
一,编程常识:
1.1-计算机篇
概念:
所谓的计算机其实就是由一坨硬件设备以及建立在硬件上面运行的软件所构成的集合!
诞生:
发展:
第一代计算机:电子管计算机
第二代计算机:晶体管计算机
第三代计算机:集成电路计算机
第四代计算机:大规模集成电路计算机


作用:
1-计数
计数指的就是统计事物的个数的过程,如果逐个数数分为逐一计数,如果几个一群数数,分群计数;总之计数是得到数的过程(结绳计数,摆石头,数手指等)!
2-计算
计算指的就是通过已知的数和一定的规则得到未知数(新数)的过程(口算,心算,机械计算,计算机运算等)!
思想:
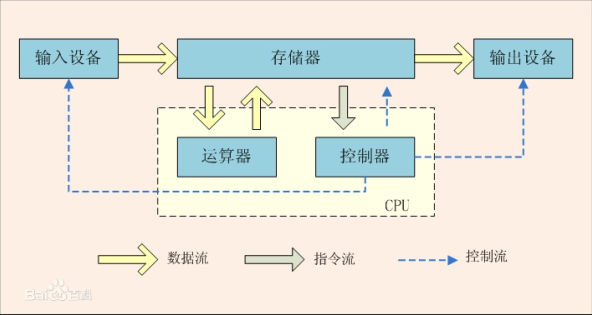
1-输入设备(键盘,鼠标)
2-输出设备(显示器,扬声器)
3-运算器(Arithmetic Logic Unit -> ALU)
运算器主要功能就是在控制信号的作用下,完成加、减、乘、除等算术运算以及与、或、非、异或等逻辑运算以及移位、补位等运算!
4-控制器(Control Unit -> CU)
控制器的工作流程为:从内存中取指令、翻译指令、分析指令,然后根据指令的内存向有关部件发送控制命令,控制相关部件执行指令所包含的操作;是计算机的神经中枢和指挥中心,只有在控制器的控制下,整个计算机才能够有条不紊地工作、自动执行程序!
5-存储器(Memory)
存储器主要是用于指令和数据的临时和长期存储!
ALU + CU = CPU(中央处理器)
构成:
1-软件
所谓的软件其实就是一坨直接/间接指挥计算机工作的指令集!
种类:应用软件(QQ,爱奇艺,浏览器等),驱动软件(显卡驱动,声卡驱动,鼠标驱动等),系统软件(操作系统)
2-硬件
所谓的硬件其实就是一坨看得见摸得着的硬件设备,比如(主板,CPU,内存条,显卡,鼠标键盘,显示器等一系列硬件设备)!
1.2-编程语言
编程概念:
所谓的编程其实就是按照一定的规则[编程语言]编写能够直接/间接指挥计算机如何工作的指令集(程序)!
编程目的:
编程的目的其实就是为了让计算机按照我们的指示和步骤去干活,最终达到指挥计算机工作的目的!
编程语言:
编程语言其实就是人和机器直接[二进制指令]/间接[非二进制指令]通信的一种规则,通过这种规则我们可以实现和计算机之间的通信(计算机能够识别我们的指令,按照我们编写出来的代码指令去执行),最终帮助我们完成一系列事情!
编程语言分类:
1-理解维度:
//越接近人,越容易理解,越靠近机器,越难理解!
机器语言:
二进制语言(0/1语言 二进制指令),计算机能够直接识别和执行,每一个二进制指令都对应一个具体的硬件操作!
优点:快
缺点:看不懂,难记忆!
汇编语言:
汇编语言其实就是符号化的二进制语言, 其实就是将二进制指令都用一个符号(汇编指令)所代替!
汇编语言 -> 汇编(汇编器:将汇编指令翻译成二进制指令的过程)->二进制指令
优点:快,相对机器指令更好记忆和书写!
缺点:需要对底层硬件和知识非常了解,本质还是二进制语言,只不过符号化了!
高级语言:更靠近人的思维,较容易理解!
C/C++:相对于二进制和汇编,算高级语言了,Python,Java,Go等!
2-思想维度:
//根据解决问题的不同思想维度划分!
面向过程语言:汇编语言,C语言
所谓的面向过程其实指的就是我们面向的是解决一个问题的具体步骤(具体)!
栗子:
吃酸辣土豆丝:
买菜谱
买菜
买厨具
洗菜切菜
烹饪
装盘
开吃!
面向对象语言:C++,Python,Java,Go
所谓的面向对象其实指的就是我们面向的是能够解决问题的一个对象(整体)!
栗子:
吃酸辣土豆丝
喊过来一个厨子/去一家饭店/美团找一家
告诉它我们要吃酸辣土豆丝,给它钱
然后送过来就吃上了酸辣土豆丝
3-是否翻译:
编译型语言[快]:C/C++
你写了一篇中文作文,然后找个翻译,一次性翻译成英语之后,直接给外国人!
