聚类(Clustering)
1.基于划分的聚类方法
给定一个由个n对象组成的数据集合,对此数据集合构建k个划分( k<=n ),每个划分代表一个簇,即将数据集合分成多个簇的算法。
要求:①每个簇至少有一个对象;
②每个对象必须且仅属于一个簇。
典型算法k-均值和k-中心点算法等。
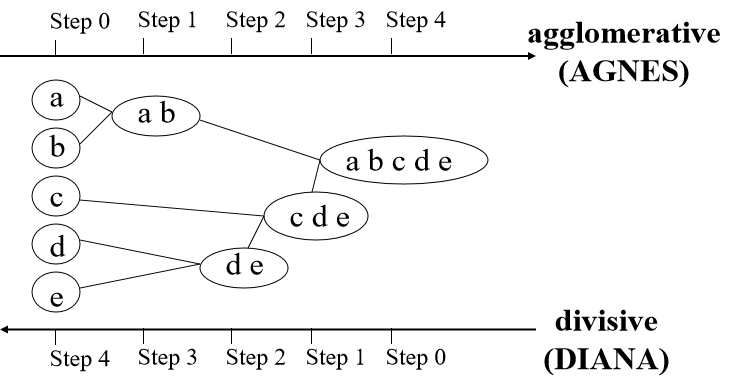
2.基于层次的聚类方法
典型算法:CURE、Chameleon和BIRCH等
1)CURE算法描述
随机选取s个样本;
将所有样本划分为p个簇,每个簇的样本数是s/p;
将每个簇划分为q个子集,每个子集样本数是s/pq
删除孤立点数据
• 随机取
• 如果一个簇变化缓慢,则删除该簇
合并其中的部分子集
2)CHAMELEON算法
首先,使用图分割算法将数据集合划分为多个子集;
然后,使用层次聚类中的凝聚方法将这些子集进行反复的合并,直至获得最终的聚类结果。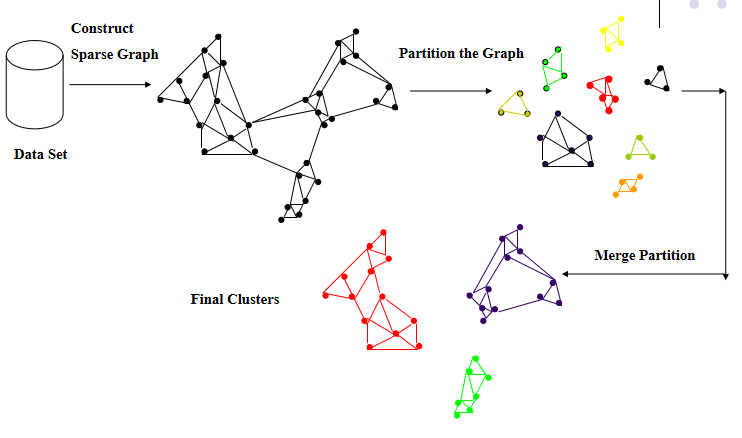
3.基于密度的聚类方法
这类算法的思想是,只要某簇邻近区域的密度超过设定的某一阈值,则扩大簇的范围,继续聚类。这类算法可以获得任意形状的簇。
典型算法:DBSCAN、OPTICS和DENCLUE等
4.基于网格的聚类方法
基于网格的聚类算法首先将问题空间量化为有限数目的单元,形成一个空间网格结构,随后聚类在这些网格之间进行。这类算法速度较快。
典型算法:STING、WareCluster和CLIQUE等
5.基于模型的聚类方法
基于模型的聚类算法为每个簇假定一个模型,寻找数据对给定模型的最佳拟合。所基于的假设是:数据是根据潜在的概率分布生成的。
典型算法:COBWEB和神经网络算法等。
分类(Classification)
分类的目的是获得一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到某一个给定类别。
分类可用于提取描述重要数据类的模型或预测未来的数据趋势。
