首先放上源码,这里爬取的是域名有”.edu.cn”且是”中国”的站点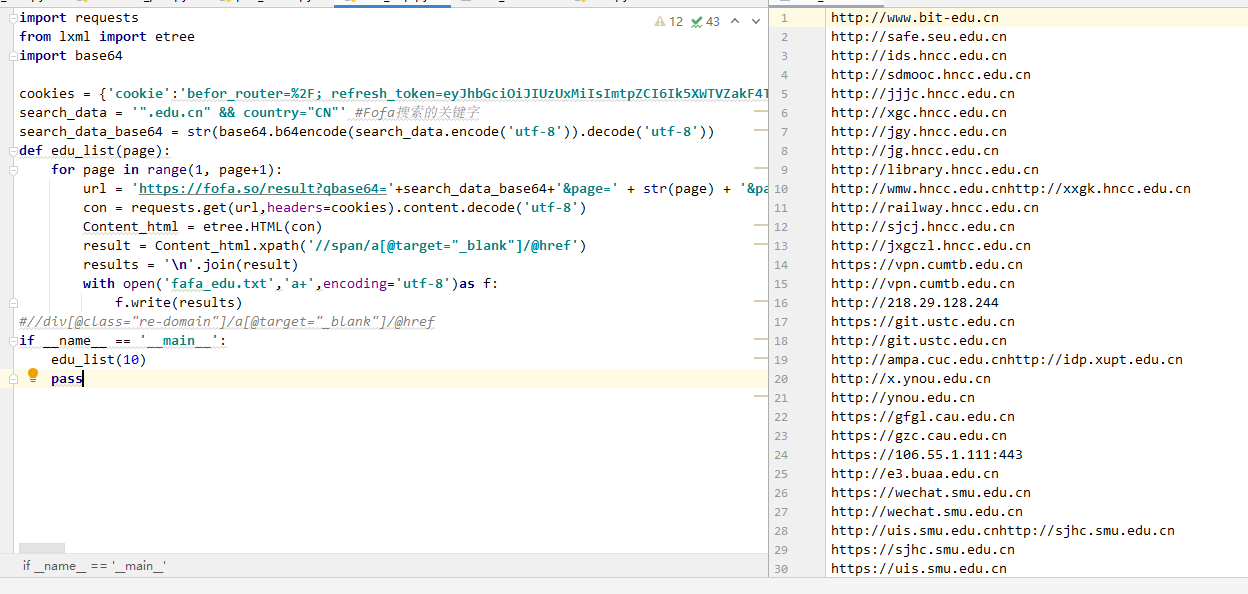
我给它划分了三个步骤:
1.构建url和导入cookie
2.将文本转换为html格式
3.使用lxml库函数筛选需要的内容
4.写入文档
1.1 第一步:构建url和导入cookie
我们搜索的url会被base64加密后用get发送请求给服务器
这里我写了一个测试文件,这样就一目了然了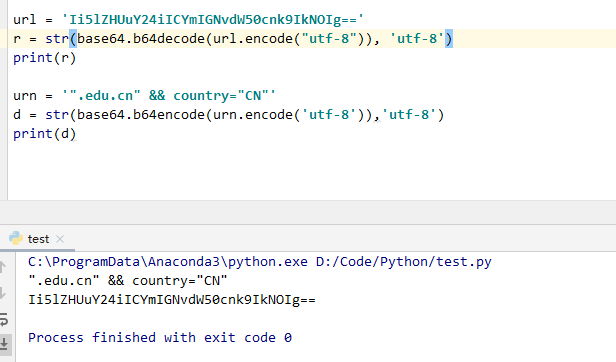
page是页数,之后我们就可以直接构建url了,并且用for循环爬取其他页面。
1.2 因为fofa需要登陆才能访问第二页,这里就需要用到requests库函数导入cookie
我们这里建立一个字典,里面用get请求的时候加入它就行
具体如下:
cookies = {‘cookie’:‘befor_router=%2F; refresh_token=eyJhbGciOiJ……………}
con = requests.get(url,headers=cookies).content.decode(‘utf-8’)
2.第二步:由于爬下来的页面不是html格式,现在我们需要用etree将它转为html
很简单,调用etree.HTML(要转换的内容)
例:Content_html = etree.HTML(con),讲con转换为html,并将它传给Content_html
3.第三步:筛选,这里需要用到xpath的语法,网上可以搜到,我这里就不赘述
Content_html.xpath(‘//span/a[@target=”_blank”]/@href’)
这个语句我用浏览器插件演示如下:
意思就是:span标签下的子标签a里有target=”_blank”的值的href里的内容
4.第四步:写入文档,这里有记得加入一个换行符 ‘\n’
result = Content_html.xpath(‘//span/a[@target=”_blank”]/@href’)
results = ‘\n’.join(result) #在末尾加入换行
然后写入文档
with open(‘fafa_edu.txt’,‘a+’,encoding=‘utf-8’)as f:
f.write(results)

若有收获,就点个赞吧
0 人点赞