解释型语言[慢]:Python,Java,Kotlin
你写了一篇中文作文,然后拉个翻译,翻译读一句中文,翻译一句英文给外国人!
1.3-操作系统
概念:
所谓的操作系统站在用户的角度其实就是一款介于用户与计算机之间方便用户使用计算机的一款软件;站在计算机系统的角度,操作系统相当于计算机系统的管理者,调度和协调者,负责管理软硬件资源,协调程序的有序运行!
种类:
Windows,Unix,Linux(Ubuntu,Centos等),Android(Linux),MacOS(Unix)
常识:
1-程序
在程序未被调入内存中运行时,它就是一坨存在于硬盘之上的一坨按照一定格式组织的指令数据和其它数据没有任何本质区别!
2-进程
只有当程序被调入内存中去运行时,我们称之为这是一个进程,所以进程描述的是一个调入内存中运行的程序(进程是独立运行和资源分配的基本单位)!
3-线程
线程是操作系统调度的基本单位,也就是说什么意思呢?如果你想要CPU去执行你的代码,你必须是个线程(具备独立运行的代码块),而线程其实就是保障一段代码块具备独立运行的一种机制!
线程的本质其实就是一种保障代码块独立运行的一种机制,本质就是一个函数!
创建进程时,创建第一个线程(程序主执行流),这个线程我们称之为主线程!
4-同步
所谓的同步其实指的就是有顺序的去访问和执行同一资源和代码,存在依赖顺序,类似接力赛,一个跑完,另外一个才可以跑!
5-异步
所谓的异步其实指的不访问同一资源和代码,无依赖顺序,各跑各的,类似个人赛,比赛一开始各自跑自的!
6-并行
同一时刻,存在多个任务同时执行,真正意义的并行存在于多核处理器中,相当于同一时刻,多个人同时干活!
7-并发
一段时间,存在多个任务都在运行,在单核处理器中,同一时刻只有一个任务在执行,在微小的一段时间内存在多个程序都在运行,宏观上的并行,微观上的并发!相当于在一段时间内,多个人在干活!
二,编程思想:
2.1-面向过程
所谓的面向过程其实指的就是我们面向的是解决一个问题的具体步骤(具体)!
栗子:
吃酸辣土豆丝:
买菜谱
买菜
买厨具
洗菜切菜
烹饪
装盘
开吃!
2.2-面向对象
所谓的面向对象其实指的就是我们面向的是能够解决问题的一个对象(整体)!
栗子:
吃酸辣土豆丝
喊过来一个厨子/去一家饭店/美团找一家
告诉它我们要吃酸辣土豆丝,给它钱
然后送过来就吃上了酸辣土豆丝
三,编程语言[C++]:
3.1-发展历史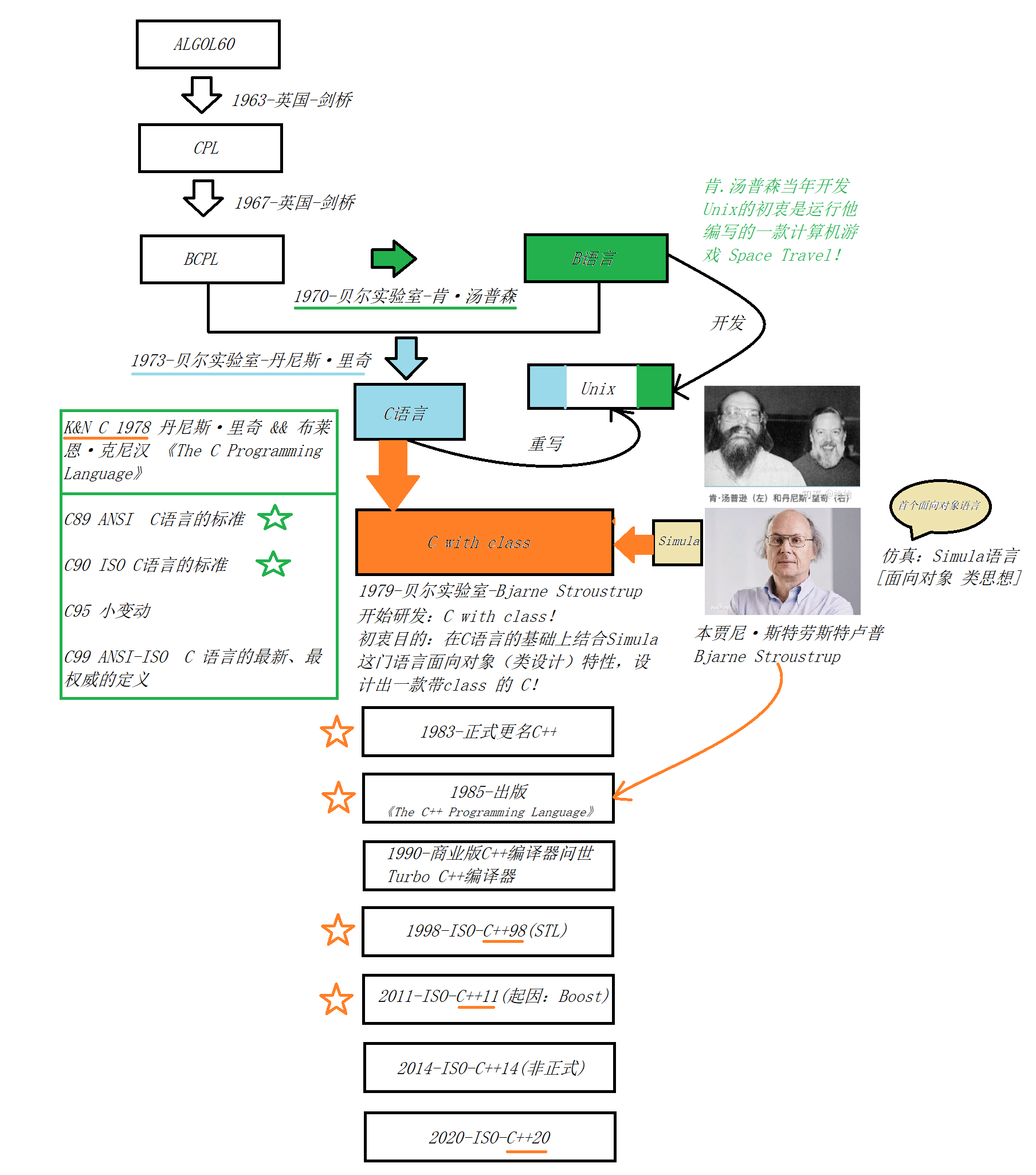
3.2-编译流程
所谓的编译型语言,指的是一次编译,直接运行,它是直接把源文件编译成计算机可以直接识别和执行的二进制指令集!
C++源程序至可执行程序:
1-源程序(C++)
2-预处理(预处理程序)
预处理阶段主要是去除注释,处理预处理指令!
注释:
// 单行注释 //多行注释
预处理指令:
预处理指令主要是写给预处理程序,通过预处理指令(凡是以#开头的,合法的,都是预处理指令)我们可以让预处理程序帮助我们完成一些事情或者操作,而预处理程序在预处理阶段其实就是处理这些预处理指令!
