一、弹性负载均衡功能的实现
1.1总体设计思路
传统的应用系统以物理机或虚拟机(VM)为底层的基础设施,当系统面临周期性或突发式业务高峰期时,要保证系统的稳定,服务的高可用,流畅的用户体验,传统的做法是对虚拟机或物理机做冗余备份,在业务高峰期时启用,提供服务,增强系统的处理能力;在业务量回归正常水平时,通过停机处理,回滚到系统正常的处理能力。这种传统的做法全程需要运维人员的手动操作,不仅周期时间长,而且经常出现难以预测的错误,极大地增加了运维成本;在Docker容器出现后,这种棘手的问题迎刃而解,由于Docker相比与虚拟机,在系统开销、启动速度上有明显的优势,而且也有非常好的资源隔离效果。所以通过对应用系统的Docker化迁移改造,采用微服务架构,将传统的单体应用拆分为具有原子性的更小粒度,以Docker容器作为运行微服务实例的载体。在系统面临突发式负载时,应用系统采用横向伸缩,快速启动多个业务容器,迅速提升系统的处理能力,保证应用系统的稳定、高可用以及流畅的用户体验。基于Docker容器实现的动态负载均衡弹性伸缩系统如图3所示。<br />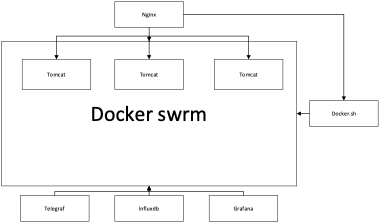<br />图5基于Docker swarm容器实现的动态负载均衡弹性伸缩系统<br /> <br /> 由图5可知,本系统底层的Docker监控系统由Telegraf、Influxdb 和 Grafana 组合实现。Telegraf 作为最前端的数据采集工具,可以分布在不同的数据节点上,收集宿主机和应用容器的CPU、内存等资源使用量指标;Influxdb 是一个时序数据库,将Telegraf采集的数据进行后端存储;Grafana是一个数据展示工具,通过配置数据源,读取存储在Influxdb中的数据并展示。Docker swarm组件作为服务发现机制,提供当前系统可用的容器数量。<br /> Nginx组件结合实现对swarm暴露端口的反向代理,Nginx是一个C语言编写的应用程序代理软件,提供高可用和负载均衡服务,适用于大流量、高并发的web站点中。本系统的弹性伸缩模块主要由Docker.sh脚本文件实现,可以手动调用或自动调用。在应用系统面临高并发、大流量的突发式请求时,监控系统会监测到应用容器的CPU、内存等资源使用量迅速上升,对应的策略就是通过设置告警阈值来触发弹性伸缩机制。以递增步长的节奏进行扩容;峰值过后,以固定步长的节奏进行缩容。由弹性伸缩模块启动或删除的应用容器,之后就会将前端的用户请求分流到后端的应用容器上,提供具体的服务,实现应用系统的负载均衡。此动态负载均衡弹性伸缩系统依据应用容器的负载状态,来提供对应的处理能力,按需供给,在保证系统的稳定运行的前提下,将系统开销降低到最低。<br />
1.2 平台搭建
1.2.1 Docker 安装
①系统要求
Docker 支持 64 位版本 CentOS 7/8,并且要求内核版本不低于 3.10。 CentOS 7 满足最低内核的要求,但由于内核版本比较低,部分功能(如 overlay2 存储层驱动)无法使用,并且部分功能可能不太稳定。
②卸载旧版本
为了防止冲突需要卸载旧版本,旧版本的 Docker 称为 docker 或者 docker-engine,使用以下命令卸载旧版本:
$ sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine
③安装依赖包
通过yum命令安装工具包
$ sudo yum install -y yum-utils
④安装Docker国内源
由于国内网络地原因,需要安装国内地源,官方源在官方注解中查看。也可以在阿里云中得到自己专属阿里源地地址。
执行下面的命令添加 yum 软件源:
$ sudo yum-config-manager —add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
$ sudo sed -i ‘s/download.docker.com/mirrors.aliyun.com\/docker-ce/g’ /etc/yum.repos.d/docker-ce.repo
#官方源
$ sudo yum-config-manager \
—add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
⑤关闭防火墙,若防火墙存在虚拟机之间通讯会存在问题。
$ firewall-cmd —permanent —zone=trusted —add-interface=docker0
$ firewall-cmd –reload
⑥ 使用脚本自动安装
在测试或开发环境中 Docker 官方为了简化安装流程,提供了一套便捷的安装脚本,CentOS 系统上可以使用这套脚本安装,另外可以通过 —mirror 选项使用国内源进行安装:国内源快一些。如果下载速度太慢可以选择国内源。
