent.informations.add(lnode.parent.ptr.indexOf(lnode), rnode.informations.get(0));rnode.informations.remove(0);if (rnode.ptr.size() > 0) {//要判断叶子节点没有孩子!lnode.ptr.add(rnode.ptr.get(0));rnode.ptr.remove(0);lnode.ptr.get(lnode.ptr.size() - 1).parent = lnode;}}public void rrotate(BTNode lnode, BTNode rnode) {rnode.informations.add(rnode.parent.informations.get(lnode.parent.ptr.indexOf(lnode)));rnode.parent.informations.remove(lnode.parent.ptr.indexOf(lnode));rnode.parent.informations.add(lnode.parent.ptr.indexOf(lnode), lnode.informations.get(lnode.informations.size() - 1));lnode.informations.remove(lnode.informations.size() - 1);if (lnode.ptr.size() > 0) {rnode.ptr.add(0, lnode.ptr.get(lnode.ptr.size() - 1));lnode.ptr.remove(lnode.ptr.size() - 1);rnode.ptr.get(0).parent = rnode;}}public void dManageNode(BTNode node) {//叶子节点中关键字数小于n,需要继续判断兄弟节点是否饱满,是旋转还是合并if (node.parent == null) {return;} else {int x = node.parent.ptr.indexOf(node);if (x == 0) {//被删除关键字所在节点,是父节点最左边的节点时,判断右兄弟,而且肯定有右兄弟if (node.parent.ptr.get(x + 1).informations.size() == n) {//刚脱贫,需要合并combine(node, node.parent.ptr.get(x + 1));} else if (node.parent.ptr.get(x + 1).informations.size() > n) {//关键字数大于最小值,丰满lrotate(node, node.parent.ptr.get(x + 1));} else {System.out.println("error");}} else if (x == node.parent.ptr.size() - 1) {//是父节点最右边的节点时,判断左兄弟if (node.parent.ptr.get(x - 1).informations.size() == n) {//左兄弟刚脱贫,需要合并combine(node.parent.ptr.get(x - 1), node);} else if (node.parent.ptr.get(x - 1).informations.size() > n) {//关键字数大于最小值,丰满rrotate(node.parent.ptr.get(x - 1), node);} else {System.out.println("error");}} else {//node在父节点的子节点的中间,需要先判断左兄弟,再判断右兄弟。靠,感觉判断兄弟是否饱满,还是应该写一个函数,也许可以传递两个值//先跟饱满的借,除非两个兄弟都刚脱贫。if (node.parent.ptr.get(x - 1).informations.size() > n) {//左兄弟丰满rrotate(node.parent.ptr.get(x - 1), node);} else if (node.parent.ptr.get(x + 1).informations.size() > n) {//右兄弟丰满lrotate(node, node.parent.ptr.get(x + 1));} else {//左右兄弟都刚脱贫,需要合并combine(node.parent.ptr.get(x - 1), node);}}}}public void pullRLeftNode(BTNode donode, int j, BTNode node, int i) {//节点删除关键字后,如果该节点有孩子,则孩子需要贡献关键字,由于孩子减少了关键字还需要向下借,一直递归到叶子。if (node.ptr.get(0).ptr.size() > 0) {pullRLeftNode(donode, j, node.ptr.get(0), 0);} else {donode.informations.add(j, node.ptr.get(0).informations.get(0));node.ptr.get(0).informations.remove(0);if (node.ptr.get(0).informations.size() < n) {dManageNode(node.ptr.get(0));}}}class BTNode {BTNode parent; //父节点List<T> informations = new ArrayList<>(); //关键字的信息List<BTNode> ptr = new ArrayList<BTNode>(); //分支public BTNode(T information, BTNode parent) {if (information != null) {informations.add(information);this.parent = parent;} else {this.parent = null;}}boolean isLeaf() {return (ptr.size() == 0);}boolean isNode() {return (ptr.size() != 0);}int infoLength() {return informations.size();}int ptrLength() {return ptr.size();}}}
