- 单行函数:只对一行进行变换,每行返回一个结果
数值函数
字符串函数
日期和时间函数
获取日期、时间
SELECT CURDATE(),CURRENT_DATE(),CURTIME(),NOW(),SYSDATE(),UTC_DATE(),UTC_TIME()FROM DUAL
日期与时间戳的转换
SELECT UNIX_TIMESTAMP(),FROM_UNIXTIME(1234455)FROM DUAL
获取月份、星期、星期数、天数等函数
SELECT YEAR(CURDATE()),
日期操作函数
EXTRACT(type FROM date) 返回指定日期中特定的部分,type指定返回的值
获取当前秒数SELECT EXTRACT(SECOND FROM NOW())FROM DUAL;
时间和秒钟的转换函数
TIME_TO-SEC(time) 将time转换为秒并返回结果值
SEC_TO_TIME(secondes) 将seconds转换为包含小时、分钟和秒的时间
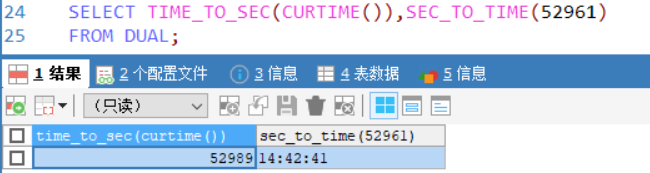
SELECT TIME_TO_SEC(CURTIME()),SEC_TO_TIME()FROM DUAL;
计算日期和时间的函数
DATE_ADD(datatime,INTERVAL exprtype),ADDDATE(date,INTERVAL exprtype) 给定与返回日期时间相差INTERVAL时间段的日期和时间
SELECT NEW(),DATE_ADD(NEW(),INTERVAL 1 YEAR),FROM DUAL;
日期的格式化和解析
格式化:日期——>字符串
- 解析: 字符串——>日期
此时是日期的显式格式化和解析
此前,接触过的隐式的格式化和解析
SELECT *FROM employeesWHERE hire_date = '1993-01-13';
格式化
SELECT DATE_FORMAT(CURDATE(),'%Y-%M-%D')FROM DUAL;
流程控制函数
- 可以根据不同的条件,执行不同的处理流程,在SQL语句中实现不同的条件选择
IF()、IFNULL()、CASE()函数
CASE WHEN 条件1 THEN 结果1 WHEN … 相当于if…else…
CASE expr WHEN 常量1 THEN 1 … 相当于switch…case…
IF
SELECT last_name,salary,IF(salary >= 6000,'高工资','低工资')FROM employees;
SELECT last_name,commission_pct,IF(commission_pct IS NOT NULL,commission_pct,0) "details",salary*12*(1+IF(commission_pct IS NOT NULL,commission_pct,0)) "annual_sal"FROM employees;
IFNULL
SELECT last_name,commission_pct,IFNULL(commission_pct,0) "details" //如果commission_pct不是null,则输出自己FROM employees;
CASE WHEN … THEN … ```sql SELECT last_name,salary,CASE WHEN salary >= 15000 THEN ‘1’
WHEN salary >= 1000 THEN '2'ELSE '3' END "details"
FROM employees;
- CASE ... WHEN ... THEN ...<a name="Z7I2x"></a># 加密与解密函数- 对于数据库中的数据进行加密和解密处理,防止数据被他人窃取<a name="PXhJM"></a># MySQL信息函数<a name="GHX5q"></a># 聚合函数- 聚合(聚集、分组)函数,对一组数据进行汇总的函数,输入一组数据的集合,输出单个值<a name="vLbws"></a>## 常见的聚合函数- AVG / SUM / MAX / MIN / COUNT / 方差、标准差、中位数<a name="c8wjY"></a>### AVG/SUM:- 只适用于数值类型的字段或变量```sqlSELECT AVG(salary),SUM(salary),AVG(salary)*107FROM employees;SELECT SUM(last_name) # 字符串是不合理的,结果没有意义FROM employees;
MAX/MIN
- 适用于数值类型、字符串类型、日期时间类型的字段或变量 ```sql SELECT MAX(salary),MIN(salary) FROM employees;
SELECT MAX(last_name),MIN(last_name) FROM employees;
<a name="QGmJb"></a>### COUNT- 作用:计算指定字段在查询结构中出现的个数```sqlSELECT COUNT(employee_id),COUNT(salary),COUNT(1) # 107FROM employees;
- 如果计算表中有多条记录,如何实现?
- 方式1:COUNT(*)
- 方式2:COUNT(1)
- 方式3:COUNT(具体字段) 不一定对!
- 注意:计算指定字段出现的个数时,是不计算NULL值的。 ```sql SELECT COUNT(commisssion_pct) FROM employees;
SELECT commission_pct FROM employees WHERE commisssion_pct IS NOT NULL
- 公式:AVG = SUM / COUNT```sqlSELECT AVG(salary),SUM(salary)/COUNT(salary)FROM employees; //二者结果一致
SELECT AVG(commission_pct),SUM(commission_pct)/COUNT(commission_pct),SUM(commission_pct)/107 //1,2相等.3与1,2不相等FROM employees; //因为AVG也会考虑过滤null值的问题//SUM也不考虑Null值
需求:查询公司中平均奖金率
错误的:SELECT AVG(commission_pct)FROM employees;正确的: 求平均的话需要把所有的人都考虑进去,所以不能过滤null值SELECT SUM(commission_pct) / COUNT(IFNULL(commission_pct,0))或AVG(IFNULL(commission_pct,0))FROM employees;
- 如果需要统计表中的记录数,使用COUNT(*)、COUNT(1)、COUNT(具体字段)哪个效率更高?