# $ curl -fsSL test.docker.com -o get-docker.sh
$ curl -fsSL get.docker.com -o get-docker.sh
$ sudo sh get-docker.sh —mirror Aliyun
# $ sudo sh get-docker.sh —mirror AzureChinaCloud
执行这个命令后,脚本就会自动的将一切准备工作做好,并且把 Docker 的稳定(stable)版本安装在系统中。
⑦启动Docker
$ sudo systemctl enable docker
$ sudo systemctl start docker
⑧建立docker用户组
默认情况下,docker 命令会使用 Unix socket 与 Docker 引擎通讯。而只有 root 用户和 docker 组的用户才可以访问 Docker 引擎的 Unix socket。出于安全考虑,一般 Linux 系统上不会直接使用 root 用户。因此,更好地做法是将需要使用 docker 的用户加入 docker 用户组。这样会使Docker指令无需添加root权限就可以使用。在Linux中频繁使用root权限是不安全的。
建立 docker 组:
$ sudo groupadd docker
将当前用户加入 docker 组:
$ sudo usermod -aG docker $USER
⑨测试 Docker 是否安装正确
运行官方提供的hello-world容器,若输出以下信息表示Docker安装成功!
$ docker run —rm hello-world
Unable to find image ‘hello-world:latest’ locally
latest: Pulling from library/hello-world
b8dfde127a29: Pull complete
Digest: sha256:308866a43596e83578c7dfa15e27a73011bdd402185a84c5cd7f32a88b501a24
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the “hello-world” image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
若能正常输出以上信息,则说明安装成功。并在三台虚拟机上安装Docker。
1.3 集群配置
⑴实验环境
| 主机 | Ip |
|---|---|
| Server1(manager) | 192.168.10.101 |
| Server2(worker1) | 192.168.10.102 |
| Server3(worker2) | 192.168.10.103 |
⑵docker swarm 集群搭建
①在管理节点server1上初始化swarm集群
[root@server1 ~]# docker swarm init
Swarm initialized: current node (qd2ul8eq2gn6cg2thdjb2ef0v) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join —token SWMTKN-1-16a2vil7z3n1oauypsofj34jezc6mkxrhrvg5e5kzijmr5sci6-8662d4zixkh79jqvtjx xb9w3x 172.25.6.1:2377
To add a manager to this swarm, run ‘docker swarm join-token manager’ and follow the instructions
②在server1结点上查看桥接的信息
[root@server1 ~]# yum install -y bridge-utils
[root@server1 ~]# brctl show
[root@server1 ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02422e71254b no
docker_gwbridge 8000.0242730c6768 no veth2adff21
③server1,server2(worker节点)加入集群
[root@server2 ~]# docker swarm join —token SWMTKN-1-16a2vil7z3n1oauypsofj34jezc6mkxrhrvg5e5kzijmr5sci6-8662d4zixkh79jqvtjxxb9w3x 172.25.6.1:2377
