为什么使用Dataset
Dataset是PyTorch自定义的一种数据集格式,主要是为Dataloader服务,Dataloader是一种可以批量(batch)读取数据和数据label的迭代器,非常方便我们提取数据进行深度学习,要生成Dataloader迭代器,必须需要Dataset类型的数据。
PyTorch自带的可下载的数据集全部继承于Dataset,也就是可以直接在Dataloader中使用,如果我们想使用自己的数据集,且想使用Dataloader封装我们的数据集的话,我们就需要自定义一个继承Dataset类型的数据集。
自定义Dataset类型数据
基本框架
自定义
Dataset必须继承torch.utils.data.Dataset类,并且必须实现__getitem__和__len__两个函数。__getitem__接收传入的索引index,并且返回index所对应的数据(data)和标签(label)__len__返回数据集的长度class 类名(torch.utils.data.Dataset):def __getitem__(self, index):# 返回对应index的数据和标签return data,targetdef __len__(self):return lenth
实现案例
假设我们本地有一个训练集,有两个类别
ants和bees,层级如下图:
其中,ants文件夹内都是ants类别的图片,bees文件夹内都是bees类别的图片。
数据集链接: https://pan.baidu.com/s/1jZoTmoFzaTLWh4lKBHVbEA 密码: 5suq
现在我们想把这个训练集做成Dataset类型的数据,传入Dataloader进行训练,我们只需要想两个问题,如何根据索引取出相应的图片和标签?如何确定数据集的长度?其实就是如何实现__getitem__和__len__函数?
这个其实就是Python的问题。我对具体实现代码进行了详细的注释。
代码阅读顺序:直接阅读__init__即可。
# 首先我们要导入Dataset类进行继承,os类处理文件路径,Image类读取图片。from torch.utils.data import Datasetfrom PIL import Imageimport osclass MyData(Dataset):def __init__(self,path) -> None:# path是trian的文件路径,在我电脑就是'/Users/bruce/Downloads/数据集/hymenoptera_data/train/'self.path=path# os.listdir(path)以列表形式返回path下的文件名/文件夹名self.label_list = os.listdir(path)self.data_list = [] # 用来保存数据# 下面的循环就是,以(data,label)的形式,将数据存入data_listfor label in self.label_list:# 这个if语句用来过滤mac系统下的.DS_Store的隐藏文件,没有隐藏文件的可不加# os官网说listdir不显示隐藏文件,然而不知道为什么还是有if label.startswith('.'):continue# 下面代码可以直接写成列表推导式for data in os.listdir(path+label):# os.path.join(a,b,c)就是连接成一个路径/a/b/cdata = Image.open(os.path.join(path,label,data))self.data_list.append((data,label))def __getitem__(self,index):# 这里我们data_list保存着所有数据,且格式就是(data,label),直接返回即可return self.data_list[index]def __len__(self):return len(self.data_list)


问题
