一.mixins泛型视图类
一般自定义视图类在使用mixins泛型类时也就是继承该类,还需要再继承一个GenericAPIView类搭配使用
1.1mixins源码介绍:
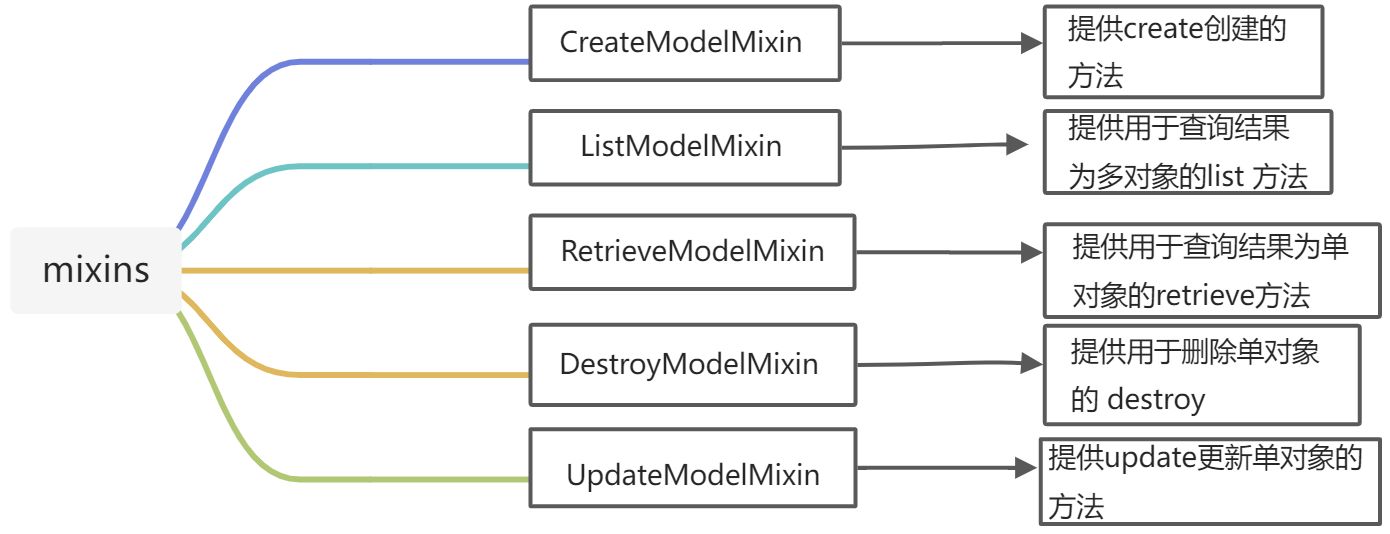
1.1.1 CreateModelMixin源码
class CreateModelMixin:"""Create a model instance."""def create(self, request, *args, **kwargs):#get_serializer方法得到属性序列化类serializer_class()视图函数中你需要指定该属性#serializer_class=你自定义的序列化类,这里没有使用many参数,不用一般默认False,#也就是适合单对象的序列化serializer = self.get_serializer(data=request.data)#raise_exception=True验证当有异常时抛出异常serializer.is_valid(raise_exception=True)#调用下方perform_create方法进行保存对象self.perform_create(serializer)headers = self.get_success_headers(serializer.data)return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)def perform_create(self, serializer):serializer.save()def get_success_headers(self, data):try:return {'Location': str(data[api_settings.URL_FIELD_NAME])}except (TypeError, KeyError):return {}
1.1.2 ListModelMixin源码
class ListModelMixin:"""List a queryset."""def list(self, request, *args, **kwargs):#get_queryset在GenericAPIView类,返回的是GenericAPIView视图类中queryset属性#filter_queryset()得到的是后端过滤后的查询集(搭配过滤器使用)后面会讲queryset = self.filter_queryset(self.get_queryset())#paginate_queryset返回结果的单个页面,如果分页被禁用,则返回“None”。page = self.paginate_queryset(queryset)if page is not None:serializer = self.get_serializer(page, many=True)return self.get_paginated_response(serializer.data)serializer = self.get_serializer(queryset, many=True)return Response(serializer.data)
1.1.3 RetrieveModelMixin源码
class RetrieveModelMixin:"""Retrieve a model instance."""#该方法使用场景为url位置参数:类似于url(r'^books/(?P<pk>\d+)/$'def retrieve(self, request, *args, **kwargs):#GenericAPIView类中的get_object通过url位置参数返回一个单对象instance = self.get_object()serializer = self.get_serializer(instance)return Response(serializer.data)
1.1.4 UpdateModelMixin源码
class UpdateModelMixin:"""单实例更新:1. 获取 kwargs 字典中 partial 的值,如果没有,则返回False,有,则返回值2. 获取单个对象3. 通过序列化,获取单个对象的序列化对象4. 判断序列化对象的有效性5. 更新数据"""def update(self, request, *args, **kwargs):partial = kwargs.pop('partial', False)instance = self.get_object()serializer = self.get_serializer(instance, data=request.data, partial=partial)serializer.is_valid(raise_exception=True)self.perform_update(serializer)if getattr(instance, '_prefetched_objects_cache', None):# If 'prefetch_related' has been applied to a queryset, we need to# forcibly invalidate the prefetch cache on the instance.instance._prefetched_objects_cache = {}return Response(serializer.data)def perform_update(self, serializer):serializer.save()def partial_update(self, request, *args, **kwargs):#这里给了一个partial为Ture,然后调用update()kwargs['partial'] = Truereturn self.update(request, *args, **kwargs)
1.1.4 DestroyModelMixin源码
class DestroyModelMixin:"""删除单对象数据"""def destroy(self, request, *args, **kwargs):instance = self.get_object()self.perform_destroy(instance)return Response(status=status.HTTP_204_NO_CONTENT)def perform_destroy(self, instance):instance.delete()