[root@server3 ~]# docker swarm join —token SWMTKN-1-16a2vil7z3n1oauypsofj34jezc6mkxrhrvg5e5kzijmr5sci6-8662d4zixkh79jqvtjxxb9w3x 172.25.6.1:2377
1.4 Nginx服务器配置
①启动一个nginx服务器反向代理,并将容器内部日志信息挂在到本地虚拟机。方便编程对Log日志的分析处理得到一秒的PV和连接的IP数量。
docker run -d -p 80:80
—name web
—mount type=bind,source=/root/dockershell/nginx/logs,
target=/var/log/nginx/ nginx
②修改nginx.conf文件将nginx服务器反向代理到swarm集群的tomcat服务。
1.5 Shell编写
通过编写对shell编程,我们可以得到一秒的PV,根据一秒PV去修改容器的拉伸数量。通过压力测试,在负载1000左右,单个容器会出现大量的访问失败的情况,我们根据1000作为容器访问的极限,若1000左右访问量,容器动态拉伸1,若访问数为10000容器动态拉伸10。通过实践发现,在容器动态拉伸过程中,应该使用固定步长进行拉伸。若不是固定补偿,当出现瞬间的尖峰网络,那么容器一下子就会拉伸到很高的数量。当尖峰网络只持续数秒,访问就缩减到很低的水平。频繁修改容器的副本数量。会大量消耗计算机资源,在拉伸过程中,请求会很容易丢失。这是对整个系统都是不健全的。需要排除掉这种情况的发生所以使用固定步长拉升容器的数量。<br /> 若访问的请求在一定范围内波动,频繁的修改容器的数量,也需要避免这种情况的发生。当容器数量反复横跳选择三次横跳的平均值。若接下来容器扩容的数量在平均值上下2之间徘徊,那么不修改容器的数量。保持服务的稳定运行。Shell编写的逻辑如下所示:<br />flag=1<br />while(true)<br /> do<br /> i=`awk '{print $7}' ./nginx/logs/access.log | wc -l`<br /> echo "---------------------"<br /> echo "当前的访问量"<br /> echo $i<br /> echo "---------------------"<br /> ip=`awk '{print $1}' ./nginx/logs/access.log | sort -r |uniq -c | wc -l`<br /> echo "当前连接的IP"<br /> echo $ip<br /> echo "---------------------"<br /> sleep 1<br /> j=`awk '{print $7}' ./nginx/logs/access.log|wc -l`<br /> echo "---------------------"<br /> echo "一秒以后的访问量"<br /> echo $j<br /> echo "---------------------"<br /> pv=$[j-i]<br /> echo "---------------------"<br /> echo "1秒的PV"<br /> echo $pv<br /> echo $s<br /> echo "---------------------"<br /> # 并发控制量<br /> control=1000<br /> value=`expr $pv / $control + 1`<br /> echo "待拉伸副本数"<br /> echo $value<br /> echo "---------------------"<br /> if [ $flag -lt $value ]<br /> then<br /> ((flag++))<br /> fi<br /> if [ $value -lt $flag ]<br /> then<br /> ((flag--))<br /> fi<br />echo "目前拉伸副本数"<br />echo $flag<br />docker service scale swarm_tomcat=$flag<br />
1.6 压测可视化