常用预处理指令:
宏定义指令:
所谓的宏定义预处理指令其实就是定义一个标识符用来代表一个具体数据的过程,将来在所有引用这个具体数据的地方,我们统统用这个标识符代替,一旦我们的这个具体的数据在程序多处引用,我们只需要在这个标识符声明的地方将具体数据修改一下即可,不需要多处修改,减少工作量,将来在预处理阶段,我们的预处理程序会根据宏定义来替换所有的标识符为具体的数据(纯粹的文本替换,宏定义时不要吝啬括号)!
无参宏:#define 宏名 宏体 //#define PI 3.14
有参宏:#define 宏名(参数列表) 宏体 //#define SUM(X,Y) (X)+(Y)
特殊宏:双引号,单引号,连接
#define A(x) #x //A(1) -> “1”
#define A(x) #@x //A(1) -> ‘1’
#define A(x,y) x##y //A(“12”,”34”) -> “1234”, A(12,34) -> 1234
包含头文件:
任何东西在使用的时候,必须要先有这个东西,即存在声明,而声明存在于一个.h文件,那么我们就必须要在使用前,先包含这个头文件,如果存在于同一个文件内,就不需要包含,我们通过头文件包含预处理指令就可以让预处理程序帮我们将需要包含的头文件包含进来,我们只需要告诉预处理程序,包含哪个头文件即可!
包含系统头文件:#include
包含自己头文件:#include “xxxx.h”
1-#pragma once
2-通过宏来避免
#ifndef xxxx
#define xxxx
…
#endif
条件编译指令:
#if 条件
#endif
//
#if 条件
#else
#endif
//
#if 条件
#elif 条件
#else
#endif
#pragma指令:设定编译器状态或者指示编译器完成一些指定动作!
防止头文件包含#pragma once
引用动态库#pragma comment(lib,”xxxxx”)**
用于警告信息#pragma warning(xxxxx)
编译输出窗口输出消息#pragma message(“消息文本”)
3-编译阶段(编译程序 编译器)
编译阶段其实就是将预处理处理好的程序交付给我们的编译程序进行编译,最终呢通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码或汇编代码!
4-汇编阶段(汇编程序 汇编器)
将编译好的中间代码或者汇编代码交付给我们的汇编程序,最终呢会生成对应汇编代码的二进制程序!
5-链接阶段(链接程序 链接器)
6-可执行程序(二进制程序)
可执行程序也是按照一定格式组织起来的,这种格式windows下被称之为PE格式,Linux被称之为:ELF格式!
3.3-基本常识
数据定义:
站在现实角度我们把描述事物的符号我们称之为数据,在计算机的角度来看,凡是能够输入到计算机内,被计算机所识别和处理的我们称之为数据!
