前言
随着企业应用数据量的增加,系统变得越来越慢,性能优化变得越来越重要。 其中尤其以数据库的优化,是重中之重。
本文以作者最熟悉的SQL Server为例,但是所说的方法在其他关系型数据库中也同样适用。
使用工具分析
现代数据库通常都包含查询分析工具,它会辅助你快速找到那些消耗大量资源的查询语句。
以Azure SQL为例,它提供了一个叫做“Query Performance Insight”的工具。它可以帮助我们直观的了解当前数据库按时间线查看数据库的使用状态。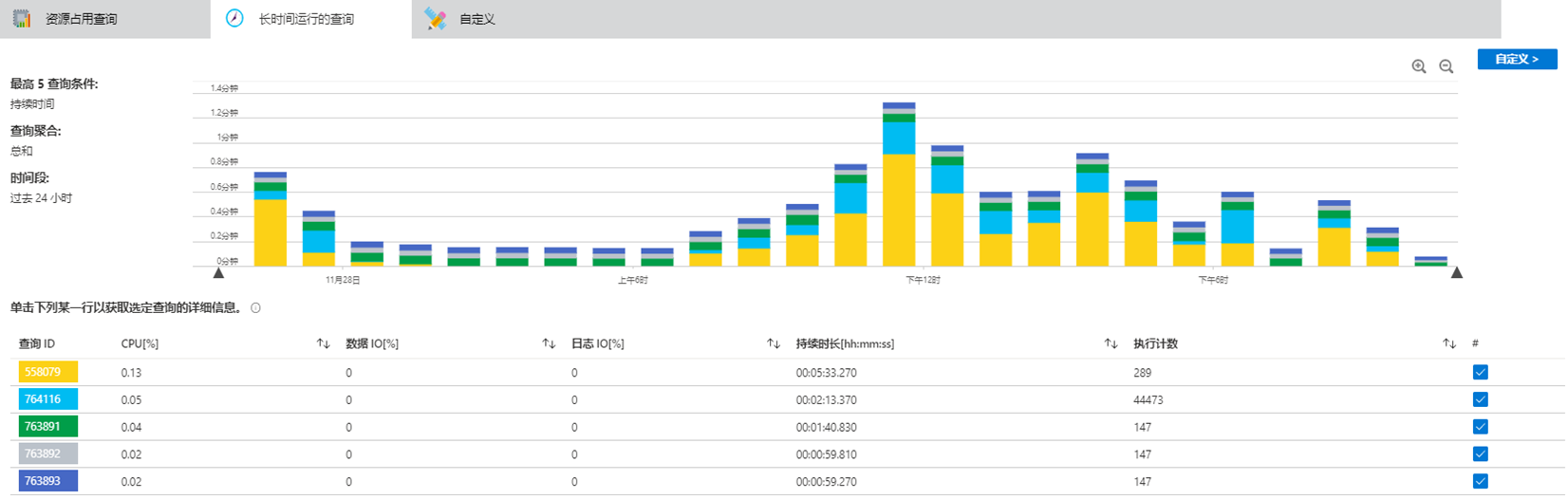
同时,我们也可以使用“长时间运行查询”来帮助我们定位那些占用资源较大、运行比较长的查询,以此来进一步对该语句进行优化。
查看执行计划
在前面提到找到性能慢的SQL语句后,就要尝试优化SQL语句或者添加索引。通过查看执行计划是最主要的方式。
什么是执行计划?执行计划是查询优化器对我们提交的SQL语句的执行结果,它可以告诉我们数据库查询是怎么执行的,从而帮助我们排除故障,进行针对性的优化。
操作方法如下:
把我们要执行的查询语句复制到SSMS中,然后点击显示预估执行计划,或者实际执行计划。如下图: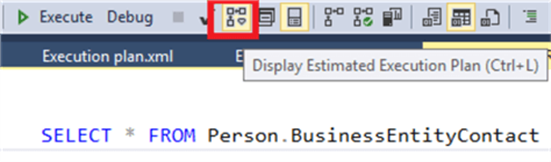
执行计划有3种显示形式。
- XML Format
- Text Format
- Graphical Format
其中图形格式是最最广泛使用的方式。下图是一个图形计划的例子。
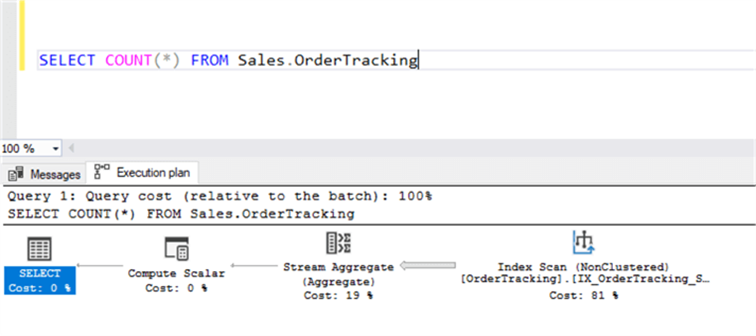
从这个图中可以得到3个有用的信息:
- 哪些执行步骤花费的时间成本比较高。很显然最右边的索引扫描花费的时间比较多。
- 哪些执行步骤产生的数据量比较多。每个步骤之间都是由箭头链接,箭头线越粗表示的数据量越大;很明显在经过aggregate之后数据量大幅度降低了。
- 每一步执行了什么样的动作。
从图中可以看出,先是执行了索引扫描,把所有的数据获取出来,耗时占81%。然后把数据传递给stream aggregate操作。
流聚合是一个分组运算符,它接收多行并执行输入的分组并在一行中提供输出。
接下来,将这一行传递给计算Scaler操作,执行count计数操作。
最后select操作,把结果返回。
建立索引
在数据库查询性能中,索引绝对是影响性能最大的因素。
什么是索引?索引相当于一本字典的目录,如果要查找某个词,我们不需要把整本字典全部查阅完毕,只需要先在目录中找到对应的词即可。
索引分为聚簇索引和非聚簇索引。
聚簇索引,他的叶级不仅仅包含索引键,还包括数据。所以,一个表只能有一个聚簇索引,且整个索引是最为重要的。
通常聚簇索引是一个表的主键。它是唯一的,静态的,自增长的。我一般使用GUID作为主键这样不仅仅可以保证它在本表中是唯一的,在其他表中也是唯一的。并且使用数据库自带的默认值,而不是使用前端生成的GUID插入,使用NEWSEQUENTIALID()函数来设置该列的默认值,而不是NEWID()。
非聚簇索引,非聚簇索引通常不是必须的,它的存储结构也与实际的数据存储无关。一个表可以有多个非聚簇索引。通常它在表的外键、以及经常出现在where子句中的列上需要增加非聚簇索引。
