写在前面:本文参考了LeetCode的题解和labuladong的题解,leetcode的动态规划题解是自底向上的动态规划方式来理解问题,而labuladong提供了自顶向下的递归的方式,推荐先看labuladong的自顶向下的思路,然后再看leetCode的动态规划思路。
题目描述

LeetCode题解
想法
编辑距离算法被数据科学家广泛应用,是用作机器翻译和语音识别评价标准的基本算法。
最直观的方法是暴力检查所有可能的编辑方法,取最短的一个。所有可能的编辑方法达到指数级,但我们不需要进行这么多计算,因为我们只需要找到距离最短的序列而不是所有可能的序列。
方法一:动态规划
思路和算法
我们可以对任意一个单词进行三种操作:
- 插入一个字符;
- 删除一个字符;
- 替换一个字符。
题目给定了两个单词,设为 A 和 B,这样我们就能够六种操作方法。
但我们可以发现,如果我们有单词 A 和单词 B:
对单词 A 删除一个字符和对单词 B 插入一个字符是等价的。例如当单词 A 为 doge,单词 B 为 dog 时,我们既可以删除单词 A 的最后一个字符 e,得到相同的 dog,也可以在单词 B 末尾添加一个字符 e,得到相同的 doge;
同理,对单词 B 删除一个字符和对单词 A 插入一个字符也是等价的;
对单词 A 替换一个字符和对单词 B 替换一个字符是等价的。例如当单词 A 为 bat,单词 B 为 cat 时,我们修改单词 A 的第一个字母 b -> c,和修改单词 B 的第一个字母 c -> b 是等价的。
这样以来,本质不同的操作实际上只有三种:
- 在单词 A 中插入一个字符;
- 在单词 B 中插入一个字符;
- 修改单词 A 的一个字符。
最优子问题这样以来,我们就可以把原问题转化为规模较小的子问题。我们用 A = horse,B = ros作为例子,来看一看是如何把这个问题转化为规模较小的若干子问题的。
- 在单词
A中插入一个字符:如果我们知道horse到ro的编辑距离为a,那么显然horse到ros的编辑距离不会超过a + 1。这是因为我们可以在a次操作后将horse和ro变为相同的字符串,只需要额外的 次操作,在单词
