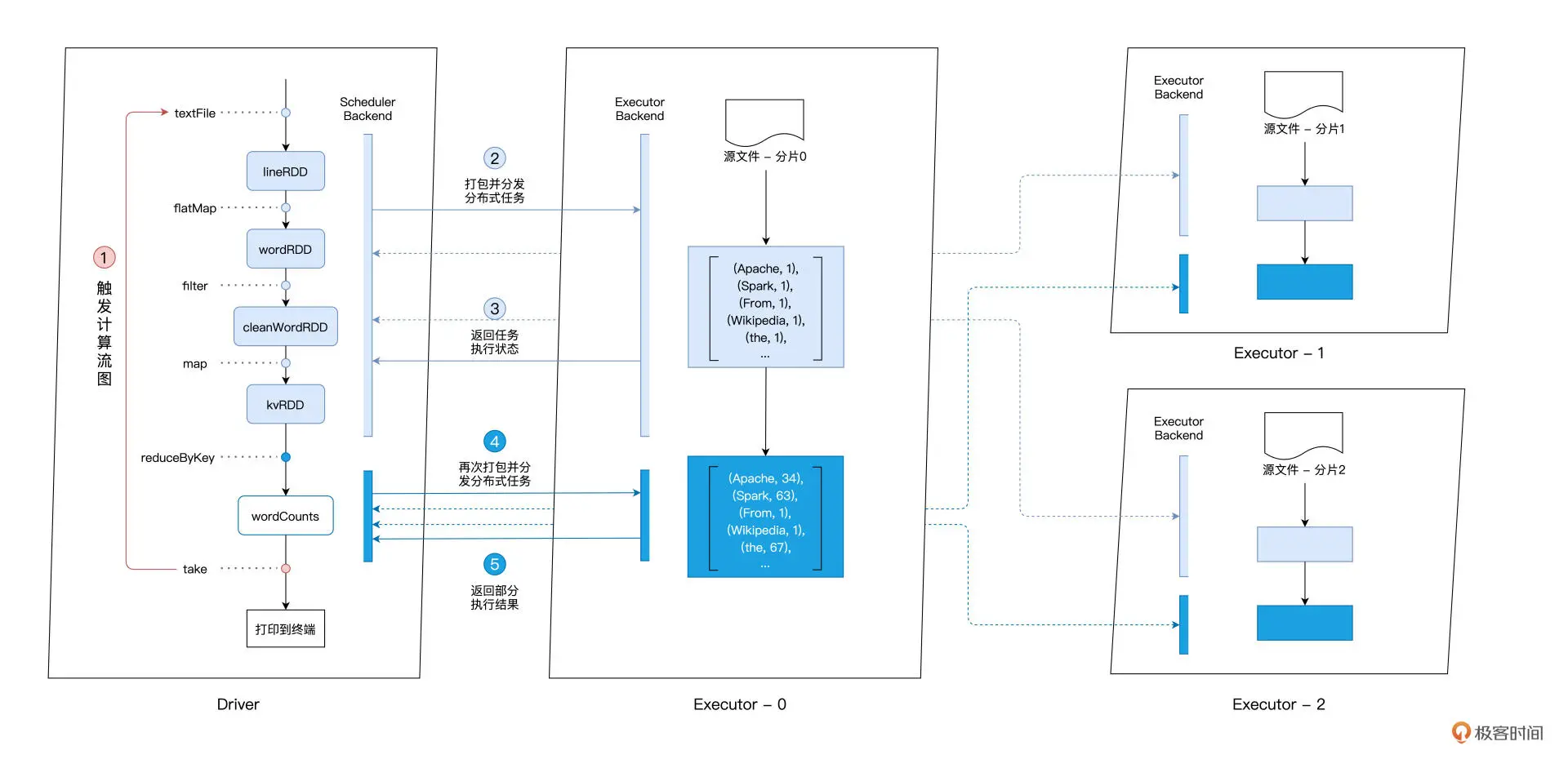
分布式计算的精髓,在于如何把抽象的计算流图,转化为实实在在的分布式计算任务,然后以并行计算的方式交付执行。
Shuffle
-
 08内存管理:Spark如何使用内存?