描述定义:
任何一个事物我们都可以用一个符号来代表它,那么这个过程就称之为符号化,比如长城是一个具体的建筑,我们用”长城”这样的一个标识来代表和描述它,就称之为长城这个具体建筑的描述!
抽象定义:
所谓的抽象指的是当我们抛开具体的细节和数据,我们发现它们是一个东西,比如1,2,3,4,5;这都是具体的数据,当我们抛开它们具体的含义和数值时我们发现它们是一个东西,当我们用一个符号来代表符合这一特征的一类具体数据时,那么这个过程就称之为抽象过程,所谓的抽象其实就是抛开具体,符号表示!
3.4-基础语法
内存模型:
1-组成
从逻辑上看内存就是由一个一个小格子构成的存储空间,每个小格子我们称之为一个存储单元(字节[Byte]),存储单元是构成内存的基本单位,同时也是访问内存空间的基本单位!
每个存储单元(Byte),又是由8个更小的格子构成,这个更小的格子我们称之为位(比特[bit])!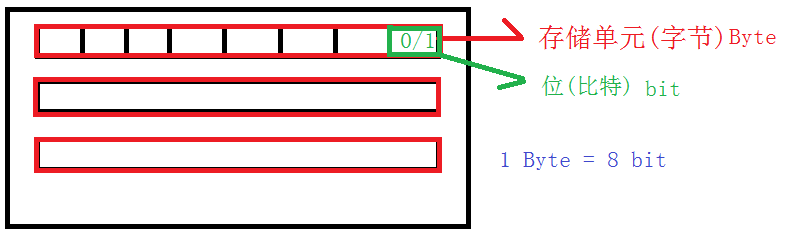
换算:
1 Byte = 8 bit,1KB = 1024Byte,1MB = 1024 KB
比特流:
由0/1构成的一串二进制流,比如:010100100010010010010001!
2-地址
每一个存储单元都对应着一个唯一的标记,这个标记就是用来找到对应的存储单元的,我们把它称之为地址(这就类似于人类的房屋地址,每个房屋都对应着一个位置信息,同时通过位置信息我们就可以找到对应的房屋)!
3-存储
数据在内存中存储时,如果是单字节数据存储(一个字节),高位bit存高位,低位bit存低位;如果是多字节数据存储(产生一个问题?那就是数据的高低字节是存放在内存空间的低地址还是高地址?),那么就对应两种存储模式:大端存储和小端存储!
数据:0x12345678 高字节~低字节
地址:高地址~低地址 (78 56 34 12),(12 34 56 78)
大端模式:数据低字节 -> 高地址
小端模式:数据低字节 -> 低地址
那么我们该如何判断是大端还是小端?其实很简单,我们只需要记住一句话:数据的低字节存放在高地址还是低地址;另外大端,小端存储模式,讲的是多字节数据,高低位字节,高低地址!
4-四区
栈区:
栈是由编译器自动分配释放使用的,主要用于局部变量,函数参数等内存的分配,在编译阶段已经确定(在编译阶段就把栈区规划好),一旦离开对应的作用域,那么对应栈上面开辟的内存就会被自动释放掉
栈的地址增长结构:高地址~低地址!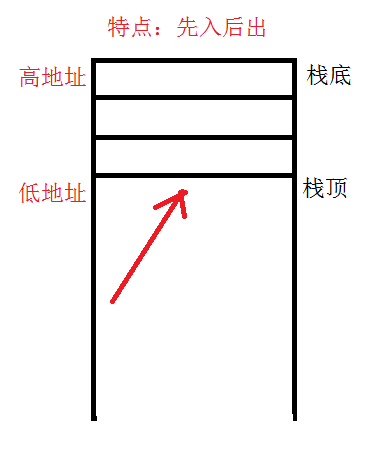
堆区:
堆区是提供给开发人员手动分配和释放,通过malloc,free,new,delete等关键字进行堆上内存空间的开辟和释放,如果忘记释放,就会导致内存泄漏!
数据区:
全局区:
用来存放全局变量和static变量(初始化和未初始化的全局变量和static变量是分开不同区域存储,都在全局区)!
常量区:
常量字符串存在于文字常量区中!
代码区:
代码指令!
数据类型:
1-概念
由同一类具体数据(数据元素)所构成的集合以及建立在这个集合上面的操作所构成的集合,我们称之为数据类型!
栗子:1,2,3,4,5,6….(同一类数据元素) + +-/%(运算操作) ,*用一个标识来代表它,比如:int (数据类型)
2-本质
指明:所存储数据的类型
指明:所占内存空间大小
本质:固定内存大小的别名!
3-种类
基本数据类型:整形,浮点型,字符型,布尔类型
复杂数据类型:引用,数组,字符串,结构体,共用体,枚举,指针变量
数据类型详解
数据存储:
1-常量
一个具体的数据我们称之为常量,一旦修改它就不是这个数据了就是常量,比如3.14,”qiyawei”,’c’,这些具体的数据我们都称之为常量!
