1.fuzzy搜索的概念应用
fuzzy query是一种模糊索索,其原理是查询词与词之间出存在的相似度,在计算两个单词之间的相似度之前就需要了解Levenshtein Edit Distance(做莱文斯坦距离),它是编辑距离的一种。指两个字串之间,由一个字符串转成另一个字符串所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
例如,单词 “ski”变为 “sky”,的编辑距离为 1,这里使用“y”替换掉了“i”。
PUT fuzzyindex/_doc/1{"content": "I like blue sky"}
GET fuzzyindex/_search{"query": {"match": {"content": {"query": "ski","fuzziness": 1}}}}
当上面的请求发出以后,由于ski与sky之间存在一个编辑长度,因此可以匹配到“I like blue sky”。
{"took" : 22,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.19178805,"hits" : [{"_index" : "fuzzyindex","_type" : "_doc","_id" : "1","_score" : 0.19178805,"_source" : {"content" : "I like blue sky"}}]}}
2.如何设置fuzziness属性
前面通过一个简单的例子让我们对Fuzzy query 有所了解,其中fuzziness属性的配置是重中之重,这里我们再用几个例子展开说明。
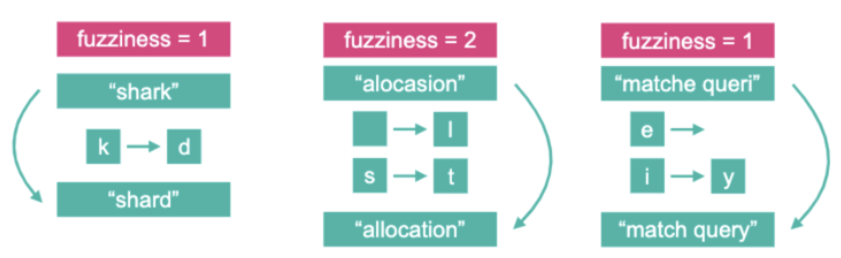
如图所示,这里列举了几种fuzziness配置的场景。
- Fuzziness=1,“shark”和“shard”之间有一个字符存在差异就是“k”和“d”,它们之间是替换关系。Fuzziness=1差距是1,两个字符串可以匹配。
- Fuzziness=2,“allocation”和“allocation”之间存在两个字符的差异,“alocasion”比“allocation”少了一个“l”,同时“allocation”用“t”把“alocasion”中的“s”替换掉了。Fuzziness=2差距是2,两个字符串可以匹配。
- Fuzziness=1,“matche queri”和“match query”存在两处差异,Fuzziness=2差距是2,两个字符串不能匹配。
在fuzziness参数还有一种配置方法是ATUO,它会根据词的长度计算编辑距离,形式为AUTO:[low],[high],两个参数分别表示短距离参数和长距离参数。如果没有指定,默认值是 AUTO:3,6 。
当短距离参数和长距离参数表示为 3和6 的时候,其要传达的意思如下:
单词长度为 0 到 2 之间时,fuzziness=0,表示必须要精确匹配。
单词长度 3 到 5 个字母时,fuzziness=1。
单词长度大于 5 个字母时,fuzziness=2。
最佳实践: fuzziness 在绝大多数场合都应该设置成 AUTO。

若有收获,就点个赞吧
0 人点赞