索引不是越多越好,一定要在该用索引的地方使用索引。有了索引后,每次增删改数据时候需要更新索引。如果这个索引用到的话,反而不如不建索引。
创建索引的语法如下:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEXindex_nameON<object> ( column_name [ ASC | DESC ][ ,...n ] )[ WITH <backward_compatible_index_option> [ ,...n ] ][ ON { filegroup_name | "default" } ]
数据库的日常维护
数据库也需要像房间一样,需要定期去整理衣物,清点物品个数,清除垃圾等工作。这样,找东西的时候可以更快速的在屋内找到该物品。
因为数据库维护也需要占用大量的CPU、内存等资源,所以我一般设置数据库维护计划在夜间没有人使用的情况下进行。
重建索引
重建索引可以很好的清除碎片,可以使索引达到平衡。
重建索引的语句
ALTER INDEX { index_name | ALL } ON <object>{REBUILD {[ PARTITION = ALL ] [ WITH ( <rebuild_index_option> [ ,...n ] ) ]| [ PARTITION = partition_number [ WITH ( <single_partition_rebuild_index_option> ) [ ,...n ] ]}| DISABLE| REORGANIZE [ PARTITION = partition_number ] [ WITH ( <reorganize_option> ) ]| SET ( <set_index_option> [ ,...n ] )| RESUME [WITH (<resumable_index_options>,[...n])]| PAUSE| ABORT}
如果你能保证没有应用程序使用,则直接删除索引后重建,可以效果更佳。
语句如下:
drop index ****;Create index **** on ***
更新统计信息
统计信息对于查询优化器起到很关键的指导作用,特别当夜间批量操作大量执行结束后,统计信息可能不是特别准确,所以在索引重建完后,也需要重新更新下统计信息以达到能正确指引查询优化器的作用。
语句如下:
UPDATE STATISTICS 表名
善用 WITH(NOLOCK)
SQL Server中有很多种锁,共享锁、更新锁、排它锁、意向锁等等,通常增删改查都会产生一些锁。如果要很好的实现高性能一定要理解各种锁的优劣性。
在这里介绍一种最最常用也最容易理解的方法 WITH(NOLOCK)。例子如下:
SELECT * FROM [Person].[Person] WITH (NOLOCK)
在数据库中,通常在查询过程中会存在增删改查,如其字面意思,nolock就是说从表中读取数据时候,会略任何锁。
有什么好处吗?因为它不会被任何其他操作所阻塞,查询速度、内存占用、并发量都能得到大幅度提升。