1.2 视图集viewset的源码:
class GenericViewSet(ViewSetMixin, generics.GenericAPIView):"""默认情况下,GenericViewSet类不提供任何操作,但包含通用视图行为的基本集,如' get_object '和' get_queryset '方法。"""passclass ReadOnlyModelViewSet(mixins.RetrieveModelMixin,mixins.ListModelMixin,GenericViewSet):"""提供默认的' list() '和' retrieve() '动作的视图集."""passclass ModelViewSet(mixins.CreateModelMixin,mixins.RetrieveModelMixin,mixins.UpdateModelMixin,mixins.DestroyModelMixin,mixins.ListModelMixin,GenericViewSet):"""一个视图集提供了默认的' create() ', ' retrieve() ', ' update() ',' partial_update() ', ' destroy() '和' list() '操作。"""pass
1.3 generic相关视图的介绍:
1.3.1 视图架构图
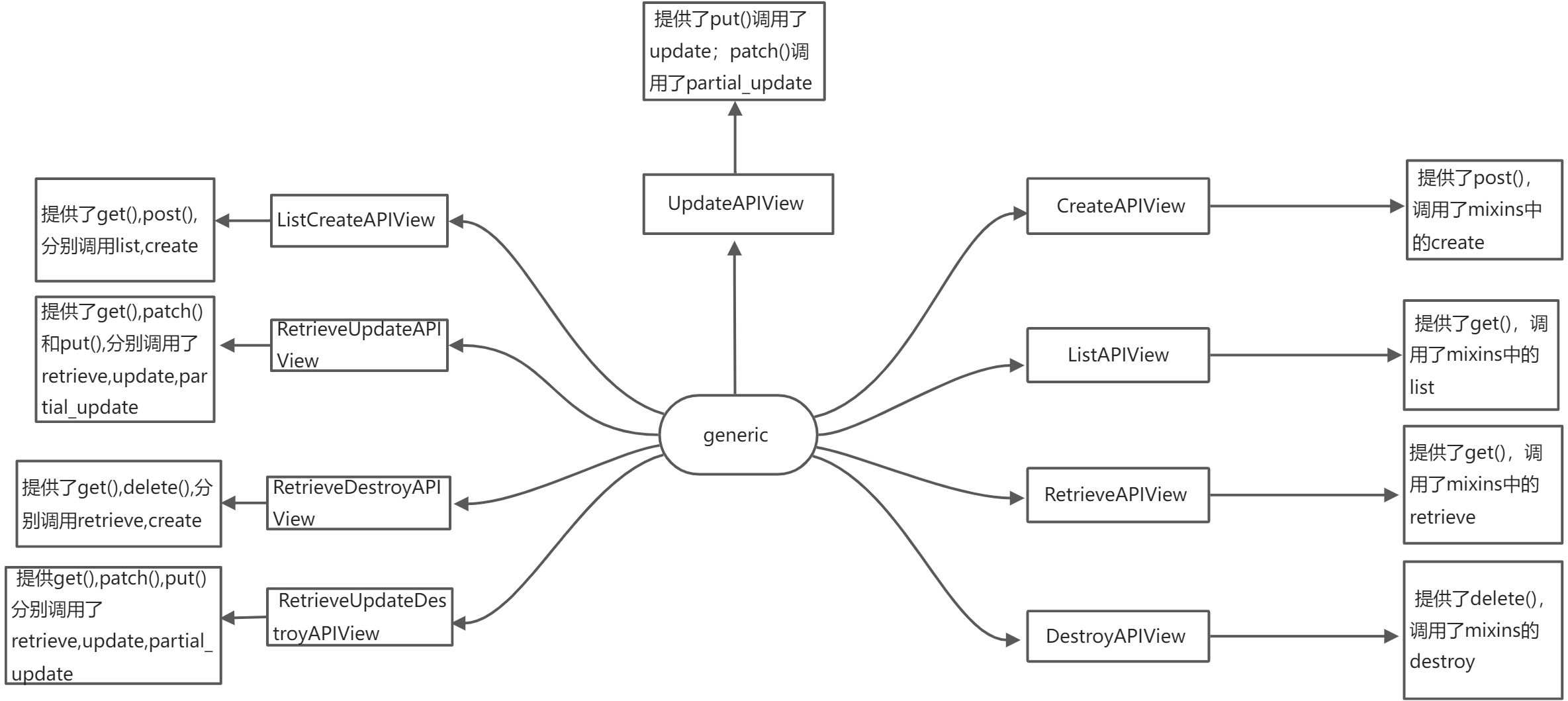
1.3.1 视图源码
class CreateAPIView(mixins.CreateModelMixin,GenericAPIView):"""Concrete view for creating a model instance."""def post(self, request, *args, **kwargs):return self.create(request, *args, **kwargs)class ListAPIView(mixins.ListModelMixin,GenericAPIView):"""Concrete view for listing a queryset."""def get(self, request, *args, **kwargs):return self.list(request, *args, **kwargs)class RetrieveAPIView(mixins.RetrieveModelMixin,GenericAPIView):"""Concrete view for retrieving a model instance."""def get(self, request, *args, **kwargs):return self.retrieve(request, *args, **kwargs)class DestroyAPIView(mixins.DestroyModelMixin,GenericAPIView):"""Concrete view for deleting a model instance."""def delete(self, request, *args, **kwargs):return self.destroy(request, *args, **kwargs)class UpdateAPIView(mixins.UpdateModelMixin,GenericAPIView):"""Concrete view for updating a model instance."""def put(self, request, *args, **kwargs):return self.update(request, *args, **kwargs)def patch(self, request, *args, **kwargs):return self.partial_update(request, *args, **kwargs)class ListCreateAPIView(mixins.ListModelMixin,mixins.CreateModelMixin,GenericAPIView):"""Concrete view for listing a queryset or creating a model instance."""def get(self, request, *args, **kwargs):return self.list(request, *args, **kwargs)def post(self, request, *args, **kwargs):return self.create(request, *args, **kwargs)class RetrieveUpdateAPIView(mixins.RetrieveModelMixin,mixins.UpdateModelMixin,GenericAPIView):"""Concrete view for retrieving, updating a model instance."""def get(self, request, *args, **kwargs):return self.retrieve(request, *args, **kwargs)def put(self, request, *args, **kwargs):return self.update(request, *args, **kwargs)def patch(self, request, *args, **kwargs):return self.partial_update(request, *args, **kwargs)class RetrieveDestroyAPIView(mixins.RetrieveModelMixin,mixins.DestroyModelMixin,GenericAPIView):"""Concrete view for retrieving or deleting a model instance."""def get(self, request, *args, **kwargs):return self.retrieve(request, *args, **kwargs)def delete(self, request, *args, **kwargs):return self.destroy(request, *args, **kwargs)class