次操作,在单词 A的末尾添加字符s,就能在a + 1次操作后将horse和ro变为相同的字符串; - 在单词
B中插入一个字符:如果我们知道hors到ros的编辑距离为b,那么显然horse到ros的编辑距离不会超过b + 1,原因同上; - 修改单词
A的一个字符:如果我们知道hors到ro的编辑距离为c,那么显然horse到ros的编辑距离不会超过c + 1,原因同上。
那么从 horse 变成 ros 的编辑距离应该为  。
。
注意:为什么我们总是在单词 A 和 B 的末尾插入或者修改字符,能不能在其它的地方进行操作呢?答案是可以的,但是我们知道,操作的顺序是不影响最终的结果的。例如对于单词 cat,我们希望在 c 和 a之间添加字符 d 并且将字符 t 修改为字符 b,那么这两个操作无论为什么顺序,都会得到最终的结果 cdab。
BASE CASE你可能觉得 horse 到 ro 这个问题也很难解决。但是没关系,我们可以继续用上面的方法拆分这个问题,对于这个问题拆分出来的所有子问题,我们也可以继续拆分,直到:
- 字符串
A为空,如从 转换到ro,显然编辑距离为字符串B的长度,这里是2; - 字符串
B为空,如从horse转换到 ,显然编辑距离为字符串A的长度,这里是5。
因此,我们就可以使用动态规划来解决这个问题了。我们用 D[i][j] 表示 A 的前  个字母和
个字母和 B 的前  个字母之间的编辑距离。
个字母之间的编辑距离。
如上所述,当我们获得 D[i][j-1],D[i-1][j] 和 D[i-1][j-1] 的值之后就可以计算出D[i][j]。
D[i][j-1]为A的前个字符和
B的前 个字符编辑距离的子问题。即对于
个字符编辑距离的子问题。即对于 B的第 个字符,我们在 A的末尾添加了一个相同的字符,那么D[i][j]最小可以为D[i][j-1] + 1;D[i-1][j]为A的前 个字符和
个字符和 B的前 个字符编辑距离的子问题。即对于 A的第 个字符,我们在