有什么坏处吗?唯一的坏处是,可能会带来脏读,即读到的数据。
因此WITH(NOLOCK)也不是所有的地方都可以使用。以我的经验,通常用在报表、查询历史等查询中,因为这些操作记录一般都是批量新增或者删除, 不太会频繁增删改。
善用 SET NOCOUNT
通常我们在存储过程的顶部加上这个设置
SET NOCOUNT ON
如果存储过程中包含的一些语句并不返回许多实际的数据,则该设置由于大量减少了网络流量,因此可显著提高性能。
反范式设计
通常,我们设计数据库的时候都是根据第三范式来设计的,说就是指表中的所有数据元素不但要能唯一地被主关键字所标识, 而且它们之间还必须相互独立,不存在其他的关系。第三范式有很多好处,比如可以避免增删改查的异常,保证数据的一致性、避免冗余等。
但是这么做的坏处是很多时候查询性能会比较差。
举个例子,通常企业内部软件都会涉及到区域划分,不管是内部的组织机构还是外部客户。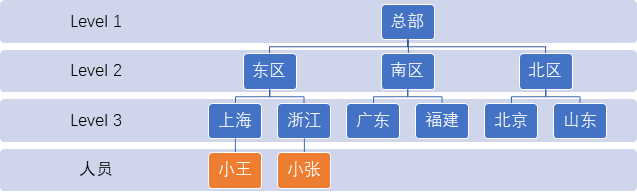
至少我们会设计三层及以上组织结构。如果按照第三范式的标准,我们的表机构应该是这样的:
| 部门**Id(OrgId)** | 部门编号**(OrgNo)** | 部门名称**(OrgName)** | 上级单位**(ParentOrgId)** |
|---|---|---|---|
| guid | 1000 | 总部 | 空 |
| guid | 1100 | 东区 | 总部guid |
| guid | 1200 | 南区 | 总部guid |
| guid | 1300 | 北区 | 总部guid |
| guid | 1110 | 上海 | 东区guid |
| guid | 1120 | 浙江 | 东区guid |
| ……. |
| 用户名 | 部门 |
|---|---|
| ** | 上海Id |
| ** | 浙江Id |
| … | |
| … |
显然这么设计的话数据没有任何冗余,增删改也不会出现脏数据。
但是当需要查询某个人所在Level 2的部门时候,查询就会特别麻烦。
有没有什么好办法呢? 就是反范式设计。
通常组织机构的调整频率是非常小,1年可能也就1,2次。基于数据不会大变的前提,我们可以进行如下设计改造。
| 列 |
|---|
| 部门Id |
| 部门编号(OrgNo) |
| 部门名称(OrgName) |
| 上级单位(ParentOrgId) |
| Level 1 部门Id |
| Level 1 部门编号 |
| Level 1 部门名称 |
| Level 2 部门Id |
| Level 2 部门编号 |
| Level 2 部门名称 |
| Level 3 部门Id |
| Level 3 部门编号 |
| Level 3 部门名称 |
这样每次更新完组织架构变动后,执行一次批量“更新组织机构信息”脚本, 也可以达到数据一致性的结果。查询语句也变得更简单高效。
SELECT Level 2部门编号, Level 2部门名称FROM OrgTableJOIN UserON OrgTable.OrgId = User.OrgId AND User.Name = '小李'

若有收获,就点个赞吧
0 人点赞