RetrieveUpdateDestroyAPIView(mixins.RetrieveModelMixin,mixins.UpdateModelMixin,mixins.DestroyModelMixin,GenericAPIView):"""Concrete view for retrieving, updating or deleting a model instance."""def get(self, request, *args, **kwargs):return self.retrieve(request, *args, **kwargs)def put(self, request, *args, **kwargs):return self.update(request, *args, **kwargs)def patch(self, request, *args, **kwargs):return self.partial_update(request, *args, **kwargs)def delete(self, request, *args, **kwargs):return self.destroy(request, *args, **kwargs)
二.视图中所涉及的重要的源码
2.1 GenericAPIView:
class GenericAPIView(views.APIView):"""Base class for all other generic views."""#你需要设置这些属性,#或重写' get_queryset() ' / ' get_serializer_class() '。#如果你重写一个视图方法,它是重要的调用# ' get_queryset() '而不是直接访问' queryset '属性,# as ' queryset '只会被求值一次,并且这些结果会被缓存#对于所有后续请求。queryset = Noneserializer_class = None#如果你想使用对象查找而不是pk,设置'lookup_field'。#对于更复杂的查找需求,需重写' get_object() '。lookup_field = 'pk' #默认为pk也就是主键lookup_url_kwarg = None #url中的位置参数#用于查询集过滤的过滤后端类(往往这里常用的就是结合django的settings中配置REST_FRAMEWORK = {#'DEFAULT_FILTER_BACKENDS': ['django_filters.rest_framework.DjangoFilterBackend']},属于#全局变量,你也可以不选择全局配置,在自己的视图集类下给该属性赋值:filter_backends = [DjangoFi#lterBackend]filter_backends = api_settings.DEFAULT_FILTER_BACKENDS# 用于查询集分页的样式。pagination_class = api_settings.DEFAULT_PAGINATION_CLASSdef get_queryset(self):"""获取此视图的项目列表。这必须是一个可迭代对象,并且是一个查询集。默认使用' self.queryset '。应该一直使用这个方法而不是访问self.queryset直接self.queryset '只求值一次,这些结果为所有后续请求缓存。如果需要提供不同的服务,您可能希望重写此选项查询集,取决于传入的请求。(如。返回特定于用户的项目列表)"""assert self.queryset is not None, ("'%s' should either include a `queryset` attribute, ""or override the `get_queryset()` method."% self.__class__.__name__)queryset = self.querysetif isinstance(queryset, QuerySet):# 确保对每个请求重新评估queryset.queryset = queryset.all()return querysetdef get_object(self):"""返回视图显示的对象。如果您需要提供非标准的,您可能需要重写它queryset查找。例如,如果对象使用multiple引用url conf中的关键字参数。"""#得到过滤后查询集赋值给querysetqueryset = self.filter_queryset(self.get_queryset())# Perform the lookup filtering.lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field#断言位置参数有没有在kwargsassert lookup_url_kwarg in self.kwargs, ('Expected view %s to be called with a URL keyword argument ''named "%s". Fix your URL conf, or set the `.lookup_field` ''attribute on the view correctly.' %(self.__class__.__name__, lookup_url_kwarg))filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]}obj = get_object_or_404(queryset, **filter_kwargs)# 权限的验证函数self.check_object_permissions(self.request, obj)return objdef get_serializer(self, *args, **kwargs):"""返回应该用于验证和的序列化器实例,反序列化输入和序列化输出。