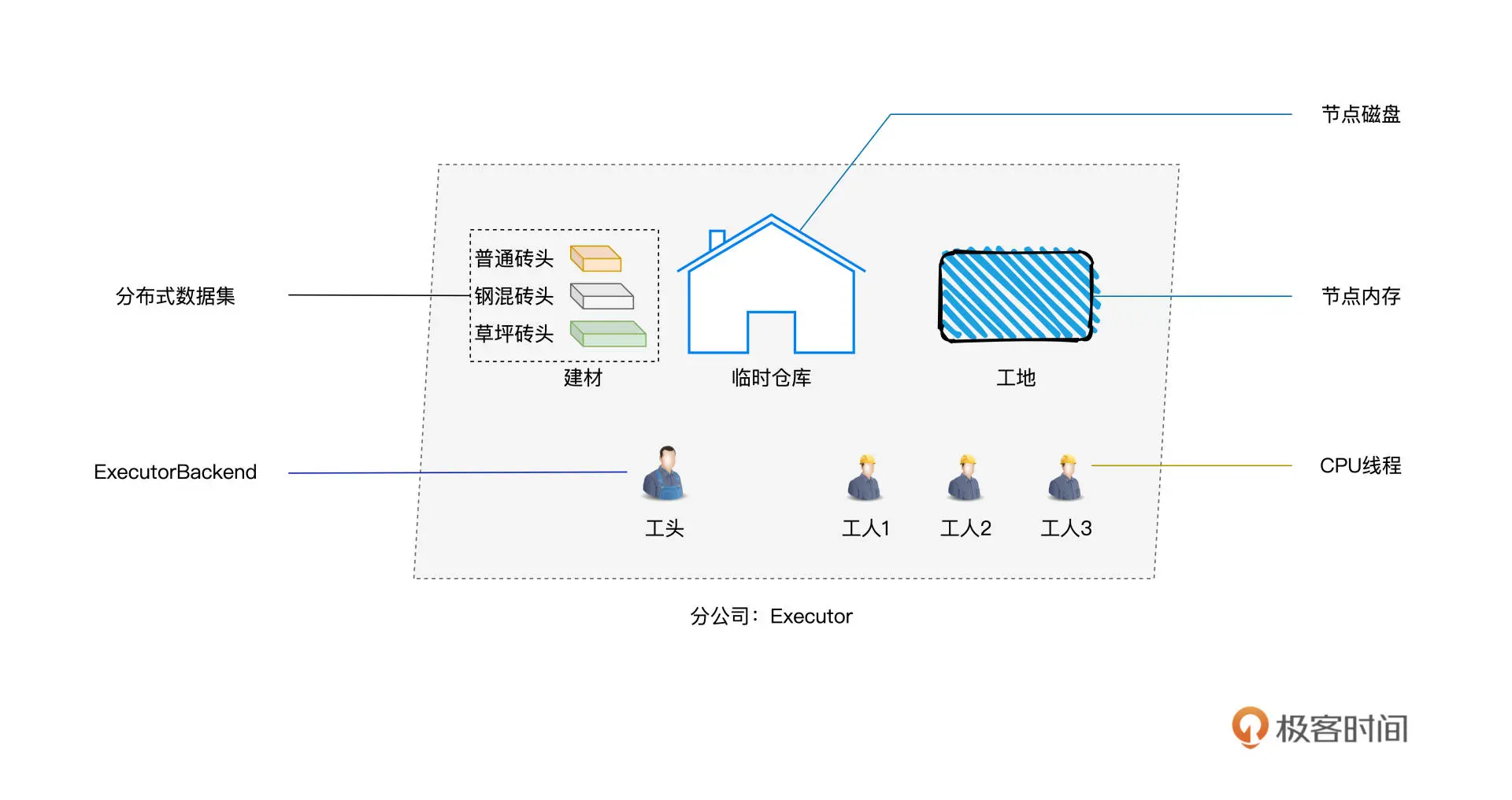
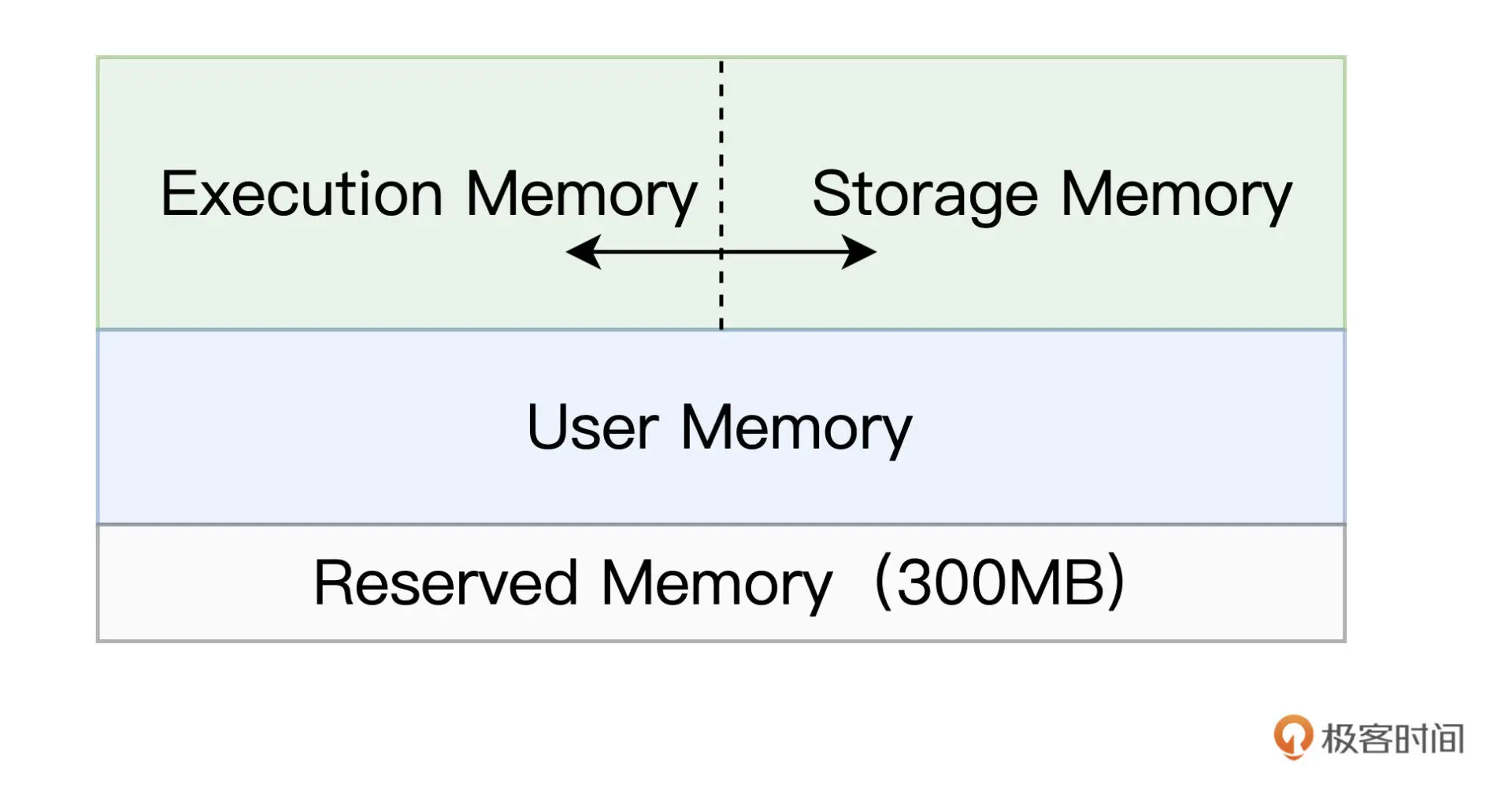
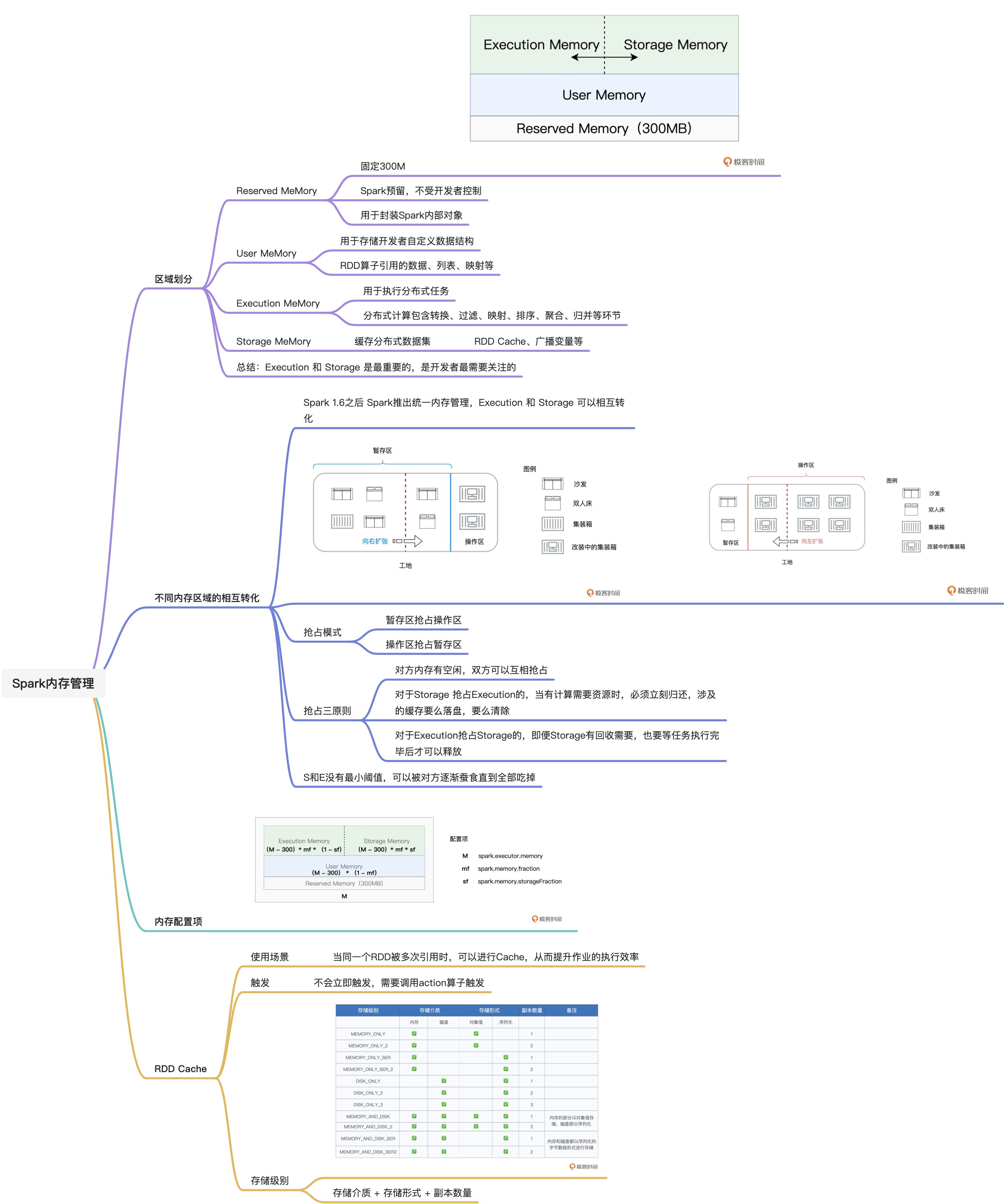
