本节课我们介绍一下迭代器模式,然后在二叉树里实现一下迭代器。
迭代器模式
在容器里存放了大量的同类型对象,我们如果想逐个访问容器中的对象,就必须要知道容器的结构。比如,ArrayList 和 LinkedList 的遍历方法一定是不一样的,如果再加上HashMap, TreeMap,以及我们现在正在研究的BinarySearchTree,对于容器的使用者而言,肯定是一个巨大的负担。作为容器的使用者,我肯定希望所有的容器能提供一个统一的接口,这个接口可以遍历容器中的所有内容,又可以把容器的细节屏蔽掉。
幸运的是,确实存在这样的一个统一的接口,这个接口就是 java.util.Iterator。先看类图,下面的这幅图所表示的意思就是,在一个容器类上实现createIterator方法,这个方法可以创建一个迭代器,使用这个迭代器就可以遍历容器中的所有元素了。
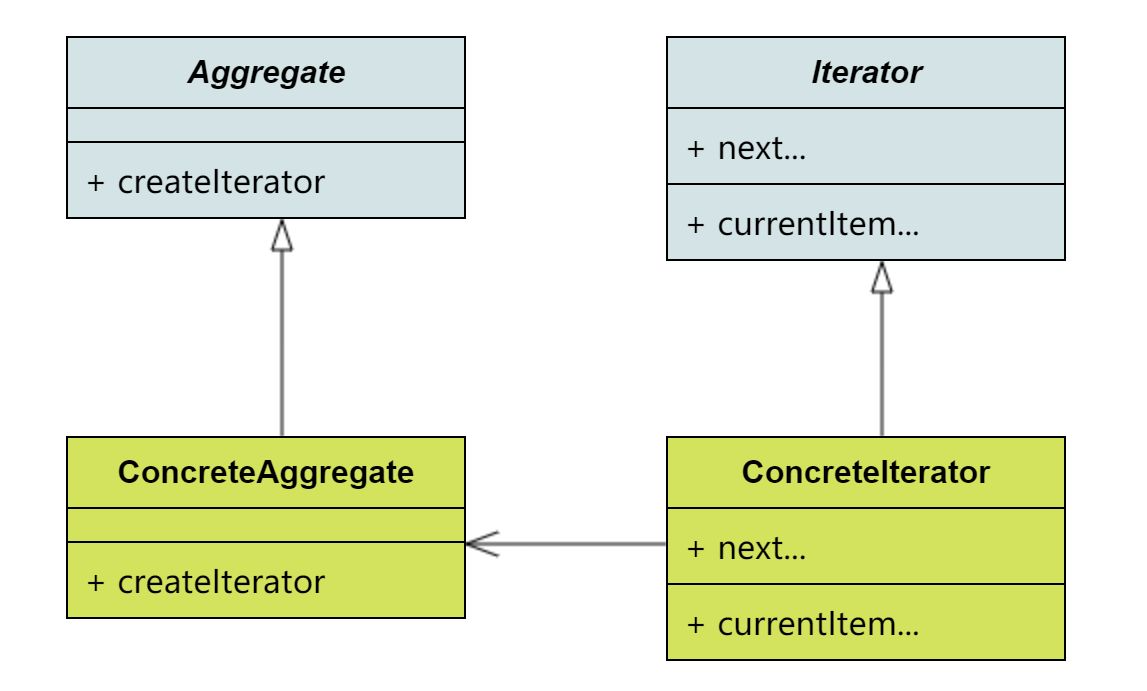
Iterator上定义了各种方法,用于遍历。图中只列出了一小部分。我们可以看一下JDK中是怎么定义的:
public interface Iterator<E> {boolean hasNext();E next();default void remove() {throw new UnsupportedOperationException("remove");}default void forEachRemaining(Consumer<? super E> action) {Objects.requireNonNull(action);while (hasNext())action.accept(next());}}
有两个default方法。default 这个关键字,我们以前没接触过。这是从1.8引入的,为了和以前的接口兼容,这个我们先不去管它,还有 forEachRemaing是一个高阶函数,它可以接受一个lambda表达式,这个我们会在后面的 Java 函数式编程中慢慢介绍,也先不去管它。所以 Iterator中也就只有两个方法,一个是hasNext,告诉使用者,还有没有下一个元素,如果为false,说明遍历已经完成了。还有一个是next,目的是取下一个元素。
我们先来体验一下。
List中的迭代器
我们先使用这个迭代器遍历一下List,例如:
public class Main {
public static void main(String args[]) {
LinkedList<Integer> ll = new LinkedList<>();
for (int i = 0; i < 10; i++)
ll.addLast(i);
Iterator<Integer> ii = ll.iterator();
while (ii.hasNext())
System.out.println(ii.next());
}
}
请大家再试一下ArrayList,体会一下 Iterator 的用法。可以看到,我们根本就不需要关心后面具体的数据结构,只需要使用 Iterator,不管后面是数组还是链表,都可以很方便地遍历整个容器。
大家想一下,如果要让自己来实现这样的一个Iterator,你会怎么写?这里给出ArrayList的源代码,可以参考一下:
public Iterator<E> iterator() {
return new Itr();
}
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
}
我把 remove 等方法删掉了,这个方法是在 ListIterator定义的,我们先不去管它。这里只留下了 hasNext 和 next 方法。
可以看到,ArrayList 的 Iterator 就是在数组中逐个前进,逻辑非常简单。
例子
总结
迭代器的作用就是为collection对象封装了一个类使其可以调用同一个接口,和同一个方法,进行对象的遍历,下面就是我写的一个关于二叉树的迭代器
构建二叉树
class BinaryTree{
Node root;
boolean[] book;
int index=0;
public BinaryTree(int[] array ) {
this.root = buildBinaryTree(array);
}
//先序遍历,dfs构建二叉树
public Node buildBinaryTree(int[] array){
if(index>=array.length||array[index]==-1){
return null;
}
Node node = new Node(array[index]);
index++;
node.left = buildBinaryTree(array);
index++;
node.right = buildBinaryTree(array);
return node;
}
/**
public Iterator<Node> createIterator(){
return new BinaryTreeIteator(this.root);
}
**/
}
构建迭代器
二叉树的迭代器与二叉树的遍历逻辑上差不多,倒是需要把递归遍历改成迭代的方法,只需要一个辅助数据就可以了。
class BinaryTreeIteator implements Iterator<Node>{
Node root;
//二叉树的先跟遍历的迭代器先跟遍历,需要个数组来记录读取节点的左右子树
ArrayList<Node> nodeArrayList;
public BinaryTreeIteator(Node root) {
this.root = root;
nodeArrayList = new ArrayList<>();
nodeArrayList.add(root);
}
@Override
public boolean hasNext() {
return !nodeArrayList.isEmpty();
}
@Override
public Node next() {
Node res = nodeArrayList.get(0);
if(res.left!=null){
nodeArrayList.set(0,res.left);
if(res.right!=null){
nodeArrayList.add(1,res.right);
}
}else{
if(res.right!=null){
nodeArrayList.set(0,res.right);
}else {
nodeArrayList.remove(0);
}
}
return res;
}
}
测试和使用
public static void main(String[] args) {
//先序遍历构建二叉树
Node root=null;
int[] array = {1,2,3,-1,-1,4,-1,-1,5,6,-1,-1,7,-1,-1};
BinaryTree binaryTree = new BinaryTree(array);
Iterator<Node> iterator = binaryTree.createIterator();
while (iterator.hasNext()){
Node node = iterator.next();
System.out.println(node.val);
}
}

若有收获,就点个赞吧
0 人点赞