定义常量:
宏定义常量:
#define PI 3.14 //宏定义常量,预处理阶段,就会将宏符号全部用具体的常量数据所替换!
Const 常量:
特点:必须进行初始化,不可修改!
const修饰全局变量:可以在本模块中使用,但不可被修改,在其它模块中不可使用!
const修饰局部变量:通过变量名无法进行修改,通过指针间接指向可修改!
const修饰指针变量:
谁不可变,去除数据类型标识符就看const修饰的是还是指针变量名!
int const p; const修饰的是指针变量p,指针变量p自身不可修改!
const int p;int const p; const修饰的是*p,指针变量p所指向的地址所指向的内存空间不可修改!
const修饰函数形参:
如果是基础数据类型的值拷贝,原始对象不会因为函数操作而改变,所以不需要使用const特殊修饰!
参数为指针或者引用类型,意味着通过指针访问到的就是外部数据,如果我们想要指针指向的外部数据,我们可以底层const,也就是const修饰来标记!
const成员变量:
const成员变量只能在构造函数中进行初始化,对于对象来说是不可变的,对于类来说,每个对象的const成员变量可以不一致!
const成员函数:
不可以修改成员变量!
*const 类对象:
常对象不可调用非const函数!
类对象可以调用所有函数!
2-变量
我们知道食材需要存储,那么我们的数据呢也是需要存储的,用来存放数据的存储单元我们称之为变量,通常呢我们会定义一个标识符用来代表这个存储单元我们称之为变量名。变量其实是对同一类具体数据的封装和抽象,它代表的是一类具体的数据,只有给这个变量赋予一个具体的数据时这个变量才具体代表一个数据,所以变量是用来存储一类具体数据的!
存储数据->声明变量->开辟内存空间:
开多大?要存储数据的类型决定,由数据类型名进行标识!
开在哪?通常我们会定义一个标识符(变量名)用来代表我们所开辟的那段内存空间!
变量的定义:
数据类型 变量名;//开辟内存空间
变量的声明:
extern int num;
只是告诉编译器我们声明了这样的一个变量它长这个样子,并没有开辟内存空间,它会去本模块或者其它模块中去找这个变量!
声明-定义的区别:
如果是extern声明的变量,我们只是告诉编译器,我们声明了这样的一个变量,它长这个样子,并没有开辟内存空间,它会去本模块或者其它模块中去找这个变量。如果我们是int num,这样的形式声明变量,那么就意味着不仅声明了一个长这个样子的变量,同时还在内存空间中开辟了相应的内存空间,声明和定义的区别就在于是否开辟内存空间!
数据运算:
一切皆由变化起,变化皆有运算来!![编译型语言[C ] - 图10](/uploads/projects/lengjing-4oxve@avmwz7/7554fbb44987e3891823318147d379ad.jpeg)
建议使用大括号来区分优先级,优先级我也记不住,反正加括号就对了!
逻辑控制:
![编译型语言[C ] - 图11](/uploads/projects/lengjing-4oxve@avmwz7/5f22b9aba80accd6c916415f0cfe2631.jpeg)
3.5-面向过程
编程序言:什么是面向过程?
所谓的面向过程其实指的就是我们面向的是解决一个问题的具体步骤(具体的操作细节)!
函数本质:
函数就是用来完成一定功能的一段代码,它其实是对完成同一类具体事情的封装和抽象;针对的是同一类事情,但仅仅只是操作的数据不同,当我们不考虑具体的操作数据,发现是在做同一件事情时,抽取出来共有的操作步骤的时,抽象出来的就是函数!
函数定义:
//声明同时实现
返回值类型 函数名(形参列表)
{
函数体
}
//声明实现分开
返回值类型 函数名(形参列表);//声明
+
返回值类型 函数名(形参列表) //实现
{
函数体
}
函数调用:
函数重载:
函数名相同,参数个数不同或者类型不同或者类型不同的参数顺序不同的函数互为重载函数(静态多态)!
注意点1:跟返回值没关系
注意点2:不可有歧义
void f(int a,int b=10) , void f(int a) //当传递一个参数时,无法区分是哪个函数,所以有问题!
调用函数时,会根据参数自动匹配对应的函数!
函数指针:
函数名的本质就是指向一个函数的入口地址,指向一个函数入口地址的指针!
定义方式:
方式1:封装类型 声明对应类型指针
typedef int(类型名)(参数类型名)
类型名 指针变量
方式2:直接将函数指针封装成类型
typedef int(类型名)(参数类型列表)
类型名 变量
方式3:声明指向函数类型的指针变量
int(*指针变量)(参数类型列表)
函数指针和重载之间的关系:
当我们声明一个指向一种某种类型的函数指针变量的时候,我们必须给它赋值对应的函数,这时候我们的指针就直接指向这个函数的入口地址,如果这个函数有很多个重载函数,我们编译器会自动匹配与这个指针变量所指向的这个类型的函数相同的那个函数,并将入口地址传递给我们的指针变量
void f(int a,int b) void f(int a,int b,int c)
void(*fp)(int,int) ->编译器会自动将void f(int a,int b)地址赋值给函数指针,同时传递参数时必须传递对应参数!