08内存管理:Spark如何使用内存?Spark 内存区域划分
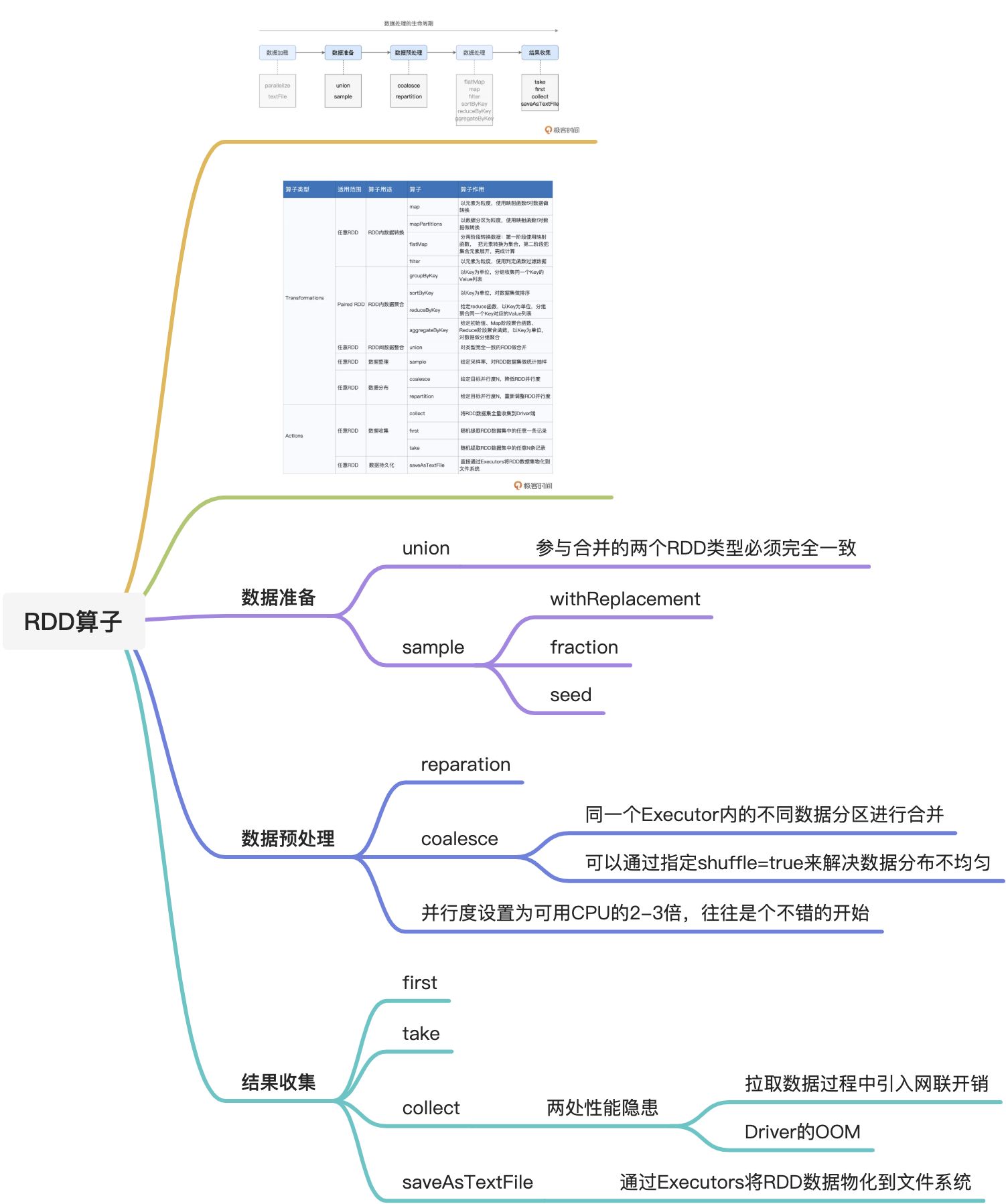
09 RDD常用算子3 数据的准备、重分布与持久化
10 广播变量 & 累加器