- 如果使用的是MyISAM存储引擎,则三者效率相同,都是o(1)
- 如果使用的是InnoDB存储引擎,则三者效率:COUNT(*) = COUNT(1) > COUNT(具体字段)
GROUP BY 的使用
需求:查询各个部门的平均工资,最高工资
SELECT department_id,AVG(salary)FROM employeesGROUP BY department_id
需求:查询各个job_id的平均工资
SELECT job_id,AVG(salary)FROM employeesGROUP BY job_id;
需求:查询各个department_id,job_id的平均工资
SELECT department_id,job_id,AVG(salary)FROM employeesGROUP BY department_id,job_id;或SELECT department_id,job_id,AVG(salary)FROM employeesGROUP BY job_id,department;二者是一样的
- 结论:SELECT中出现的非组函数的字段必须声明在GROUP BY中,
反之,GROUP BY 中声明的字段可以不出现在SELECT 中
- 结论2:GROUP BY 声明在FROM 后面、WHERE后面、ORDER BY前面、LIMIT前面
- 结论3:MySQL中GROUP BY中使用WITH ROLLUP
SELECT department_id,job_id,AVG(salary)FROM employeesGROUP BY department_id; 这样写是错误的,因为每个部门对应多个 job_id;虽然没有报错,但是结果是不对的
SELECT department_id,AVG(salary)FROM employeesGROUP BY department_id WITH ROLLUP;
- 如果要分组则需要使用 group by
- 如果把整个表看成一个组,则使用order by即可
HAVING的使用
- 作用:用来过滤数据的
需求:
练习:查询各个部门中最高工资比1000高的部门信息
错误的写法SELECT department_id,MAX(salary)FROM employeesWHERE MAX(salary) > 1000GROUP BY department_id
- 要求1:一旦过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE。否则,报错
要求2:HAVING必须声明在GROUP BY 的后面
正确的写法SELECT department_id,MAX(salary)FROM employeesGROUP BY department_idHAVING MAX(salary) > 1000;
要求3:开发中使用HAVING的前提是SQL中使用了GROUP BY
练习:查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息
方式一:推荐,执行效率高于方式二
SELECT department_id,MAX(salary)FROM employeesWHERE department_id IN (10,20,30,40)GROUP BY department_idHAVING MAX(salary) > 10000;
方式二:
SELECT department_id,MAX(salary)FROM employeesGROUP BY department_idHAVING MAX(salary) > 10000 AND department_id IN (10,20,30,40);
结论:
- 当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中
- 当过滤条件中没有聚合函数时,则此过滤条件声明在WHERE中或HAVING中都可以。但是建议声明在WHERE中。
WHERE与HAVING的对比
- 适用范围:HAVING的适用范围更广
- 如果过滤条件中没有聚合函数,WHERE的效率高于HAVING
WHERE是先筛选后连接,而HAVING是先连接后筛选。
WHERE的执行顺序比HAVING更靠前,先筛选一个较小数据集和关联表进行连接,占用的资源比较少。HAVING需要先把结果集准备好,然后对大的数据集进行筛选,占用的资源比较多。
SQL的底层执行原理
SELECT语句的完整结构
SQL92语法
SELECT ...,...,...(存在聚合函数)FROM ...,...,...WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件GROUP BY ...,...HAVING 包含聚合函数的过滤条件ORDER BY ...,...(ASC/DESC)LIMIT ...,...
SQL99语法
SELECT ...,...,...(存在聚合函数)FROM ...(LEFT/RIGHT)JOIN...ON 多表的连接条件(LEFT/RIGHT)JOIN...ON...WHERE 不包含聚合函数的过滤条件GROUP BY ...,...HAVING 包含聚合函数的过滤条件ORDER BY ...,...(ASC/DESC)LIMIT ...,...
SQL语句执行顺序

FROM ...,... -> ON -> (LEFT / RIGHT JOIN) -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ORDER BY -> LIMIT
练习
WHERE语句可否使用组函数进行过滤?
不可以,
查询公司员工工资的最大值,最小值,平均值,总和
SELECT employee_id,MAX(salary),MIN(salary),AVG(salary),SUM(salary)FROM employees
查询各job_id的员工的工资的最大值,最小值,平均值,总和
SELECT job_id,MAX(salary),MIN(salary),AVG(salary),SUM(salary)FROM employeesGROUP BY job_id
选择具有各个job_id的员工人数
SELECT job_id,COUNT(*)FROM employeesGROUP BY job_id;
查询员工最高工资和最低工资的差距(DIFFERENCE)
SELECT MAX(salary) - MIN(salary) "DIFFERENCE"FROM employees
查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
SELECT manager_id,MIN(salary)FROM employeesWHERE manager_id IS NOT NULLGROUP BY manager_idHAVING MIN(salary) >= 6000
查询所有部门的名字,location_id,员工数量和平均工资,并按照平均工资降序
SELECT d.department_name,d.location_id,COUNT(employee_id),AVG(salary)FROM departments d LEFT JOIN employees eON d.department_id = e.department_idGROUP BY department_name,location_idORDER BY AVG(salary) DESC;
查询每个工种、每个部门的部门名、工种名和最低工资
SELECT e.job_id,d.department_id,MIN(salary)FROM departments d LEFT JOIN employees eON d.department_id = e.department_idGROUP BY department_name,job_id

若有收获,就点个赞吧
0 人点赞
