论文出版于ICLR 2021。
- 论文:https://arxiv.org/pdf/2010.01412.pdf
- 代码:https://github.com/google-research/sam
- PyTorch:https://github.com/davda54/sam
方法
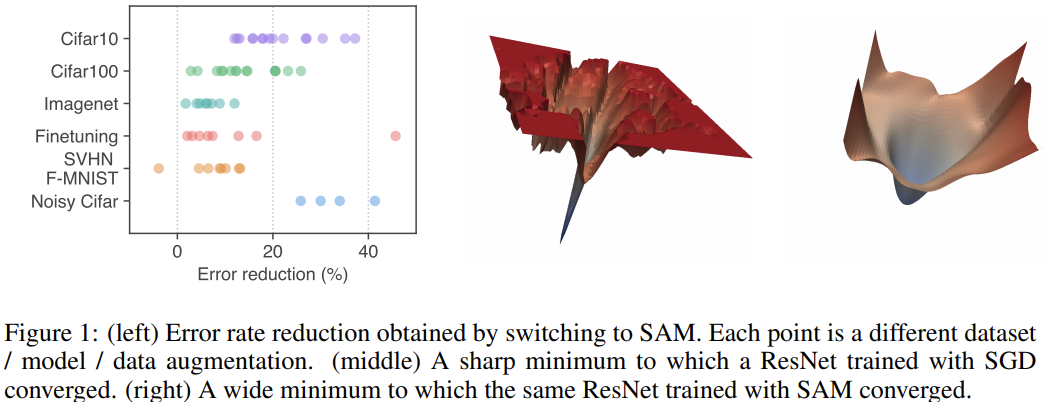
Motivated by the connection between sharpness of the loss landscape and generalization, we proposea different approach: rather than seeking out parameter values w that simply have low training loss value LS(w), we seek out parameter values whose entire neighborhoods have uniformly low training loss value (equivalently, neighborhoods having both low loss and low curvature).
- PyTorch:https://github.com/davda54/sam

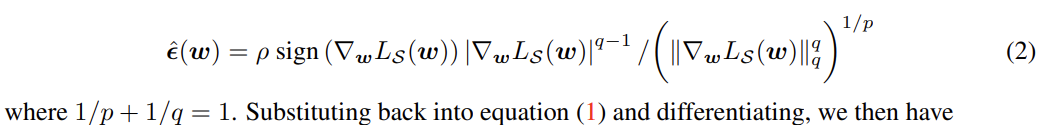
整体的计算过程可以总结为五步:
- 使用旧的权重前向传播后损失回传获得旧权重对应的梯度
- 使用SAM获得对应于旧权重的调整量并更新权重
- 使用新权重重新前向传播后损失回传获得新权重对应的梯度
- 将新权重调整回旧权重,但是其梯度仍使用新的梯度
- 使用新梯度更新旧权重
所以该算法需要两次前向传播,对于PyTorch,最基本的流程如下:
# 注意这里写的过程与参考连接中的pytorch代码并不完全一样,参考连接中将一些优化器的操作封装了起来# 这里为了明晰,将其取了出来outputs = model(data) # 使用旧权重前向传播loss = self.criterion(outputs, targets)loss.backward() # 获得旧权重的梯度if use_sam:sam.finetune_weight() # 微调旧权重optimizer.zero_grad() # 梯度归零,因为旧权重的梯度不是我们想要的model.eval() # 保证BN的统计量只在第一次前向传播中计算(具体可见参考连接中pytorch代码的readme)outputs = model(data) # 使用新权重前向传播loss = self.criterion(outputs, targets)loss.backward() # 获得新权重的梯度sam.restore_weight() # 1. 恢复旧权重,2. 保留新权重的梯度model.train() # 恢复BN的状态optimizer.step() # 更新权重为w^{SAM}_{t+1}optimizer.zero_grad() # 梯度归零,准备下一次迭代
效果
暂未获得明确的具有性能提升的效果。不知道是否使用的有问题。

若有收获,就点个赞吧
0 人点赞