3.6-面向对象
编程序言:什么是面向对象?
面向对象其实指的就是我们面向的是能够解决问题的一个对象(整体)!
基本概念:
对象:
世间万物任何一个具体的事物我们都可以把它当成一个对象(万物皆对象),任何对象都会具有两个特征(属性,行为)!
属性:
属性其实是对同一类特征的封装和抽象,最终我们用变量来进行描述属性特征!
行为:
行为其实是对同一类动作或操作的封装和抽象,最终我们用函数来进行描述行为!
类:
当我们对同一类具体对象共有属性和行为封装的时候,我们得到的就是一个类,它其实是对具有共有属性和行为的一类具体对象的抽象描述,解决的是频繁创建同一类具体对象所产生的代码冗余的问题!
类的本质:
类的本质就是属性,行为,访问控制权限的聚合体!
对象属性:
普通变量
特殊变量:变量类型是个类
构造函数初始化列表:
当一个类中包含另一个类作为自己的成员变量的时候,我们调用自身的构造函数的同时需要调用另一个类对应的构造函数来初始化它自己,就需要用到初始化列表的语法!
class B
{
public:
B(int a,int b):m_a(a)
{
m_b =b;
}
int m_b;<br /> A m_a;<br />}<br />如果一个类中组合多个类的对象,构造函数的顺序只跟定义类对象的顺序有关,析构的顺序与之相反;当一个类中有const成员变量的时候,也是要通过初始化列表来进行对const变量进行初始化,跟初始化内部类对象一样!<br />**对象行为:**<br />普通成员函数<br />**特殊成员函数:**<br />**构造函数:**<br />构造函数就是在构造对象的时候自动被调用,用来完成对象的一些初始化工作!<br />类名()<br />{
}
种类:
默认构造函数
无参构造函数,拷贝构造函数
手写构造函数
无参构造,有参构造,拷贝构造
当显示的书写无参,有参,拷贝构造函数,默认构造函数都会失效
使用:
析构函数:
析构函数就是在销毁对象前自动被调用用来完成一些善后处理工作!
~类名()
{
}
父类采用virtual虚析构目的:防止内存泄漏,调用父类析构之前,先调用子类析构函数!
类属性:
static 变量 //类名::类变量名
类行为:
static 方法//类名::类方法名
访问控制权限:
我们通过访问控制权限修饰符就可以实现对成员变量,成员函数的访问权限设置!
public 公有的 private 私有的 protected 继承的
使用:
栈:类名 对象名;
堆:类指针 = new 类名();
匿名对象的生命周期:
如果我们在一个函数内部创建了一个没有人接收的匿名对象,那么这个匿名的生命周期就只存在于这一行, 因为没有人接收,就会被立马析构掉,如果有人接收将按照函数的生命周期一样,等函数执行完毕释放这个对象时才开始调用析构函数!
三大特征:
封装:
类的本质就是属性,行为,访问控制权限的聚合体,隐藏对象的属性和实现细节,仅对外公开接口,控制在程序中属性的读和修改的访问级别!
继承:
当我们的多个类中包含共有部分的时候或者我们需要拥有一些类的东西的时候,我们不需要每个类中都去写一份我们想要拥有的东西,我们只需要按照一种语法规则就可以拥有这些东西,这就是继承,继承解决的问题就是代码冗余的问题!
格式:
class child_class : 继承权限修饰符 parent_class,…可以继承多个类
{
访问控制修饰符:
….
}
权限:
public,protected,private三种权限继承方式!