8.3 总结分析
磁盘IO文件系统的设计者利用了磁盘预读原理,将一个结点的大小设为等于一个页(1024个字节或其整数倍),这样每个结点只需要一次I/O就可以完全载入。那么3层的B树可以容纳102410241024差不多10亿个数据,如果换成二叉查找树,则需要30层!假定操作系统一次读取一个节点,并且根节点保留在内存中,那么B树在10亿个数据中查找目标值,只需要小于3次硬盘读取就可以找到目标值,但红黑树需要小于30次,因此B树大大提高了IO的操作效率。
九 B+树
B+树是对B树的一种变形树,它与B树的差异在于:
1. 非叶结点仅具有索引作用,也就是说,非叶子结点只存储key,不存储value;
2. 树的所有叶结点构成一个有序链表,可以按照key排序的次序遍历全部数据。
9.1 实现原理
若参数M选择为5,那么每个结点最多包含4个键值对,我们以5阶B+树为例,看看B+树的数据存储。
B+树的优点在于:
1.由于B+树在非叶子结点上不包含真正的数据,只当做索引使用,因此在内存相同的情况下,能够存放更多的key。 2.B+树的叶子结点都是相连的,因此对整棵树的遍历只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。
B树的优点在于:
由于B树的每一个节点都包含key和value,因此我们根据key查找value时,只需要找到key所在的位置,就能找到value,但B+树只有叶子结点存储数据,索引每一次查找,都必须一次一次,一直找到树的最大深度处,也就是叶子结点的深度,才能找到value。
9.2 代码实现
代码比较复杂,了解即可。
package com.ycc.data.structure.tree;/*** 实现B+树** @author liaozx* @description* @create 2020-11-27 15:53* * @param <T> 指定值类型* * @param <V> 使用泛型,指定索引类型,并且指定必须继承Comparable*/public class BPlusTree<T, V extends Comparable<V>> {//B+树的阶private final Integer bTreeOrder;//B+树的非叶子节点最小拥有的子节点数量(同时也是键的最小数量)//private Integer minNUmber;//B+树的非叶子节点最大拥有的节点数量(同时也是键的最大数量)private final Integer maxNumber;private Node<T, V> root;private LeafNode<T, V> left;//无参构造方法,默认阶为3public BPlusTree() {this(3);}//有参构造方法,可以设定B+树的阶public BPlusTree(Integer bTreeOrder) {this.bTreeOrder = bTreeOrder;//this.minNUmber = (int) Math.ceil(1.0 * bTreeOrder / 2.0);//因为插入节点过程中可能出现超过上限的情况,所以这里要加1this.maxNumber = bTreeOrder + 1;this.root = new LeafNode<T, V>();this.left = null;}//查询public T find(V key) {T t = this.root.find(key);if (t == null) {System.out.println("不存在");}return t;}//插入public void insert(T value, V key) {if (key == null)return;Node<T, V> t = this.root.insert(value, key);if (t != null)this.root = t;this.left = this.root.refreshLeft();// System.out.println("插入完成,当前根节点为:");// for(int j = 0; j < this.root.number; j++) {// System.out.print((V) this.root.keys[j] + " ");// }// System.out.println();}/*** 节点父类,因为在B+树中,非叶子节点不用存储具体的数据,只需要把索引作为键就可以了* 所以叶子节点和非叶子节点的类不太一样,但是又会公用一些方法,所以用Node类作为父类,* 而且因为要互相调用一些公有方法,所以使用抽象类** @param <T> 同BPlusTree* @param <V>*/abstract class Node<T, V extends Comparable<V>> {//父节点protected Node<T, V> parent;//子节点protected