为了使压测数据更加直观的方式展现在我们面前,我们需要将压力测试可视化。使用市面上比较成熟的方式,将Jmeter压测脚本中添加Backend Listener的监听器,在Jmeter脚本对服务器进行压测的同时,统计TPS、相应的成功次数失败次数,并将数据传入Influxdb中,并储存起来。再有Granafa调用Influxdb的数据,并由时间作为Y轴画出折线图,直观的展现压力测试的情况做性能测试的结果。<br /> 搭建压力测试监控系统,更能直观看到压力测试成功次数,失败次数。通过压力测试发现目前算法还比较幼稚,在尖峰访问来袭的时候。容器副本数猛然提升,但当尖峰网络只持续几百毫秒,那么在单位时间内会进行两次的动态拉伸。动态拉伸很消耗系统性能,会大量出现连接失败,所以现目前对于尖峰访问,一个好的处理方式,现目前的想法就是通过特定的设计的算法,在尖峰网络来袭时平稳的提升容器副本的数量,当尖峰网络过后也是平稳的降低副本数量,并且在扩容的副本数量在小范围横跳的时候,取三次平均值,若下一次的容器拉伸的数量是平均值+-2附近徘徊,程序无需处理,姑且叫这套算法叫惰性拉伸算法。
1.6.1 Influxdb数据库安装及配置
Influxdb是一种时序数据库,这里用来存储Jmeter发送过来的数据,然后存储起来以供Grafana调用。以下使安装与配置的具体步骤:<br />①Docker安装Influx 查看并拉取镜像<br />##查看镜像<br />docker search influx<br />## 根据镜像名称拉取镜像<br />docker pull influx<br />②运行并生成容器<br />docker run --name my_influxdb -p 8086:8086 -v /home/influxdb:/var/influxdb influxdb<br />③验证容器是否运行成功<br />可以使用localhost+port(8086)如图所示表示安装成功如图6访问InfluxDB所示:<br /><br />图6 访问InfluxDB<br />④创建数据库<br />##进入Influxdb的Docker容器内<br />docker exec -it my_influxdb id /bin/bash<br />##打开influx<br />influx<br />##查看数据库并创建jmeter数据库<br />show databases;<br />create database jmeter;<br />show databases;<br />use jmeter;<br />select * from jmeter;<br />exit;<br />
1.6.2 Grafana安装配置
Grafana一种可视化监控工具,社区非常强大。拥有大量的仪表盘和解决方案。可以获取来自各类数据库中的数据。这里使用的使Influxdb数据库信息。这里用作性能测试结果的展示安装步骤如下:<br />①查看并拉取镜像<br />##查看镜像<br />docker search grafana<br />## 根据镜像名称拉取镜像<br />docker pull grafana/grafana②运行镜像并生成容器<br />③运行镜像并生成容器<br />docker run --name my_grafana -p 3000:3000 grafana/Grafana<br />④Grana配置influx<br />访问Grafana:访问网址为[http://localhost:port](http://localhost:port),用户名和密码都为admin<br />⑤添加数据源,并选择Influxdb,并配置相关数据如图导入influxDB所示:<br /><br />图7导入influxDB<br />⑥进入Grafana模板官网下载Jmeter仪表盘模板,并导入<br />进入官网[https://grafana.com/grafana/dashboards](https://grafana.com/grafana/dashboards),下载Jmeter压测仪表盘,导入并配置成功以后如图仪表盘所示。<br /><br />图8 仪表盘
1.6.3 配置Jmeter
①创建线程组,如图9所示;
图9线程组设置
②创建结果树,如图10所示;
图10结果树设置
③创建Http请求,如图11所示;
图11 HTTP请求设置
④后端监听器,如图12所示;
图12 后端监听器设置
⑤开启线程组
开启线程组以后产生数据,进入仪表盘可以查看到请求成功数,失败数,以及一系列详细的信息。如图压力测试可视化所示
图13压力测试可视化
1.7 启动tomcat Service
①应用容器资源限制本次实验为了能够明显的看到docker容器的状态变化,在压力测试之前,可以对Docker容器进行资源限制,即创建固定资源的Docker容器,主要是对容器使用的 cpu 和内存进行限制,在启动Docker容器时修改—cpuser-cpus和—cpuset-mems参数。并通过docker swarm组件实现一个service服务,并将容器的指定目录挂载到虚拟机的目录上命令如下:
docker service create
—replicas 1 -p 8081:8080