聚类和分类的区别
分类是有监督的学习, 聚类是无监督的学习
分类就是按照某种标准给对象贴标签(label),再根据标签来区分归类。
聚类是指事先没有“标签”而通过某种成团分析找出事物之间存在聚集性原因的过程。
适用场景:
1.分类适合类别或分类体系已经确定的场合,比如按照国图分类法分类图书;
2. 聚类则适合不存在分类体系、类别数不确定的场合,一般作为某些应用的前端,比如多文档文摘、搜索引擎结果后聚类(元搜索)等。
有监督学习:使用的是有标签的数据(即实现分好类了)
无监督学习:使用的数据时没有标签的。
分类的实现
1.构建模型:预设分类类别
对每个样本进行类别标记
训练集构成分类模型
分类模型可表示为:分类规则、决策树或数学公式 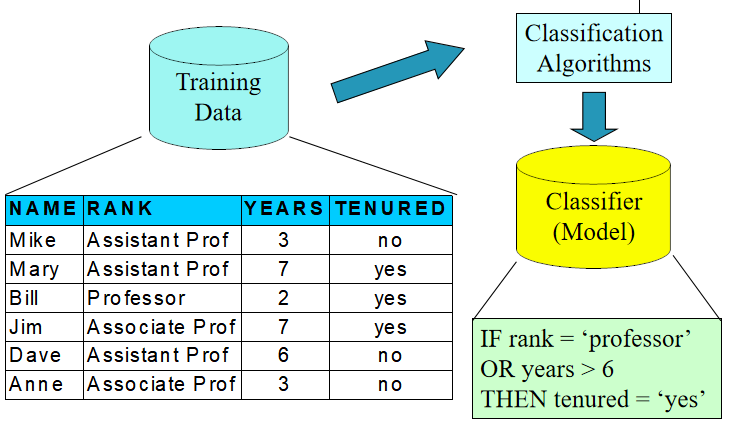
2.使用模型:识别未知对象的所属类别
模型正确性的评价
已标记分类的测试样本与模型的实际分类结果进行比较
模型的正确率是指测试集中被正确分类的样本数与样本总数的百分比。测试集与训练集相分离,否则将出现过拟合( over-fitting )现象。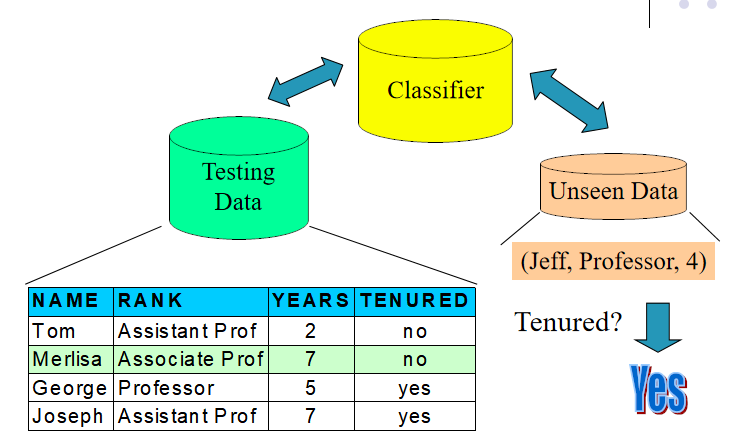
常见的分类算法
决策树算法
采用自上而下的递归构造。
剪枝的类型
- 向前剪枝(forward pruning)在生成树的同时决定是继续对不纯的训练子集进行划分还是停机。
- 向后剪枝(backward pruning)是一种两阶段法:拟合-化简(fitting-and-simplifying),首先生成与训练数据完全拟合的一棵决策树,然后从树的叶子开始剪枝,逐步向根的方向剪。
当数据稀疏时,要防止过分剪枝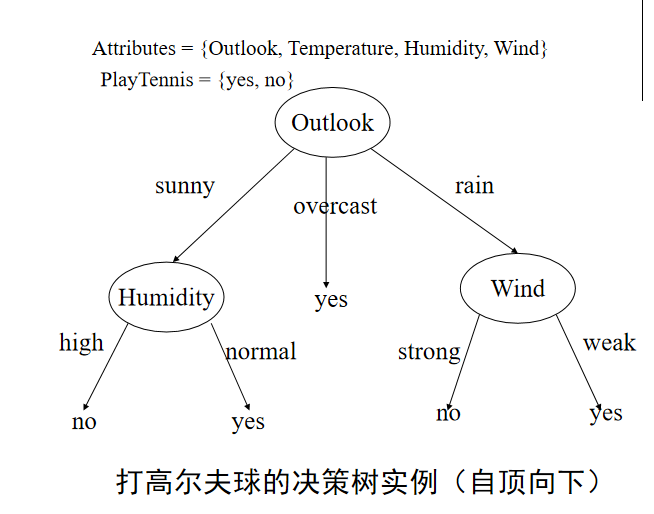
CLS算法
ID3算法
C45算法
Autoclass算法
关联(Association)
预测(Prediction)
数据挖掘的可视化
数据挖掘的实施
数据挖掘的工具

若有收获,就点个赞吧
0 人点赞