例如如果想要序列化list多对象的创建入库,可以重写该方法,在其中进行request.data为列表时,返回serializer_class(many=True, *args, **kwargs)加入many参数"""#从下方get_serializer_class看出最后得到了self.serializer_class#相当于serializer_class=self.serializer_class,把类属性serializer_class赋给了serializer_classserializer_class = self.get_serializer_class()#kwargs设置默认值,也就是需要序列化的额外内容contextkwargs.setdefault('context', self.get_serializer_context())#大家可以看到此时返回的序列化类的实例return serializer_class(*args, **kwargs)def get_serializer_class(self):"""断言不为空时返回序列化类名,反之就返回类型应该包含serializer_class属性或者重写get_serializer_class方法的异常字样"""assert self.serializer_class is not None, ("'%s' should either include a `serializer_class` attribute, ""or override the `get_serializer_class()` method."% self.__class__.__name__)return self.serializer_classdef get_serializer_context(self):"""Extra context provided to the serializer class.序列化类提供额外的序列参数context上下文"""return {'request': self.request,'format': self.format_kwarg,'view': self}def filter_queryset(self, queryset):'''给定一个查询集,使用过滤后端类及其下方法过滤它。返回得到过滤后的查询集,如filter_backends指定的是DjangoFilterBackend,其实它调用了原本属于源码DjangoFilterBackend类下的filter_queryset,其中backend代表我自定义的filterset类,filter_backends属性代表我们自定义的filterset类的列表,然后使用backend()也就是自定义的过滤集类的对象调用filter_queryset,返回过滤后的查询集赋值给了queryset'''for backend in list(self.filter_backends):queryset = backend().filter_queryset(self.request, queryset, self)return queryset#此装饰器的作用就是将函数转变成属性@propertydef paginator(self):"""返回与视图关联的分页器实例,或者“None”。"""if not hasattr(self, '_paginator'):if self.pagination_class is None:self._paginator = Noneelse:self._paginator = self.pagination_class()return self._paginatordef paginate_queryset(self, queryset):"""返回结果的单个页面,如果分页被禁用,则返回“None”。其中的self.paginator代表的是分页类的实例,然后调用分页类源码下paginate_queryset()返回的是页面对象的列表"""if self.paginator is None:return Nonereturn self.paginator.paginate_queryset(queryset, self.request, view=self)def get_paginated_response(self, data):"""返回给定输出数据的分页样式' Response '对象。"""assert self.paginator is not Nonereturn self.paginator.get_paginated_response(data)
2.3 PageNumberPagination:
class PageNumberPagination(BasePagination):"""一个简单的基于页码的样式,它支持如下的页码查询参数。例如:http://api.example.org/accounts/?page=4http://api.example.org/accounts/?page=4&page_size=100"""# The default page size.# 默认为 `None`, 意思是分页被禁用.page_size = api_settings.PAGE_SIZE#django_paginator_class赋值了Django 分页器类(DjangoPaginator)django_paginator_class = DjangoPaginator# 客户端可以使用此查询参数控制页面.page_query_param = 'page'page_query_description = _('A page number within the paginated result set.')#客户端可以使用这个查询参数来控制页面大小。#默认为“None”。设置为eg 'page_size'以启用使用。page_size_query_param = None#每页返回的结果数page_size_query_description = _('Number of results to return per page.')#设置一个整数来限制客户端可能请求的最大页面大小。#只有当设置了'page_size_query_param'时才相关.max_page_size = None#字符串值的列表或元组,指可与请求集合中最后一页一起使用的值。默认为page_query_param('last',)last_page_strings = ('last',)#在可浏览 API 中呈现分页控件时要使用的模板的名称。可以重写以修改呈现样式,#或设置为完全禁用 HTML 分页控件。template = 'rest_framework/pagination/numbers.html'invalid_page_message = _('Invalid page.')#该方法将传递初始查询集参数,并应返回一个可迭代对象。该对象仅包含所请求页面(本页面)中的数据def paginate_queryset(self, queryset, request, view=None):"""如果需要,对查询集进行分页,或者返回一个页面对象如果没有为此视图配置分页,则为' None '。"""