模式:
单继承:子类继承一个父类
子类一旦继承了父类,那么子类就会拥有父类的东西,那也就是说在开辟的子类内存空间中就会包含父类内存空间。如果父类中有虚函数,那么子类中的父类空间中就会存在一个虚函数表指针,指向一个虚函数表,如果子类没有重写父类的虚函数,那么依然是父类的虚函数,如果子类重写了父类的虚函数,那么就会变成子类的虚函数,如果子类自己的虚函数那么就会被加入到这个虚函数表的尾部!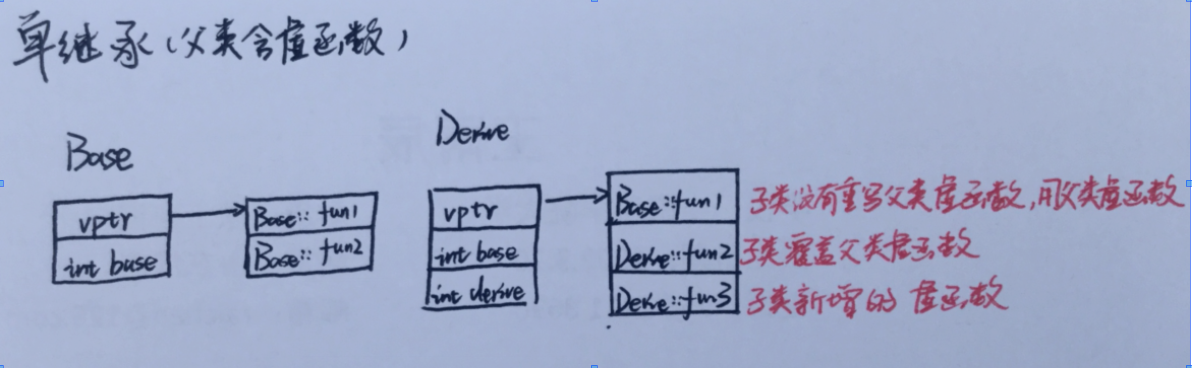
多继承:子类继承多个父类
子类一旦继承于多个父类,那么子类对应的内存空间中就会拥有多个父类的东西,那也就是说子类空间中包含多个父类空间的。如果父类中有虚函数那么子类中的父类空间中就会有一个指向虚函数表的指针,指向一个虚函数表,如果子类没有重写父类虚函数,那么依然还是父类虚函数,如果子类中重写了父类虚函数,那么父类的虚函数就被子类虚函数所替换,如果子类自己的虚函数那么将会别加入到第一个拥有虚函数父类的虚函数表的尾部中!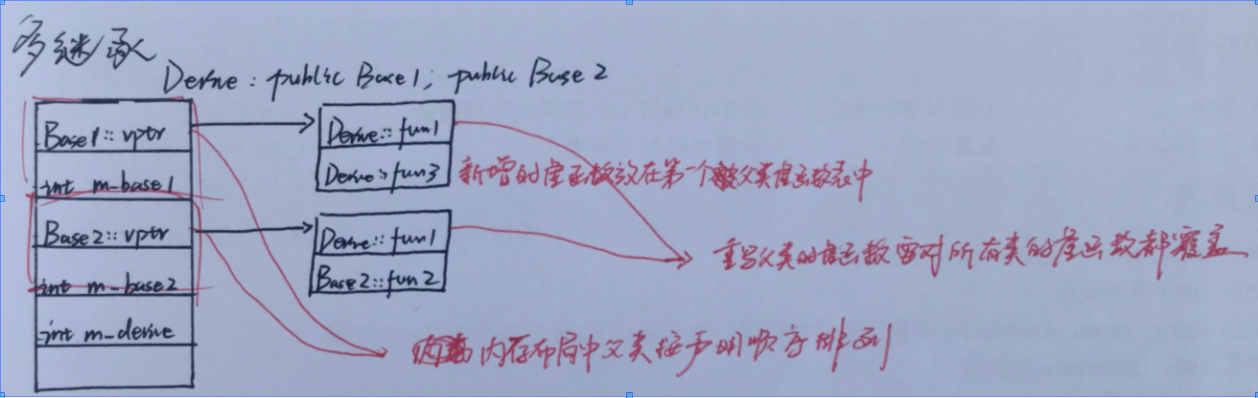
虚继承:
简单虚继承:子类虚继承父类
子类一旦虚继承了父类,那么子类中就会拥有父类的东西,依然是子类空间中包含父类空间,只不过这时候如果子类中有自己的虚函数,那么子类对象内存空间中,将会出现自己的指向虚函数表的指针,指向自己的虚函数表,并且还有一个vptr表,里面存放了父类虚函数表对应首地址偏移量的一个表,我们也正是通过这个vbptr表来找到拥有虚函数表的父类对应的虚函数表的。如果子类没有重写那么子类空间的父类空间中的虚函数依然是父类虚函数,如果子类重写,那么父类虚函数就会被子类虚函数所替换,如果是子类自己的虚函数,那么就仅存在于子类自己的虚函数表中!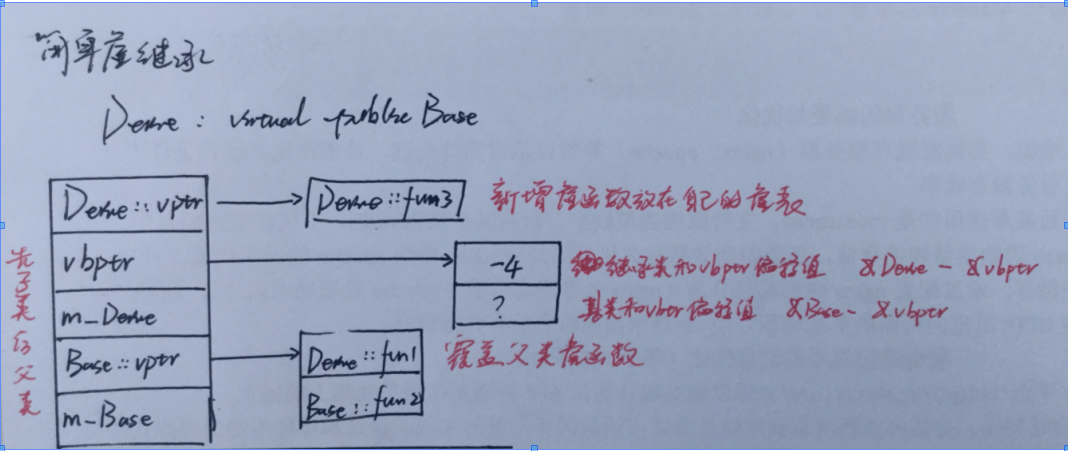
菱形虚继承:菱形虚继承指的就是子类继承多个父类,而多个父类又虚继承于同一个基类,那么这时候就是菱形虚继!