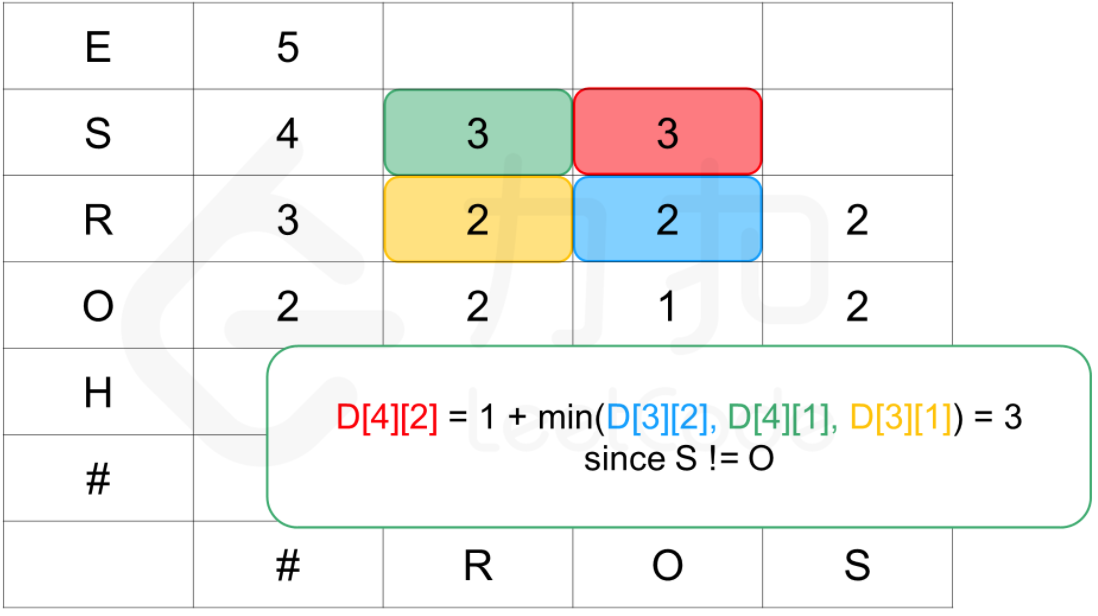
个字符,我们在 B的末尾添加了一个相同的字符,那么D[i][j]最小可以为D[i-1][j] + 1;D[i-1][j-1]为A前 个字符和 B 的前 个字符编辑距离的子问题。即对于 B 的第 个字符,我们修改 A的第 个字符使它们相同,那么 D[i][j]最小可以为D[i-1][j-1] + 1。特别地,如果A的第 个字符和 B的第个字符原本就相同,那么我们实际上不需要进行修改操作。在这种情况下,D[i][j]最小可以为D[i-1][j-1]。
那么我们可以写出如下的状态转移方程:
- 若
A和B的最后一个字母相同:

- 若
A和B的最后一个字母不同:

所以每一步结果都将基于上一步的计算结果,示意如下:
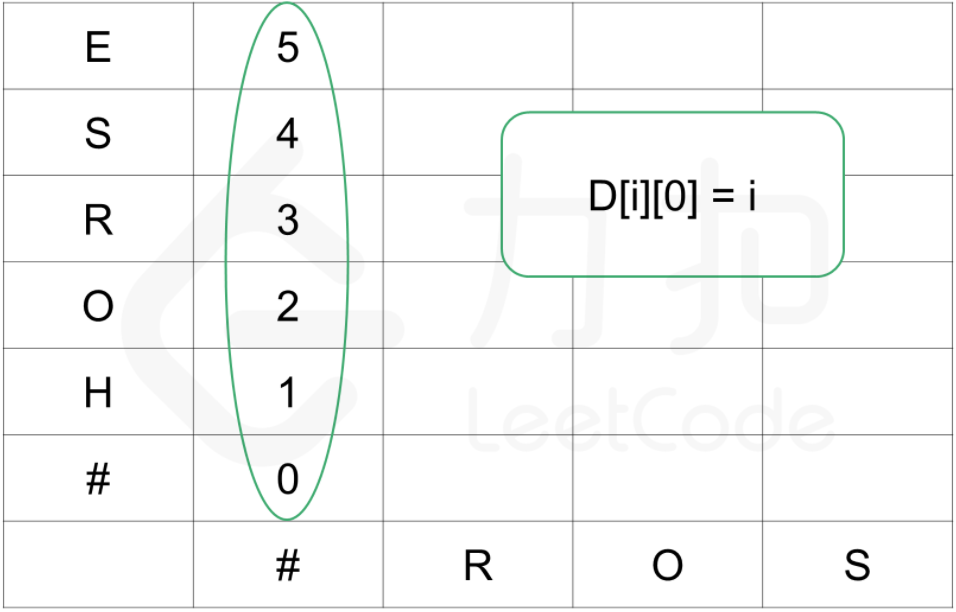
对于边界情况,一个空串和一个非空串的编辑距离为 D[i][0] = i 和 D[0][j] = j,D[i][0] 相当于对 word1 执行 次删除操作,D[0][j] 相当于对 word1执行 次插入操作。
综上我们得到了算法的全部流程。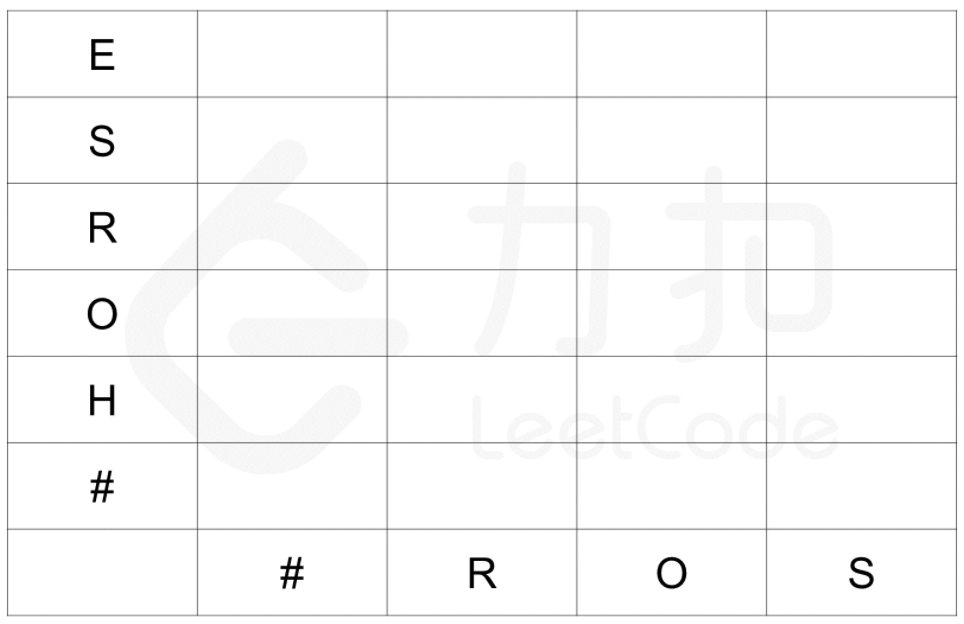
















class Solution {public int minDistance(String word1, String word2) {int n = word1.length();int m = word2.length();// 有一个字符串为空串if (n * m == 0)return n + m;// DP 数组int [][] D = new int[n + 1][m + 1];// 边界状态初始化for (int i = 0; i < n + 1; i++) {D[i][0] = i;}for (int j = 0; j < m + 1; j++) {D[0][j] = j;}// 计算所有 DP 值for (int i = 1; i < n + 1; i++) {for (int j = 1; j < m + 1; j++) {int left = D[i - 1][j] + 1;int down = D[i][j - 1] + 1;int left_down = D[i - 1][j - 1];if (word1.charAt(i - 1) != word2.charAt(j - 1))left_down += 1;D[i][j] = Math.min(left, Math.min(down, left_down));}}return D[n][m];}}
时间复杂度 : ,其中
,其中  为
为 word1 的长度, 为
为 word2 的长度。
空间复杂度 :,我们需要大小为 的 D 数组来记录状态值。
作者:LeetCode-Solution 链接:https://leetcode-cn.com/problems/edit-distance/solution/bian-ji-ju-chi-by-leetcode-solution/
Labuladong题解思路(推荐思路)
思路
编辑距离问题就是给我们两个字符串 s1 和 s2,只能用三种操作,让我们把 s1 变成 s2,求最少的操作数。需要明确的是,不管是把 s1 变成 s2 还是反过来,结果都是一样的,所以后文就以 s1 变成 s2 举例。
解决两个字符串的动态规划问题,一般都是用两个指针 i,j 分别指向两个字符串的最后,然后一步步往前走,缩小问题的规模。
设两个字符串分别为 “rad” 和 “apple”,为了把 s1 变成 s2,算法会这样进行:
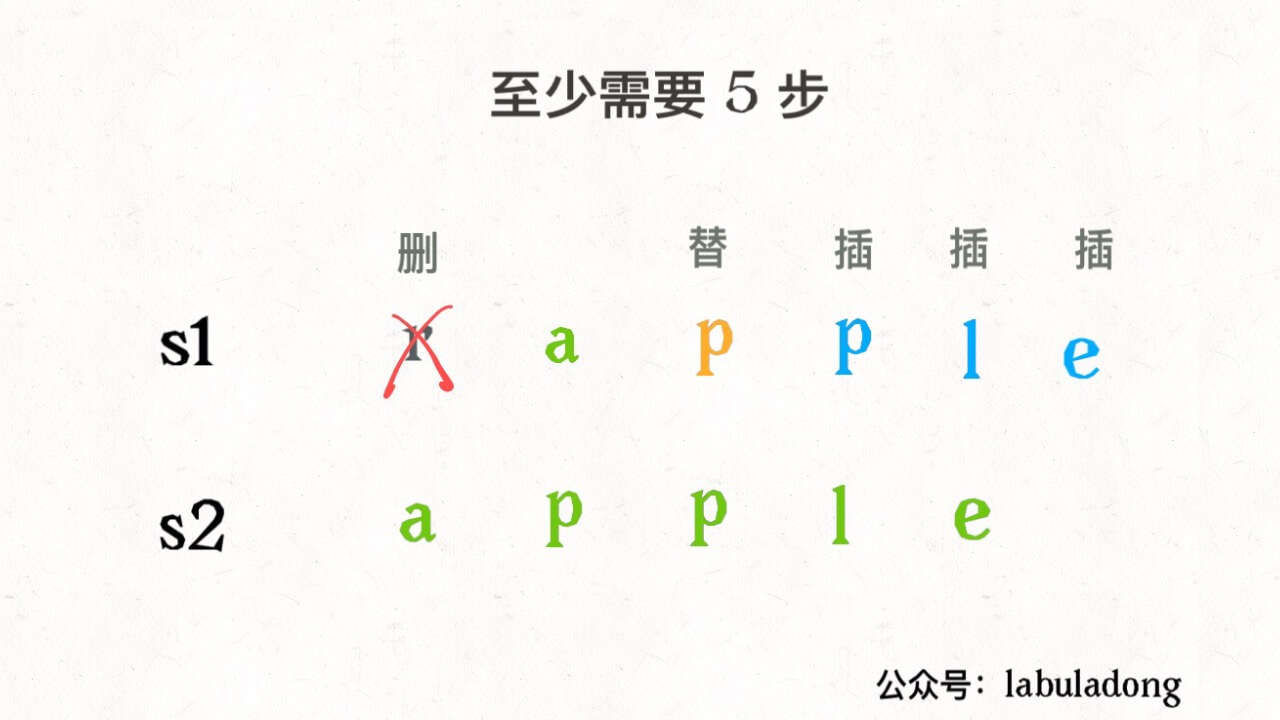
请记住这个 GIF 过程,这样就能算出编辑距离。关键在于如何做出正确的操作,稍后会讲。
根据上面的 GIF,可以发现操作不只有三个,其实还有第四个操作,就是什么都不要做(skip)。比如这个情况: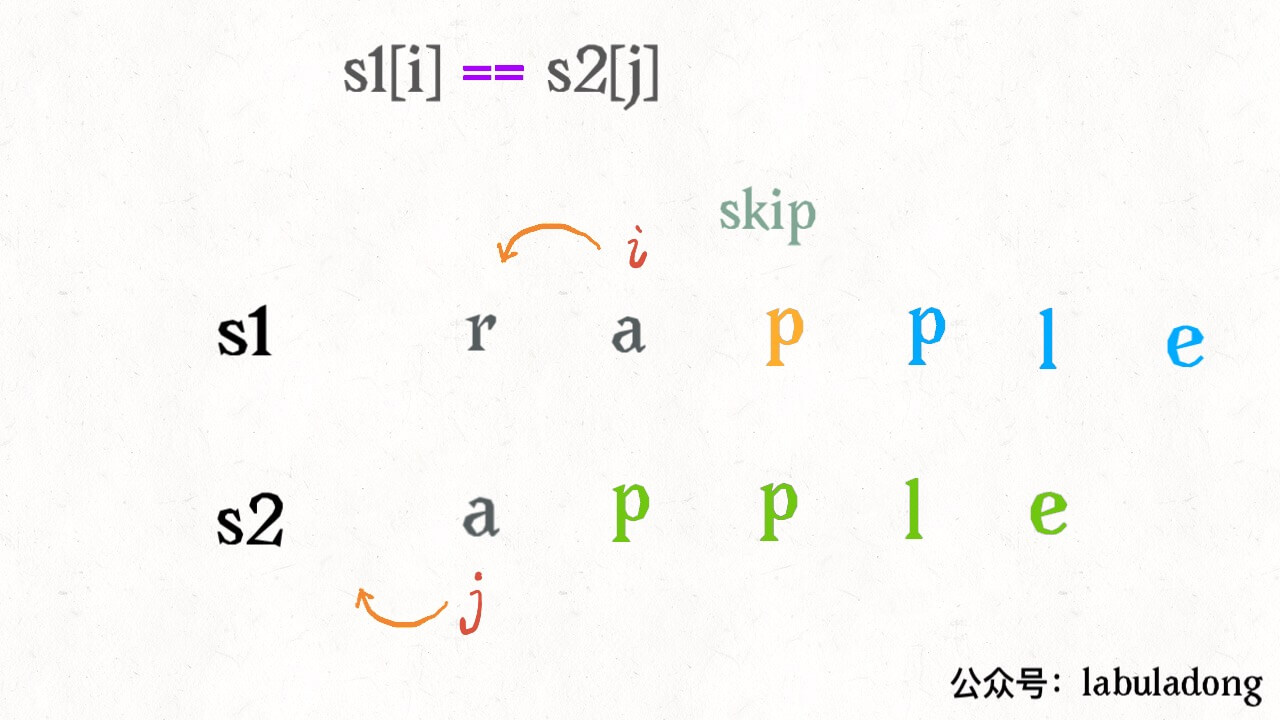