Node<T, V>[] childs;//键(子节点)数量protected Integer number;//键protected Object[] keys;//构造方法public Node() {this.keys = new Object[maxNumber];this.childs = new Node[maxNumber];this.number = 0;this.parent = null;}//查找abstract T find(V key);//插入abstract Node<T, V> insert(T value, V key);abstract LeafNode<T, V> refreshLeft();}/*** 非叶节点类** @param <T>* @param <V>*/class BPlusNode<T, V extends Comparable<V>> extends Node<T, V> {public BPlusNode() {super();}/*** 递归查找,这里只是为了确定值究竟在哪一块,真正的查找到叶子节点才会查** @param key* @return*/@OverrideT find(V key) {int i = 0;while (i < this.number) {if (key.compareTo((V) this.keys[i]) <= 0)break;i++;}if (this.number == i)return null;return this.childs[i].find(key);}/*** 递归插入,先把值插入到对应的叶子节点,最终讲调用叶子节点的插入类** @param value* @param key*/@OverrideNode<T, V> insert(T value, V key) {int i = 0;while (i < this.number) {if (key.compareTo((V) this.keys[i]) < 0)break;i++;}if (key.compareTo((V) this.keys[this.number - 1]) >= 0) {i--;// if(this.childs[i].number + 1 <= bTreeOrder) {// this.keys[this.number - 1] = key;// }}// System.out.println("非叶子节点查找key: " + this.keys[i]);return this.childs[i].insert(value, key);}@OverrideLeafNode<T, V> refreshLeft() {return this.childs[0].refreshLeft();}/*** 当叶子节点插入成功完成分解时,递归地向父节点插入新的节点以保持平衡** @param node1* @param node2* @param key*/Node<T, V> insertNode(Node<T, V> node1, Node<T, V> node2, V key) {// System.out.println("非叶子节点,插入key: " + node1.keys[node1.number - 1] + " " + node2.keys[node2.number - 1]);V oldKey = null;if (this.number > 0)oldKey = (V) this.keys[this.number - 1];//如果原有key为null,说明这个非节点是空的,直接放入两个节点即可if (key == null || this.number <= 0) {// System.out.println("非叶子节点,插入key: " + node1.keys[node1.number - 1] + " " + node2.keys[node2.number - 1] + "直接插入");this.keys[0] = node1.keys[node1.number - 1];this.keys[1] = node2.keys[node2.number - 1];this.childs[0] = node1;this.childs[1] = node2;this.number += 2;return this;}//原有节点不为空,则应该先寻找原有节点的位置,然后将新的节点插入到原有节点中int i = 0;while (key.compareTo((V) this.keys[i]) != 0) {i++;}//左边节点的最大值可以直接插入,右边的要挪一挪再进行插入this.keys[i] = node1.keys[node1.number - 1];this.childs[i] = node1;Object[] tempKeys = new Object[maxNumber];Object[] tempChilds = new Node[maxNumber];System.arraycopy(this.keys, 0, tempKeys, 0, i + 1);System.arraycopy(this.childs, 0, tempChilds, 0, i + 1);System.arraycopy(this.keys, i + 1, tempKeys, 0, this.number - i - 1);System.arraycopy(this.childs, i + 1, tempChilds, 0, this.number - i - 1);tempKeys[i + 1] = node2.keys[node2.number - 1];tempChilds[i + 1] = node2;this.number++;//判断是否需要拆分//如果不需要拆分,把数组复制回去,直接返回if (this.number <= bTreeOrder) {System.arraycopy(tempKeys, 0, this.keys, 0, this.number);System.arraycopy(tempChilds, 0, this.childs, 0, this.number);// System.out.println("非叶子节点,插入key: " + node1.keys[node1.number - 1] + " " + node2.keys[node2.number - 1] + ", 不需要拆分");return null;}// System.out.println("非叶子节点,插入key: " + node1.keys[node1.number - 1] + " " + node2.keys[node2.number - 1] + ",需要拆分");//如果需要拆分,和拆叶子节点时类似,从中间拆开Integer middle = this.number / 2;//新建非叶子节点,作为拆分的右半部分BPlusNode<T, V> tempNode = new BPlusNode<T, V>();//非叶节点拆分后应该将其子节点的父节点指针更新为正确的指针tempNode.number = this.number - middle;tempNode.parent = this.parent;//如果父节点为空,则新建一个非叶子节点作为父节点,并且让拆分成功的两个非叶子节点的指针指向父节点if (this.parent == null) {// System.out.println("非叶子节点,插入key: " + node1.keys[node1.number - 1] + " " + node2.keys[node2.number - 1] + ",新建父节点");BPlusNode<T, V> tempBPlusNode = new BPlusNode<>();tempNode.parent = tempBPlusNode;this.parent = tempBPlusNode;oldKey = null;}System.arraycopy(tempKeys, middle, tempNode.keys, 0, tempNode.number);System.arraycopy(tempChilds, middle, tempNode.childs, 0, tempNode.number);for (int j = 0; j < tempNode.number; j++) {tempNode.childs[j].parent = tempNode;}//让原有非叶子节点作为左边节点this.number = middle;this.keys = new Object[maxNumber];this.childs = new Node[maxNumber];System.arraycopy(tempKeys, 0, this.keys, 0, middle);System.arraycopy(tempChilds, 0, this.childs, 0, middle);//叶子节点拆分成功后,需要把新生成的节点插入父节点BPlusNode<T, V> parentNode = (BPlusNode<T, V>) this.parent;return parentNode.insertNode(this, tempNode, oldKey);}}/*** 叶节点类** @param <T>* @param <V>*/class LeafNode<T, V extends Comparable<V>> extends Node<T, V> {protected Object[] values;protected LeafNode left;protected LeafNode right;public LeafNode() {super();this.values = new Object[maxNumber];this.left = null;this.right = null;}/*** 进行查找,经典二分查找,不多加注释** @param key* @return*/@OverrideT find(V key) {if (this.number <= 0)return null;// System.out.println("叶子节点查找");Integer left = 0;Integer right = this.number;Integer middle = (left + right) / 2;while (left < right) {V middleKey = (V) this.keys[middle];if (key.compareTo(middleKey) == 0)return (T) this.values[middle];else if (key.compareTo(middleKey) < 0)right = middle;elseleft = middle;middle = (left + right) / 2;}return null;}/*** @param value* @param key*/@OverrideNode<T, V> insert(T value, V key) {// System.out.println("叶子节点,插入key: " + key);//保存原始存在父节点的key值V oldKey = null;if (this.number > 0)oldKey = (V) this.keys[this.number - 1];//先插入数据int i = 0;while (i < this.number) {if (key.compareTo((V) this.keys[i]) < 0)break;i++;}//复制数组,完成添加Object[] tempKeys = new Object[maxNumber];Object[] tempValues = new Object[maxNumber];System.arraycopy(this.keys, 0, tempKeys, 0, i);System.arraycopy(this.values, 0, tempValues, 0, i);System.arraycopy(this.keys, i, tempKeys, i + 1, this.number - i);System.arraycopy(this.values, i, tempValues, i + 1, this.number - i);tempKeys[i] = key;tempValues[i] = value;this.number++;// System.out.println("插入完成,当前节点key为:");// for(int j = 0; j < this.number; j++)// System.out.print(tempKeys[j] + " ");// System.out.println();//判断是否需要拆分//如果不需要拆分完成复制后直接返回if (this.number <= bTreeOrder) {System.arraycopy(tempKeys, 0, this.keys, 0, this.number);System.arraycopy(tempValues, 0, this.values, 0, this.number);//有可能虽然没有节点分裂,但是实际上插入的值大于了原来的最大值,所以所有父节点的边界值都要进行更新Node node = this;while (node.parent != null) {V tempkey = (V) node.keys[node.number - 1];if (tempkey.compareTo((V) node.parent.keys[node.parent.number - 1]) > 0) {node.parent.keys[node.parent.number - 1] = tempkey;node = node.parent;}}// System.out.println("叶子节点,插入key: " + key + ",不需要拆分");return null;}// System.out.println("叶子节点,插入key: " + key + ",需要拆分");//如果需要拆分,则从中间把节点拆分差不多的两部分Integer middle = this.number / 2;//新建叶子节点,作为拆分的右半部分LeafNode<T, V> tempNode = new LeafNode<T, V>();tempNode.number = this.number - middle;tempNode.parent = this.parent;//如果父节点为空,则新建一个非叶子节点作为父节点,并且让拆分成功的两个叶子节点的指针指向父节点if (this.parent == null) {// System.out.println("叶子节点,插入key: " + key + ",父节点为空 新建父节点");BPlusNode<T, V> tempBPlusNode = new BPlusNode<>();tempNode.parent = tempBPlusNode;this.parent = tempBPlusNode;oldKey = null;}System.arraycopy(tempKeys, middle, tempNode.keys, 0, tempNode.number);System.arraycopy(tempValues, middle, tempNode.values, 0, tempNode.number);//让原有叶子节点作为拆分的左半部分this.number = middle;this.keys = new Object[maxNumber];this.values = new Object[maxNumber];System.arraycopy(tempKeys, 0, this.keys, 0, middle);System.arraycopy(tempValues, 0, this.values, 0, middle);this.right = tempNode;tempNode.left = this;//叶子节点拆分成功后,需要把新生成的节点插入父节点BPlusNode<T, V> parentNode = (BPlusNode<T, V>) this.parent;return parentNode.insertNode(this, tempNode, oldKey);}@OverrideLeafNode<T, V> refreshLeft() {if (this.number <= 0)return null;return this;}}}
9.3 总结分析
在数据库的操作中,查询操作可以说是最频繁的一种操作,因此在设计数据库时,必须要考虑到查询的效率问题,在很多数据库中,都是用到了B+树来提高查询的效率。
9.3.1 未建立索引

执行select * from user where id=18 ,需要从第一条数据开始,一直查询到第6条,发现id=18,此时才能查询出