#获取页面的大小page_size = self.get_page_size(request)if not page_size: #如果不存在返回为nonereturn Nonepaginator = self.django_paginator_class(queryset, page_size)page_number = self.get_page_number(request, paginator)try:self.page = paginator.page(page_number)except InvalidPage as exc:msg = self.invalid_page_message.format(page_number=page_number, message=str(exc))raise NotFound(msg)if paginator.num_pages > 1 and self.template is not None:# The browsable API should display pagination controls.self.display_page_controls = Trueself.request = requestreturn list(self.page)#返回分页的页数def get_page_number(self, request, paginator):page_number = request.query_params.get(self.page_query_param, 1)if page_number in self.last_page_strings:page_number = paginator.num_pagesreturn page_number#该方法将传递一个序列化的页面数据,并应返回一个实例def get_paginated_response(self, data):return Response(OrderedDict([('count', self.page.paginator.count),('next', self.get_next_link()),('previous', self.get_previous_link()),('results', data)]))#返回一个页面显示的模式样板def get_paginated_response_schema(self, schema):return {'type': 'object','properties': {'count': {'type': 'integer','example': 123,},'next': {'type': 'string','nullable': True,'format': 'uri','example': 'http://api.example.org/accounts/?{page_query_param}=4'.format(page_query_param=self.page_query_param)},'previous': {'type': 'string','nullable': True,'format': 'uri','example': 'http://api.example.org/accounts/?{page_query_param}=2'.format(page_query_param=self.page_query_param)},'results': schema,},}#获取页面的容量大小def get_page_size(self, request):if self.page_size_query_param:try:return _positive_int(request.query_params[self.page_size_query_param],strict=True,cutoff=self.max_page_size)except (KeyError, ValueError):passreturn self.page_size#在结果中返回下一个页面链接地址def get_next_link(self):if not self.page.has_next():return Noneurl = self.request.build_absolute_uri()page_number = self.page.next_page_number()return replace_query_param(url, self.page_query_param, page_number)#在结果中返回上一个页面链接地址def get_previous_link(self):if not self.page.has_previous():return Noneurl = self.request.build_absolute_uri()page_number = self.page.previous_page_number()if page_number == 1:return remove_query_param(url, self.page_query_param)return replace_query_param(url, self.page_query_param, page_number)
2.3 Paginator:
提供参考的第三方举例详情地址https://www.jianshu.com/p/e9686192e7ee
class Paginator:# Translators: 字符串,用于替换省略页中的省略页码# 分页器生成的范围, e.g. [1, 2, '…', 5, 6, 7, '…', 9, 10].ELLIPSIS = _('…')def __init__(self, object_list, per_page, orphans=0,allow_empty_first_page=True):self.object_list = object_listself._check_object_list_is_ordered()self.per_page = int(per_page) #每页中允许的最大对象数。