因为这两个字符本来就相同,为了使编辑距离最小,显然不应该对它们有任何操作,直接往前移动 i,j 即可。
还有一个很容易处理的情况,就是 j 走完 s2 时,如果 i 还没走完 s1,那么只能用删除操作把 s1 缩短为 s2。比如这个情况: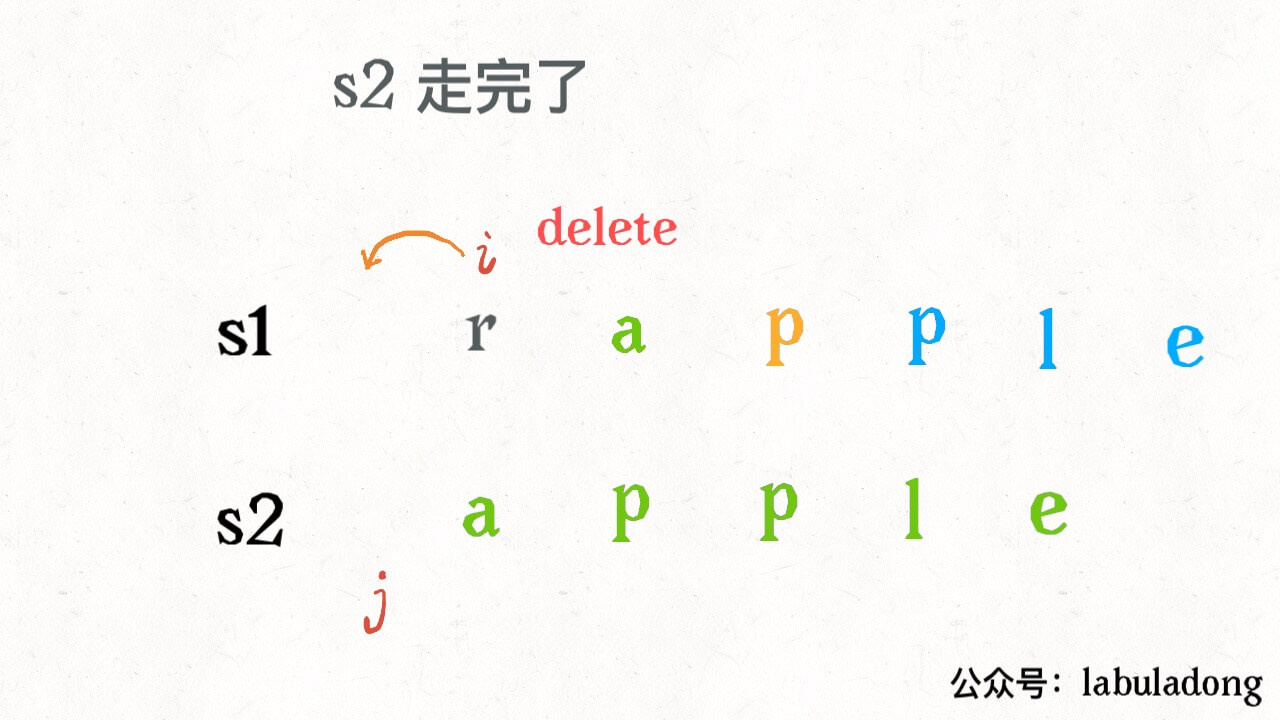
类似的,如果 i 走完 s1 时 j 还没走完了 s2,那就只能用插入操作把 s2 剩下的字符全部插入 s1。等会会看到,这两种情况就是算法的 base case。
代码思路
先梳理一下之前的思路:
base case 是 i 走完 s1 或 j 走完 s2,可以直接返回另一个字符串剩下的长度。
对于每对儿字符 s1[i] 和 s2[j],可以有四种操作:
if s1[i] == s2[j]:啥都别做(skip)i, j 同时向前移动else:三选一:插入(insert)删除(delete)替换(replace)
有这个框架,问题就已经解决了。读者也许会问,这个「三选一」到底该怎么选择呢?很简单,全试一遍,哪个操作最后得到的编辑距离最小,就选谁。这里需要递归技巧,理解需要点技巧,先看下代码:
def minDistance(s1, s2) -> int:def dp(i, j):# base caseif i == -1: return j + 1if j == -1: return i + 1if s1[i] == s2[j]:return dp(i - 1, j - 1) # 啥都不做else:return min(dp(i, j - 1) + 1, # 插入dp(i - 1, j) + 1, # 删除dp(i - 1, j - 1) + 1 # 替换)# i,j 初始化指向最后一个索引return dp(len(s1) - 1, len(s2) - 1)
下面来详细解释一下这段递归代码,base case 应该不用解释了,主要解释一下递归部分。
都说递归代码的可解释性很好,这是有道理的,只要理解函数的定义,就能很清楚地理解算法的逻辑。我们这里 dp(i, j)函数的定义是这样的:
def dp(i, j) -> int# 返回 s1[0..i] 和 s2[0..j] 的最小编辑距离
记住这个定义之后,先来看这段代码:
if s1[i] == s2[j]:return dp(i - 1, j - 1) # 啥都不做# 解释:# 本来就相等,不需要任何操作# s1[0..i] 和 s2[0..j] 的最小编辑距离等于# s1[0..i-1] 和 s2[0..j-1] 的最小编辑距离# 也就是说 dp(i, j) 等于 dp(i-1, j-1)
如果 s1[i]!=s2[j],就要对三个操作递归了,稍微需要点思考:
dp(i, j - 1) + 1, # 插入# 解释:# 我直接在 s1[i] 插入一个和 s2[j] 一样的字符# 那么 s2[j] 就被匹配了,前移 j,继续跟 i 对比# 别忘了操作数加一

注:在前面的leetcode题解中,在s1末尾删除相当于在s2的末尾插入
dp(i - 1, j) + 1, # 删除# 解释:# 我直接把 s[i] 这个字符删掉# 前移 i,继续跟 j 对比# 操作数加一

dp(i - 1, j - 1) + 1 # 替换# 解释:# 我直接把 s1[i] 替换成 s2[j],这样它俩就匹配了# 同时前移 i,j 继续对比# 操作数加一

对于子问题 dp(i-1, j-1),如何通过原问题 dp(i, j) 得到呢?有不止一条路径,比如 dp(i, j) -> #1 和 dp(i, j) -> #2 -> #3。一旦发现一条重复路径,就说明存在巨量重复路径,也就是重叠子问题。
def dp(i, j):dp(i - 1, j - 1) #1dp(i, j - 1) #2dp(i - 1, j) #3
动态规划
labuladong也使用了动态规划,但是LeetCode写得更好,这里就不继续搬运了。
https://labuladong.gitbook.io/algo/dong-tai-gui-hua-xi-lie/bian-ji-ju-li

若有收获,就点个赞吧
0 人点赞