一旦形成菱形虚继承这种关系模式,那么如果子类中有虚函数,那么它会有自己的一套虚函数机制(虚函数指针及虚函数表),并且我们子类的内存空间中会有多个父类对应的内存空间,每个父类内存空间中如果有虚函数,那么它们都会有一个虚函数表指针,指向一个虚函数表,如果多个父类又虚继承同一父类,那么这些父类空间中还会有一个vbptr指针指向一个vbptr表,并且这些父类中只会有自己的数据并没有基类的数据,基类的数据会进行单独存放处理,如果这个基类中有虚函数,那么依然会有对应虚函数表指针以及对应的虚函数表!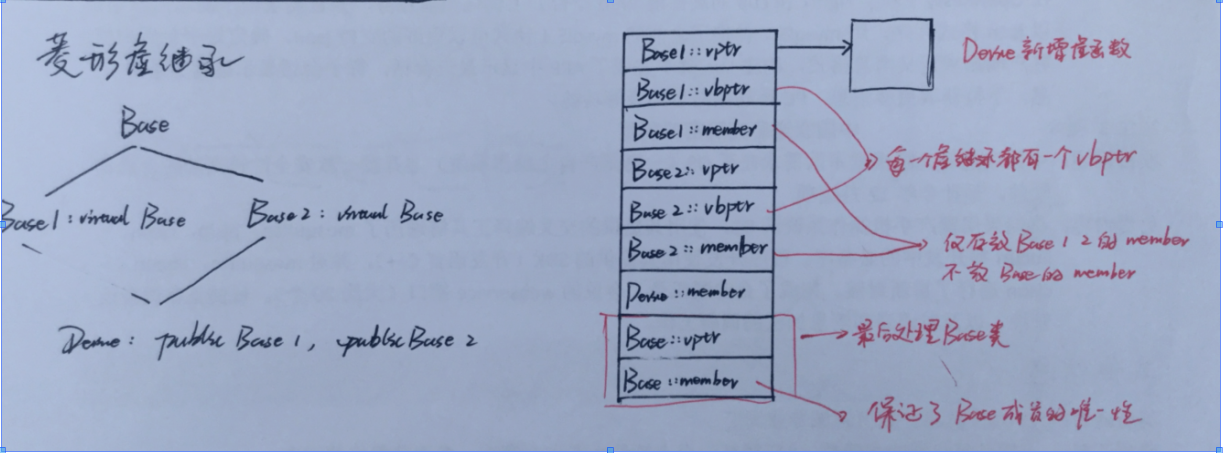
无论是什么样的继承方式我们要解决的问题就是避免冗余代码,父类的东西只需要写一遍就OK了,我们只需要通过继承这种语法,我们就可以拥有父类的东西,当然由于继承访问控制权限的不同,我们对父类空间中的成员所拥有的访问权限也不相同!
多态:
如果说继承是抽取公共部分,解决代码冗余的问题,那么多态就是解决差异化的问题,具体的对象通过同一个接口就可以实现各自形态的体现,你是什么就是什么!
方式1:函数重载,静态多态,编译时期就进行绑定!
方式2:父类定义为虚函数,子类重写虚函数,父类指针指向子类对象,发生多态!
一旦我们的子类对象继承了父类,并重写了父类的虚函数,那么在创建子类对象的时候,我们子类对象的内存空间中的父类内存空间所对应的虚函数表中的虚函数将不在是父类的虚函数,而是子类的虚函数,而我们编译器在编译的时候,一旦发现调用的是虚函数,那么它将不会在编译的时候就进行绑定,我们的父类指针指向的是一个子类对象,在创建这个子类对象的时候,由于子类重写了父类的虚函数,那么子类空间中对应的父类空间所对应的虚函数表中的虚函数,将会是子类重写后的虚函数,那么这时候我们调用,去查找这个虚函数表的时候,将调用的是子类的虚函数!
3.7-友元特性
友元函数:
友元类:
操作符重载:
3.8-泛型模板
泛型本质:
函数模板:
类模板:
3.9-版本迭代
四,核心技术[C++]
4.1-多线程
4.2-多进程
4.3-库封装
4.4-网络篇

若有收获,就点个赞吧
0 人点赞