必选参数self.orphans = int(orphans) #这是一个缺省参数,如果最后一页的数据小于这个值,会合并到上一页self.allow_empty_first_page = allow_empty_first_page #允许首页为空 ,默认为Truedef __iter__(self):for page_number in self.page_range:yield self.page(page_number)def validate_number(self, number):"""校验给的基于1的页数"""try:#先判断页面数是不是float并且不是整形抛出异常if isinstance(number, float) and not number.is_integer():raise ValueErrornumber = int(number)except (TypeError, ValueError):raise PageNotAnInteger(_('That page number is not an integer'))#如果页数小于1,抛出EmptyPageif number < 1:raise EmptyPage(_('That page number is less than 1')#如果页数大于总页数,抛出EmptyPageif number > self.num_pages:#这个就是属于结果为0的情况没有一个页,并且允许首页为空就pass,否则抛出空页面异常if number == 1 and self.allow_empty_first_page:passelse:raise EmptyPage(_('That page contains no results'))return numberdef get_page(self, number):"""返回指定页的page对象,页码从1开始。该方法可处理超出范围或无效的页码如果给定页码不是数字则返回第一页,如果给定页码小于1或大于总页数,则返回最后一页"""try:#先得到一个通过验证的页数值number = self.validate_number(number)#给出不是整形的异常,则给number赋值1except PageNotAnInteger:number = 1#给出空页异常处理,则给number赋值为总页数也就是最后一页except EmptyPage:number = self.num_pagesreturn self.page(number)def page(self, number):"""返回指定页的page对象,它不能处理超出范围或无效页码,指定的页码无效时会触发validate_number异常."""number = self.validate_number(number)#bottom值代表的是指定页中的第一个对象在self.object_list列表中的下标#不代表该页面第一个对象所排序的位置,例如一共5个对象,一个页面容量2个对象,总共就是3个页面#第二个页面的第一个也就是起始对象的序号是3bottom = (number - 1) * self.per_page#top值代表的self.object_list列表中的区间的右边界值(但不包含)其实取的也就是该页的最后一个对象top = bottom + self.per_page#top + self.orphans(代表列表右边界值)如果大于等于所有页的总对象数,两边同时家去top值,相当于#最后一页的对象数量小于等于self.orphans值,则将最后一页的对象数合并到前一页中if top + self.orphans >= self.count:top = self.count#object_list[bottom:top]代表该页的所有对象return self._get_page(self.object_list[bottom:top], number, self)def _get_page(self, *args, **kwargs):"""返回单个页面的实例。其中的Page是另一个源码类"""return Page(*args, **kwargs)@cached_property #缓存属性的意思,类似于@property的效果def count(self):"""返回所有页面中的对象总数"""c = getattr(self.object_list, 'count', None)if callable(c) and not inspect.isbuiltin(c) and method_has_no_args(c):return c()return len(self.object_list)@cached_propertydef num_pages(self):"""返回总页数."""#如果总对象数=0,并且self.allow_empty_first_page不为True,返回0if self.count == 0 and not self.allow_empty_first_page:return 0#max取最大值,其中self.count - self.orphans可能会看不懂为什么这么减,但是你只要验证符合页面数#计算结果,例如count为5,orphans=2,差值hits就是3,那hits/self.per_page=1.5,你会发现页面数为2#是符合原本应该为3页其最后一页为1个对象满足小于等于orphans值2,也就符合合并到前一页,成为2页。hits = max(1, self.count - self.orphans)#以整数形式返回该变量的上限值,如ceil(1.5)=2。return ceil(hits / self.per_page)@propertydef page_range(self):"""返回页面迭代器,页码从1开始"""#self.num_pages+1为右边界值(开区间),为的是能取到最后一页的值return range(1, self.num_pages + 1)def _check_object_list_is_ordered(self):"""警告实例。object_list是无序的(通常是QuerySet)。"""ordered = getattr(self.object_list, 'ordered', None)if ordered is not None and not ordered:obj_list_repr = ('{} {}'.format(self.object_list.model, self.object_list.__class__.__name__)if hasattr(self.object_list, 'model')else '{!r}'.format(self.object_list))warnings.warn('Pagination may yield inconsistent results with an unordered ''object_list: {}.'