背景
Driver端变量分发是以Task为粒度的,系统中有多少个Task,变量就需要在网联中分发多少次
工业级应用中,RDD的并行度往往在千、万级别,所以诸如list变量需要在网联中分发成千上万次,作业的整体效率就会很差4
广播变量
广播变量之前,变量分发是以Task为粒度的,广播变量之后,是以Executors为粒度的
- 同一个Executor内Tasks只需要访问同一份数据拷贝即可
- 从RDD的分区数量锐减到了集群中的Executors个数
- 广播变量可以封装RDD、DataFrame分布式数据集
- 只能读不能改
累加器
- 全局计数
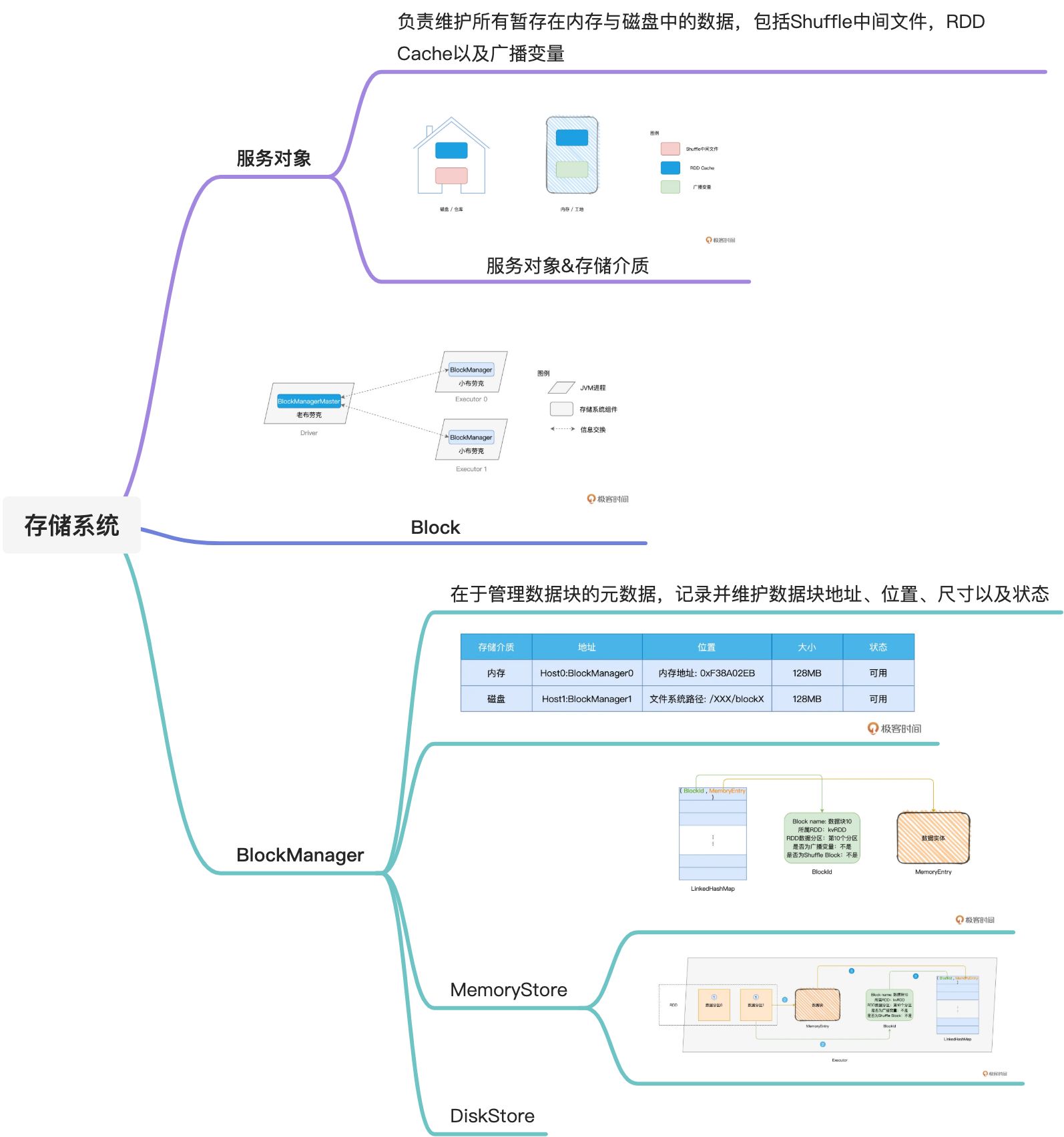
11 存储系统

若有收获,就点个赞吧
0 人点赞