—limit-cpu 1 —limit-memory 128m
—mount
type=bind,source=/root/webapps/,
target=/usr/local/tomcat/webapps/ROOT
—name swarm_tomcat tomcat
mkdir /usr/local/tomcat/webapps/ROOT
②为了方便观察副本在各个虚拟机的情况,我们可以使用visualizer去监控实时查看集群状态首先,可以直观的看出各个service的各个副本在虚拟机中的调度情况如图6 docker swarm副本可视化。
docker service create —name=viz
—publish=8080:8081
—constraint=node.role==manager —mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock dockersamples/visualizer
二、系统测试与结果认证
2.1 测试目标及环境
2.1.1 测试目标
首先需要测试集群初始化功能、加入集群功能:表明Swarm集群可以正常运行。之后测试服务创建、负载均衡和服务暴露功能:保证用户在创建了服务之后能够在前端获取到访问服务的IP和端口。接下来测试虚拟机集群和容器集群的监控模块是否能够正常运作,最后测试弹性伸缩功能:首先运行一台三个节点的Tomcat集群和-一个Nginx服务,然后通过Jmeter压力测试工具不断访问Nginx服务,使Tomcat容器的负载增加,查.看容器集群是否能够根据负载进行弹性伸缩。
2.1.2 测试环境
物理主机测试环境
| 配置 | 规格详情 |
|---|---|
| CPU | Inter i7-8550U |
| 内存 | 16GB |
| 操作系统 | Windows |
虚拟机测试环境1
| 配置 | 规格详情 |
|---|---|
| CPU | 1 |
| 内存 | 4G |
| 硬盘 | 20GB |
| 操作系统 | Centos7.5 |
| 容器镜像 | 192.168.10.101:80 |
虚拟机测试环境2
| 配置 | 规格详情 |
|---|---|
| CPU | 1 |
| 内存 | 4G |
| 硬盘 | 20GB |
| 操作系统 | Centos7.5 |
| 容器镜像 | 192.168.10.102:80 |
虚拟机测试环境3
| 配置 | 规格详情 |
|---|---|
| CPU | 1 |
| 内存 | 4G |
| 硬盘 | 20GB |
| 操作系统 | Centos7.5 |
| 容器镜像 | 192.168.10.103:80 |
2.2 弹性伸缩功能
2.2.1 弹性伸缩功能测试
①创建服务,并将Tomcat服务的首页目录绑定到本地。因为docker容器不具备持久化能力,若容器关闭,数据就丢失。需要将首页目录绑定到本地虚拟机。在模拟用户请求,在被swarm分流的过程中。看到底是那个虚拟机的容器相应的该请求。
docker service create
—replicas 1 -p 8081:8080
—limit-cpu 1 —limit-memory 128m
—mount
type=bind,source=/root/webapps/,
target=/usr/local/tomcat/webapps/ROOT
—name swarm_tomcat tomcat
mkdir /usr/local/tomcat/webapps/ROOT
②通过游览器访问,测试是否轮询成功如图14、图15、图16所示:
图14访问得到worker2
图15访问得到master
图16 访问得到worker2
③开启Docker.sh,如图所示:
[root@master dockershell]# bash docker.sh
当前的访问量=184006
当前连接的IP=1
一秒以后的访问量=184006
1秒的PV=0
待拉伸副本数=1
目前拉伸副本数=1
swarm_tomcat scaled to 1
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
④开启Jmeter进行压力测试
开启压力测试以后,Nginx代理服务器访问数量开始加大。容器开始扩容,拉伸以应对高并发的出现。并且采用的是固定的步长进行拉升。
当前的访问量=200859
当前连接的IP=1
一秒以后的访问量=201663
1秒的PV=804
待拉伸副本数=9
目前拉伸副本数=4
swarm_tomcat scaled to 4
overall progress: 4 out of 4 tasks
1/4: running [==================================================>]