目标结果,共需要比较6次;
9.3.2 建立主键索引查询

执行select * from user where id>=12 and id<=18 ,如果有了索引,由于B+树的叶子结点形成了一个有序链表,所以我们只需要找到id为12的叶子结点,按照遍历链表的方式顺序往后查即可,效率非常高。
十 并差集
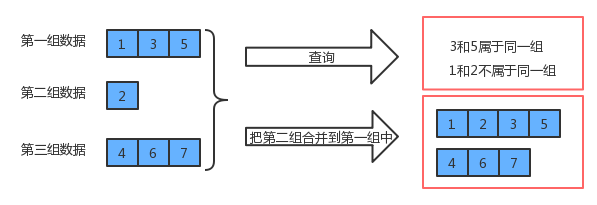
并查集是一种数据结构,形象地来说,有点像“朋友圈”:A和B是朋友,A和B就构成了一个朋友圈,C和D是朋友,C和D也构成了一个朋友圈,那么这时,如果B和C在成为了朋友,A、B、C、D就构成了一个大的朋友圈。并查集就是可以描述这种情形的数据结构。
并查集是一种树型的数据结构 ,并查集可以高效地进行如下操作:
查询元素p和元素q是否属于同一组
合并元素p和元素q所在的组
10.1 简单并查集
并查集也是一种树型结构,但这棵树跟我们之前讲的二叉树、红黑树、B树等都不一样,这种树的要求比较简单:
1. 每个元素都唯一的对应一个结点;
2. 每一组数据中的多个元素都在同一颗树中;
3. 一个组中的数据对应的树和另外一个组中的数据对应的树之间没有任何联系;
4. 元素在树中并没有子父级关系的硬性要求;
10.1.1 实现原理
如果p和q已经在同一个分组中,则无需合并
2. 如果p和q不在同一个分组,则只需要将p元素所在组的所有的元素的组标识符修改为q元素所在组的标识符即可
3. 分组数量-1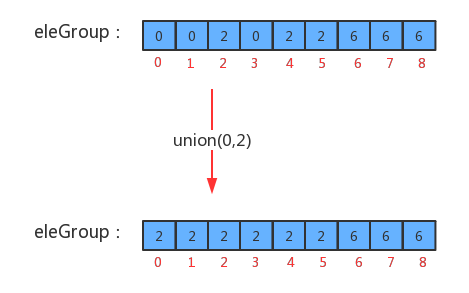
10.1.2 代码实现
```java package cn.itcast.algorithm.uf; /**
- @author liaozx
@date 2020-11-27 */ public class UF { //记录结点元素和该元素所在分组的标识 private int[] eleAndGroup; //记录并查集中数据的分组个数、即朋友圈的的数量 private int count;
//初始化并查集 public UF(int current) { //初始化分组的数量,默认情况下,有N个分组 this.count = current; //初始化eleAndGroup数组 this.eleAndGroup = new int[current]; //初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个结点的元素,并且让每个索引处的值(该元素所在的组的标识符)就是该索引 for (int i = 0; i < eleAndGroup.length; i++) {
//表示每一个元素对应的一个组,每个人的圈子只有自己一个人eleAndGroup[i] = i;
} }
//获取当前并查集中的数据有多少个分组 public int count() { return count; }
//元素p所在分组的标识符 private int find(int p) { return eleAndGroup[p]; }
//判断并查集中元素p和元素q是否在同一分组中 public boolean connected(int p, int q) { return find(p) == find(q); }
//把p元素所在分组和q元素所在分组合并 public void union(int p, int q) { //判断元素q和p是否已经在同一分组中,如果已经在同一分组中,则结束方法就可以了 if (connected(p, q)) {
return;
} //找到p所在分组的标识符 int pGroup = find(p); //找到q所在分组的标识符 int qGroup = find(q);
//合并组:让p所在组的所有元素的组标识符变为q所在分组的标识符 for (int i = 0; i < eleAndGroup.length; i++) {
if (eleAndGroup[i] == pGroup) {eleAndGroup[i] = qGroup;}
} //分组个数-1 //朋友圈的数量减少1 this.count—;
}
}
缺点:**Union合并朋友圈的操作复杂度为O(n),实在是太慢了**<a name="BZSop"></a>## 10.2 树结构并查集为了提升union算法的性能,我们需要重新设计find方法和union方法的实现,此时我们先需要对我们的之前数据结<br />构中的eleAndGourp数组的含义进行重新设定:<br />1.我们仍然让eleAndGroup数组的索引作为某个结点的元素;<br />2.eleAndGroup[i]的值不再是当前结点所在的分组标识,而是该结点的父结点;<br />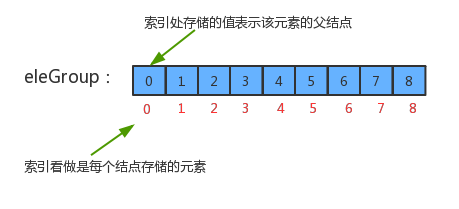<a name="h5VVI"></a>### 10.2.1 实现原理1. 找到p元素所在树的根结点<br />2. 找到q元素所在树的根结点<br />3. 如果p和q已经在同一个树中,则无需合并;<br />4. 如果p和q不在同一个分组,则只需要将p元素所在树根结点的父结点设置为q元素的根结点即可;<br />5. 