.format(obj_list_repr),UnorderedObjectListWarning,stacklevel=3)def get_elided_page_range(self, number=1, *, on_each_side=3, on_ends=2):"""返回一个基于1的页面范围,其中某些值被省略。第一个参数number为当前页码数, on_each_side为当前页码左右两边的页数,on_ends为首尾页码范围。如果当前页码为第10页,使用该方法将输出如下页码范围(page_range)。10左右两边各有3页,首尾各有2页,其余页码号码用...代替。将page_range这个变量传递到前端模板进行遍历即可实现智能分页。例如:[1, 2, '…', 7, 8, 9, 10, 11, 12, 13, '…', 49, 50]"""number = self.validate_number(number)if self.num_pages <= (on_each_side + on_ends) * 2:yield from self.page_rangereturnif number > (1 + on_each_side + on_ends) + 1:yield from range(1, on_ends + 1)yield self.ELLIPSISyield from range(number - on_each_side, number + 1)else:yield from range(1, number + 1)if number < (self.num_pages - on_each_side - on_ends) - 1:yield from range(number + 1, number + on_each_side + 1)yield self.ELLIPSISyield from range(self.num_pages - on_ends + 1, self.num_pages + 1)else:yield from range(number + 1, self.num_pages + 1)
2.4 DjangoFilterBackend(后端过滤类):
class DjangoFilterBackend(metaclass=RenameAttributes):filterset_base = filterset.FilterSetraise_exception = True@propertydef template(self):if compat.is_crispy():return 'django_filters/rest_framework/crispy_form.html'return 'django_filters/rest_framework/form.html'def get_filterset(self, request, queryset, view):'''先调用self.get_filterset_class获取视图中的过滤集类filterset_class如果filterset_class为none,则返回none,除此之外就返回filterset_class(**kwargs)'''filterset_class = self.get_filterset_class(view, queryset)if filterset_class is None:return None#调用self.get_filterset_kwargs返回一个字典有keys:queryset,request,data#其中的data就是url后的过滤参数request.query_paramskwargs = self.get_filterset_kwargs(request, queryset, view)return filterset_class(**kwargs)def get_filterset_class(self, view, queryset=None):"""获取过滤集类"""#从我们定义的视图中获取filterset_class属性filterset_class = getattr(view, 'filterset_class', None)#从我们定义的视图中获取filterset_fields属性filterset_fields = getattr(view, 'filterset_fields', None)#例如我们自定义的视图类提供了filter_classs属性并赋值了自定义的过滤类#如果filterset_class为none,并且定义的视图类中有filter_class属性if filterset_class is None and hasattr(view, 'filter_class'):utils.deprecate("`%s.filter_class` attribute should be renamed `filterset_class`."% view.__class__.__name__)#从试图类中获取filter_classs属性并赋值给filterset_classfilterset_class = getattr(view, 'filter_class', None)#如果filterset_fields为none,并且定义的视图类中有filter_fields属性if filterset_fields is None and hasattr(view, 'filter_fields'):utils.deprecate("`%s.filter_fields` attribute should be renamed `filterset_fields`."% view.__class__.