2/4: running [==================================================>]
3/4: running [==================================================>]
4/4: running [==================================================>]
⑤减少Jmeter压力测试并发量
将并发数减少到100,发现容器开始缩减,达到节省资源的目的。
当前的访问量=201665
当前连接的IP=1
一秒以后的访问量=201754
1秒的PV=89
待拉伸副本数=1
目前拉伸副本数=1
swarm_tomcat scaled to 1
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
2.3 测试总结
5.1至5.2章节的相关测试结果表明,集群创建、服务创建、服务发现与负载均衡以及监控模块的各个功能都可以正常使用。在容器高负载的时候,容器能以固定步长进行拉伸,而当压力测试请求较低的时候,能以固定步长进行缩减。压力测试可视话工具也正常运行。<br /> 我们验证了本文的核心功能一一弹性 伸缩与负载均衡功能,测试结果显示弹性负载均衡功能正常。最终证明试验结果符合预期。
三、总结
通过 Docker容器和传统虚拟机的比较,发现Docker容器启动速度快、系统开销小的特点非常适合用在集群弹性伸缩的场景中,替换虚拟机的笨重操作。本文通过Nginx、Docker swarm和Tomcat组件,基于Docker容器构建的动态负载均衡弹性伸缩系统,既发挥了Docker容器的优势,也保证了系统的稳定、可靠运行。实验结果表明,当系统面临突发式请求时,系统通过响应式伸缩,实现负载均衡。基于Docker监控数据进行预处理分析,实施预测式弹性伸缩,实现智能运维。<br /> 弹性负载均衡功能在各个云平台中只是服务质量和用户体验提升的手段,但是在实际操作过程中,需要各个模块的配合。其中最为重要的是监控模块和服务发现与负载均衡模块,监控数据的准确性、时效性,监控指标的选择、时序数据库的相关设计直接影响到弹性伸缩功能的质量和效果。本文在选择编程语言时充分考虑到了监控系统所需要的并行性,Go语言的gorutine有效的解决了如何在短时间内迅速遍历集群内所有容器和虚拟机,以及监控数据的请求与返回需要等待一小段时间的问题。本系统将每一次监控数据的请求都独立放置在一个gorutine中,不需要顺序的等待每一一个监控数据的返回,可以在很短的时间内获取到所有的监控数据,这是本文和本功能能够顺利实现的重要原因。<br /> 实现的弹性伸缩与负载均衡功能以提升服务质量、减少资源浪费以及为用户节省使用成本为目标。在实际的设计和实现中我们发现,通常情况下,用户的应用服务都不是单核应用,多核应用在负载增加时往往能够占完整个虚拟机的全部核心。虽然Docker在系统层面通过Cgroups机制提供了限制CPU核心数、CPU占用率、内存使用量的相关参数,但是该参数所限制的CPU占用率是一个权值,指容器最大不会使用超过该百分比值的CPU时间片,并没有对CPU时间片的下限做保证,也就是说当整个虚拟机的负载很大且运行的容器很多时,每个容器能够分到的时间片会很少,这时在原先的虚拟机集群对容器规模进行扩充不会对用户体验和响应时间有提升,相反由于调度的容器增多,更多的资源被浪费在了进程切换的工作中,这时只有提升集群的规模才能够解决问题。但是Docker Swarm集群的服务在部署之后,不会进行重新调度,因此,原先运行在高负载虚拟机.上的容器不会自动结束生命并在负载低的虚拟机上重启,本文通过利用服务的滚动更新机制将服务的容器依次重启,重启后的容器按照均摊(spread)的策略分配到所有的虚拟机上,这种方式虽然解决了问题但是希望后续研究.Docker Swarm的同学能够对其Swarm的容器调度策略进行二次开发,使其能够自动识别集群规模发生的变化并对现有容器做更加细致的重新规划和调度。 DockerSwarmMode并没有提供可选的容器的调度策略,比如优先占满-一个虚拟机的调度模式和均摊容器数量使每个虚拟机负载均衡的调度模式。如果Docker能够源生提供这两种调度模式,便可以在此之,上对虚拟机的资源进行更全面的利用和规划,本文因为时间有限,没能够在Swarm集群的调度优化算法。<br />优化方面做更深入的研究。希望后续的同学能够关注DockerSwarmmode的相关<br />动态,或是自己设计基于HTTP RESTful API的第三方打分与容器调度策略。<br /> Docker swarm是一个轻量化小型的容器编排管理工具,适合中小型公司业务逻辑简单的企业。若是有复杂的需求则需要使用K8S企业级编排管理工具。

若有收获,就点个赞吧
0 人点赞