表面上看,我们的工作好像完成了,已经可以通过索引获取数据了,但是当我们把上面的train_dataset传入Dataloader后,使用Dataloader取数据时会报错,解决完一个错之后,又报另一个,具体报错信息不放出来了,有兴趣的可以自己试一下,总得来说一共三个报错的点:
- 传入的图片大小不一致。现实中的图片就是这样,几乎不会有所有图片大小都一致的情况
- 当我们处理完图片大小后,又报错:传入的图片通道不一致。
- 大部分图像都是三通道,里面夹杂着有一个单通道图像,所以报错
Dataloader要求传入的数据是tensor类型,而不是PIL.image的图片类型
下面是修改后的代码:
阅读建议:直接从__init__阅读即可,比较大的修改是利用了torchvision中的transforms,先把数据转换成统一大小,再转换成tensor向量
from torchvision import transformsfrom torch.utils.data import Datasetfrom PIL import Imageimport osclass MyData(Dataset):def __init__(self,path) -> None:self.path=pathself.label_list = os.listdir(path)self.data_list = []for label in self.label_list:if label.startswith('.'):continue# 下面代码可以直接写成列表推导式for data in os.listdir(os.path.join(path,label)):data = Image.open(os.path.join(path,label,data))# 这里我们只要3通道的图像if len(data.split())==3:self.data_list.append((self.transfrom(data),label))def __getitem__(self,index):return self.data_list[index]def __len__(self):return len(self.data_list)def transfrom(self,data):trans = transforms.Compose([transforms.Resize((300,300)),transforms.ToTensor(),])data = trans(data)'''如果不想实例化之后再调用,可以直接data = transforms.Compose([transforms.Resize((300,300)),transforms.ToTensor(),])(data)'''return data
Dataset的可加性
PyTorch允许两个Dataset的实例进行相加,从而实现数据集的整合。
假设下面path1和path2是两个不同的路径,都是我们的训练集,我们就可以直接把两个训练集加起来: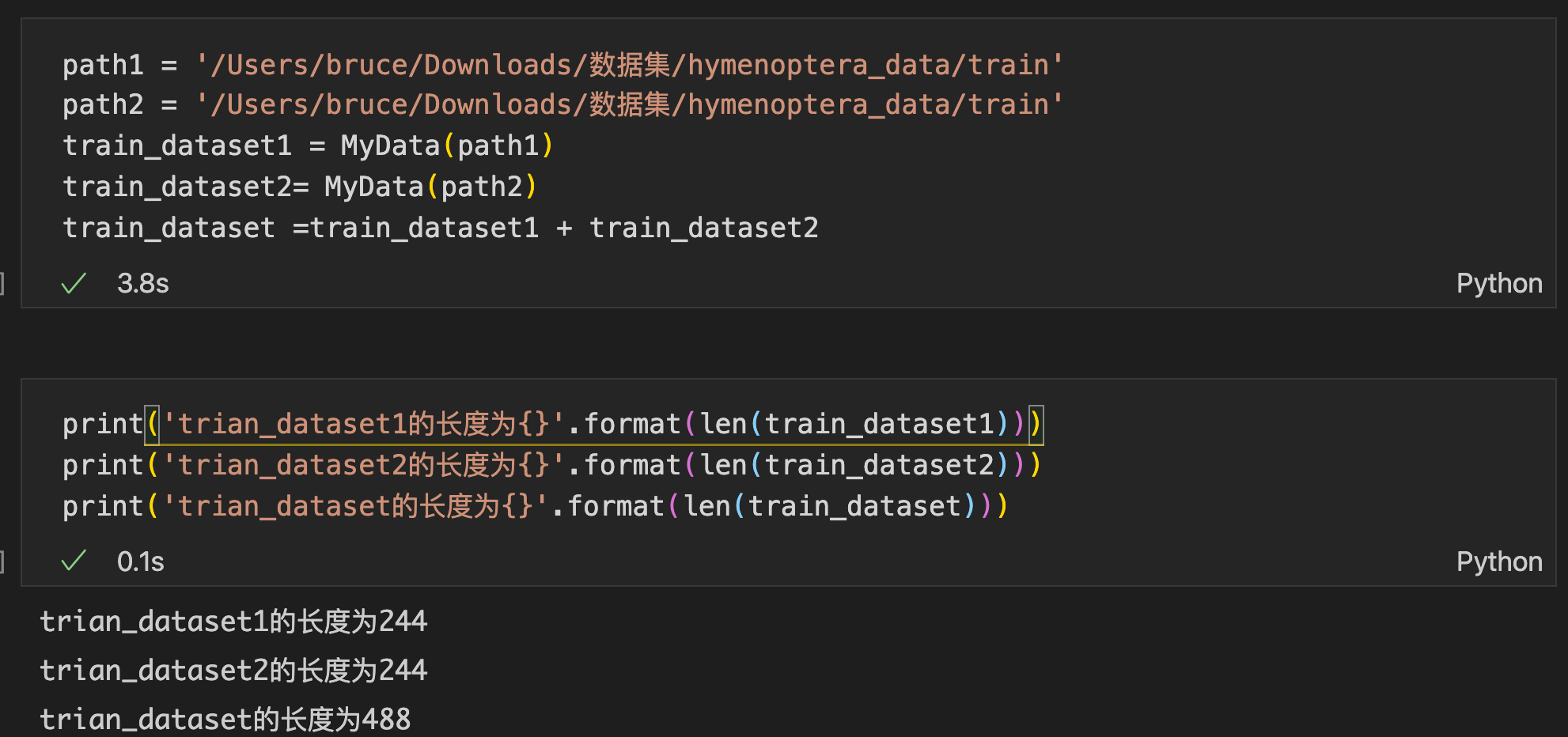
ImageFolder
其实对于上面这种形式的数据集,PyTorch有一个专门的类ImageFolder来处理,非常的方便。
详见ImageFolder

若有收获,就点个赞吧
0 人点赞
