
页
InnoDB操作数据的最小的逻辑单位:页。(数据页,索引页)。
页之间采用双向链表连接,页内部的数据采用链表进行连接。
根据节点的大小,页能可能存储多个B+树节点。
使用一种缓冲池技术,将磁盘的页放到一块内存区域里面,这个内存区域叫做Buffer Pool。
Buffer Pool
BufferPool
Buffer Pool
- Buffer Pool(默认大小128M)
- change Buffer
- Adaptive Hash Index
缓冲池满了,默认采用LRU算法来管理缓冲池。
当需要更新一个数据页时,如果数据页在 Buffer Pool 中存在,那么就直接更新好了。 否则的话就需要从磁盘加载到内存,再对内存的数据页进行操作。也就是说,如果 没有命中缓冲池,至少要产生一次磁盘 IO
ChangeBuffer
用于在对数据变更时,如果数据所在的数据页没有在 buffer pool 中的话,在不影响数据一致性的前提下,InnoDB 引擎会将对数据的操作缓存在 Change Buffer 中,这样就省去了从磁盘中读入这个数据页。
- 优点:
利用写缓存减少磁盘的随机IO操作,提升数据库性能
先把修改记录卸载内存的缓冲池中,就是ChangeBuffer。
何时写入到磁盘的changeBuffer中:
- 访问该数据页
- 通过后台线程
- 数据库shut down
- redo log 写满的时候
何时将change刷入到数据页:
- 原始数据页加载到bufferPool的时候
- 系统后台定时触发merge操作
- MySQL数据库正常关闭的时候
以下情况不适合开启ChangeBuffer:
- 数据库都是唯一索引
- 写入一个索引后,会立刻读取他
以下情况适合开启ChangeBuffer:
- 数据库大部分都是非唯一索引
- 业务写多读少
- 写入数据后不会马上读取他
redo log buffer
用于实现事务的持久性,对应的磁盘的redo log,即MySQL里面的WAL技术(Write ahead logging)== 先写日志 再写磁盘。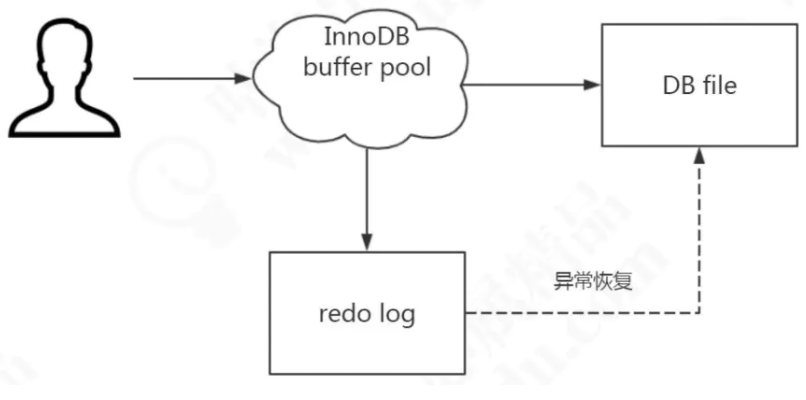
- 为什么不直接写入磁盘,而是先写入日志
(用顺序IO代替随机IO提高系统吞吐) 如果我们所需要的数据是随机分散在不同页的不同扇区中,那么找到相应的数据需 要等到磁臂旋转到指定的页,然后盘片寻找到对应的扇区,才能找到我们所需要的一块 数据,一次进行此过程直到找完所有数据,这个就是随机 IO,读取数据速度较慢。 假设我们已经找到了第一块数据,并且其他所需的数据就在这一块数据后边,那么就不需要重新寻址,可以依次拿到我们所需的数据,这个就叫顺序 IO。 刷盘是随机 I/O,而记录日志是顺序 I/O,顺序 I/O 效率更高。因此先把修改写入日 志,可以延迟刷盘时机,进而
提升系统吞吐。
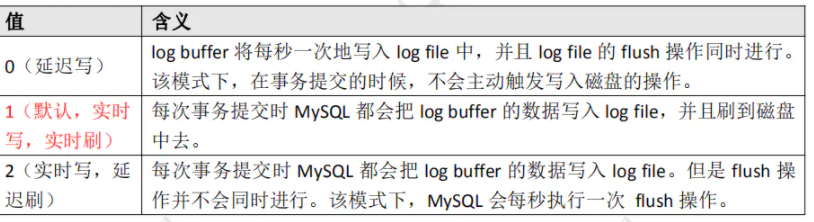
- 什么时候写入磁盘
缓存池内部有一个日志缓冲,专门用于保存即将计入日志文件的数据
磁盘结构
所有的数据都存放在表空间中,InnoDB的表空间分为5类:系统表空间,
增删改查语句执行原理
select
select * from user where username = ‘Java3y’
- 查看对应页是否在缓存中,如果不是的话需要去磁盘加载。每次都是将一页放入内存中去进行操作,所以页内部的检索非常快。
- 定位记录所在的页
- 遍历双向链表,找到所在的页
- 在页中查找对应的记录
update
update user set name = 'penyuyan' where id=1;

- 先将修改记录到内存,redo log状态变为prepare
- 存储引擎告诉执行器,执行完成,可以提交事务
- 执行引擎写入binlog,然后调用存储引擎接口,设置redo log为commit状态
- 更新完成
1、先记录到内存,再写日志文件。 2、记录 redo log 分为两个阶段。
3、存储引擎和 Server 记录不同的日志
4、先记录 redo,再记录 binlog。

若有收获,就点个赞吧
0 人点赞