__name__)#从试图类中获取filter_fields属性并赋值给filterset_fieldsfilterset_fields = getattr(view, 'filter_fields', None)#如果视图中的filterset_class属性不为空if filterset_class:filterset_model = filterset_class._meta.model# FilterSets不需要指定一个元类if filterset_model and queryset is not None:assert issubclass(queryset.model, filterset_model), \'FilterSet model %s does not match queryset model %s' % \(filterset_model, queryset.model)return filterset_class#如果视图中的filterset_fields属性和queryset不为noneif filterset_fields and queryset is not None:MetaBase = getattr(self.filterset_base, 'Meta', object)class AutoFilterSet(self.filterset_base):class Meta(MetaBase):model = queryset.modelfields = filterset_fieldsreturn AutoFilterSetreturn Nonedef get_filterset_kwargs(self, request, queryset, view):'''返回一个字典有data,queryset,requestrequest.query_params就是get请求url后拼接的过滤参数'''return {'data': request.query_params,'queryset': queryset,'request': request,}def filter_queryset(self, request, queryset, view):filterset = self.get_filterset(request, queryset, view)if filterset is None:return querysetif not filterset.is_valid() and self.raise_exception:raise utils.translate_validation(filterset.errors)return filterset.qsdef to_html(self, request, queryset, view):filterset = self.get_filterset(request, queryset, view)if filterset is None:return Nonetemplate = loader.get_template(self.template)context = {'filter': filterset}return template.render(context, request)def get_coreschema_field(self, field):if isinstance(field, filters.NumberFilter):field_cls = compat.coreschema.Numberelse:field_cls = compat.coreschema.Stringreturn field_cls(description=str(field.extra.get('help_text', '')))def get_schema_fields(self, view):# This is not compatible with widgets where the query param differs from the# filter's attribute name. Notably, this includes `MultiWidget`, where query# params will be of the format `<name>_0`, `<name>_1`, etc...assert compat.coreapi is not None, 'coreapi must be installed to use `get_schema_fields()`'assert compat.coreschema is not None, 'coreschema must be installed to use `get_schema_fields()`'try:queryset = view.get_queryset()except Exception:queryset = Nonewarnings.warn("{} is not compatible with schema generation".format(view.__class__))filterset_class = self.get_filterset_class(view, queryset)return [] if not filterset_class else [compat.coreapi.Field(name=field_name,required=field.extra['required'],location='query',schema=self.get_coreschema_field(field)) for field_name, field in filterset_class.base_filters.items()]def get_schema_operation_parameters(self, view):try:queryset = view.get_queryset()except Exception:queryset = Nonewarnings.warn("{} is not compatible with schema generation".format(view.__class__))filterset_class = self.get_filterset_class(view, queryset)if not filterset_class:return []parameters = []for field_name, field in filterset_class.base_filters.items():parameter = {'name': field_name,'required': field.extra['required'],'in': 'query','description': field.label if field.label is not None else field_name,'schema': {'type': 'string',},}if field.extra and 'choices' in field.extra:parameter['schema']['enum'] = [c[0] for c in field.extra['choices']]parameters.append(parameter)return parameters

若有收获,就点个赞吧
0 人点赞