分组数量-1<br />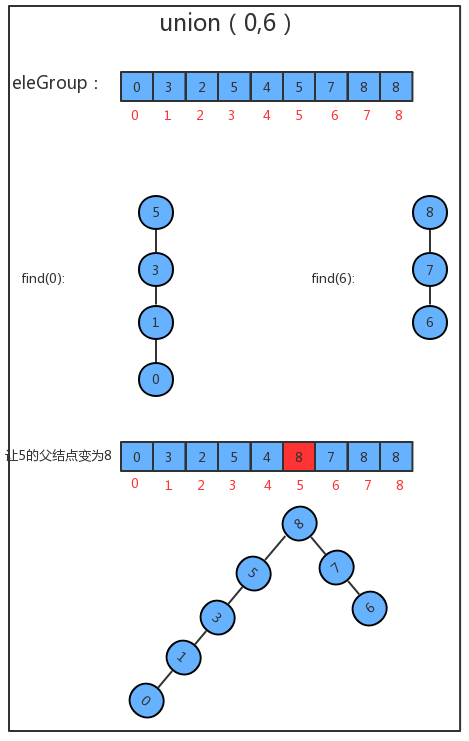<a name="05Znb"></a>### 10.2.2 代码实现```javapackage com.ycc.data.structure.uf;/*** @author liaozx* @date 2020-11-27*/public class UFTree {//记录结点元素和该元素所在分组的标识private final int[] eleAndGroup;//记录并查集中数据的分组个数private int count;//初始化并查集public UFTree(int N) {//初始化分组的数量,默认情况下,有N个分组this.count = N;//初始化eleAndGroup数组this.eleAndGroup = new int[N];//初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个结点的元素,并且让每个索引处的值(该元素所在的组的标识符)就是该索引for (int i = 0; i < eleAndGroup.length; i++) {eleAndGroup[i] = i;}}//获取当前并查集中的数据有多少个分组public int count() {return count;}//判断并查集中元素p和元素q是否在同一分组中public boolean connected(int p, int q) {return find(p) == find(q);}//元素p所在分组的标识符public int find(int p) {while (true) {if (p == eleAndGroup[p]) {return p;}p = eleAndGroup[p];}}//把p元素所在分组和q元素所在分组合并public void union(int p, int q) {//找到p元素和q元素所在组对应的树的根结点int pRoot = find(p);int qRoot = find(q);//如果p和q已经在同一分组,则不需要合并了if (pRoot == qRoot) {return;}//让p所在的树的根结点的父结点为q所在树的根结点即可eleAndGroup[pRoot] = qRoot;//组的数量-1this.count--;}}
10.3 路径压缩
我们优化后的算法union,如果要把并查集中所有的数据连通,仍然至少要调用N-1次union方法,但是,我们发现union方法中已经没有了for循环,所以union算法的时间复杂度由O(N^2)变为了O(N)。但是这个算法仍然有问题,因为我们之前不仅修改了union算法,还修改了find算法。我们修改前的find算法的时间复杂度在任何情况下都为O(1),但修改后的find算法在最坏情况下是O(N):
10.3.1 实现原理
UF_Tree中最坏情况下union算法的时间复杂度为O(N^2),其最主要的问题在于最坏情况下,树的深度和数组的大小一样,如果我们能够通过一些算法让合并时,生成的树的深度尽可能的小,就可以优化find方法。之前我们在union算法中,合并树的时候将任意的一棵树连接到了另外一棵树,这种合并方法是比较暴力的,如果我们把并查集中每一棵树的大小记录下来,然后在每次合并树的时候,把较小的树连接到较大的树上,就可以减小树的深度。
10.3.2 代码实现
package com.ycc.data.structure.uf;public class UFTreeWeighted {//记录结点元素和该元素所在分组的标识private final int[] eleAndGroup;//记录并查集中数据的分组个数private int count;//用来存储每一个根结点对应的树中保存的结点的个数private final int[] sz;//初始化并查集public UFTreeWeighted(int N) {//初始化分组的数量,默认情况下,有N个分组this.count = N;//初始化eleAndGroup数组this.eleAndGroup = new int[N];//初始化eleAndGroup中的元素及其所在的组的标识符,让eleAndGroup数组的索引作为并查集的每个结点的元素,并且让每个索引处的值(该元素所在的组的标识符)就是该索引for (int i = 0; i < eleAndGroup.length; i++) {eleAndGroup[i] = i;}this.sz = new int[N];//默认情况下,sz中每个索引处的值都是1for (int i = 0; i < sz.length; i++) {sz[i] = 1;}}//获取当前并查集中的数据有多少个分组public int count() {return count;}//判断并查集中元素p和元素q是否在同一分组中public boolean connected(int p, int q) {return find(p) == find(q);}//元素p所在分组的标识符public int find(int p) {while (true) {if (p == eleAndGroup[p]) {return p;}p = eleAndGroup[p];}}//把p元素所在分组和q元素所在分组合并public void union(int p, int q) {//找到p元素和q元素所在组对应的树的根结点int pRoot = find(p);int qRoot = find(q);//如果p和q已经在同一分组,则不需要合并了if (pRoot == qRoot) {return;}//判断proot对应的树大还是qroot对应的树大,最终需要把较小的树合并到较大的树中if (sz[pRoot] < sz[qRoot]) {eleAndGroup[pRoot] = qRoot;sz[qRoot] += sz[pRoot];} else {eleAndGroup[qRoot] = pRoot;sz[pRoot] += sz[qRoot];}//组的数量-1this.count--;}}

若有收获,就点个赞吧
0 人点赞
