英文文档:链接
1.具体应用案例
import pandas as pdimport numpy as nppath=r"路径"df=pd.read_excel(path) #读取文件df.info() #展示数据集大概信息df.describe() #仅展示数值类型的列(如int float)#对数据框架的某一列的数据类型全转换为另一数据类型时#1.函数法def changeStr(x):return str(x)df.某个列名 = df.某个列名.apply(changeStr)#2.lambda表达式df.某个列名 = df.某个列名.apply(lambda x:str(x))#查找数据框中的重复行:布尔规则,其中df.duplicated()返回为true或者false的一张表df[df.duplicated()] #这种方式更适合于读,不适合于写,一般适合写的都是loc()#去掉重复行,新的数据集为df1df1 = df.drop_duplicates()#数据集的索引放入一个列表中df1[布尔规则].index#查找数据框架中的为NaN的数据:布尔规则df[df.某个列名.isnull()]#常用的查找 loc iloc#日期操作 d.weekday() d.weekday_name#保存excelpath=r"自定义路径"df1.to_excel(path)#求后一天跟前一天的增幅df.diff()得到某一列数值型数据其中 每后一列减去前一列得差值#数据利差标准化处理def minMaxScaler(data):p = (data-data.min()/(data.max()-data.min()))return pdf1["标准化交易额"] = minMaxScaler(df1.交易额)
2.loc和iloc的区别
pd.iloc[行号,列号]
pd.loc[行标签,列标签]
iloc是基于索引位来选取数据集,行号和列号都是从0开始数,而且还是前开后闭,比如iloc[:3]则是选取前三行0,1,2三行数据。
loc是基于标签进行选取。闭区间,loc[:3]表明取到3,如果是从0开始的标签,则取0,1,2,3总共4行数据。
还有一个需要注意的地方,iloc中含有-1的用法,在loc中不会出现-1的这种用法。具体iloc中含-1的使用方法及结果如下:
iloc[n,-1]是选取的第n行最后一个元素(从0开始)
**
3.datetime库常用函数
1.导包并获得当前时间

2.将时间格式化
方法1:转化为datetime.date类型
只有datetime.date类型的才能用fromtimestamp函数
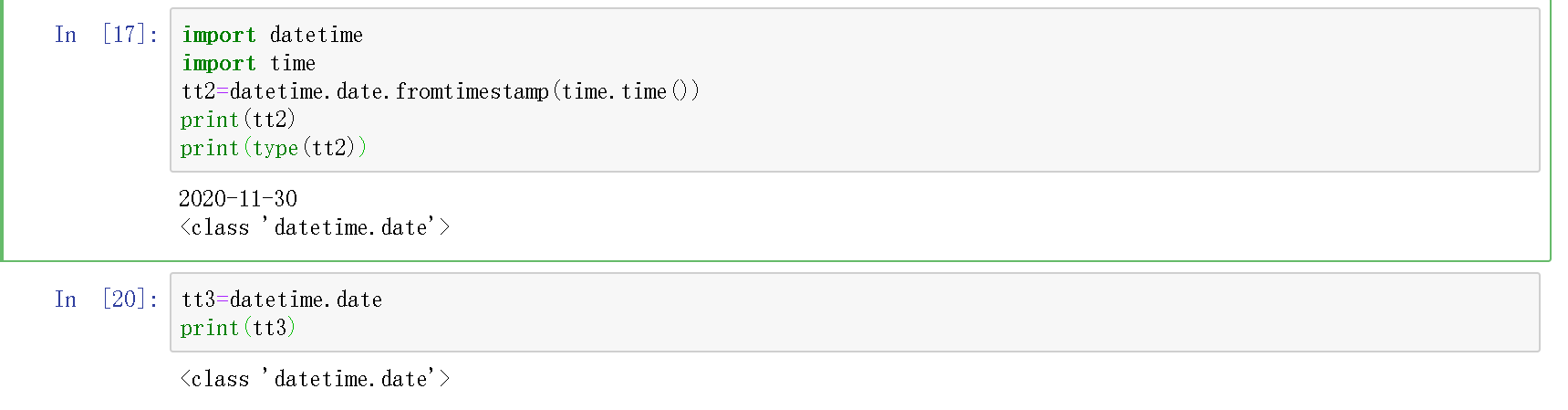
方法2:转化为字符串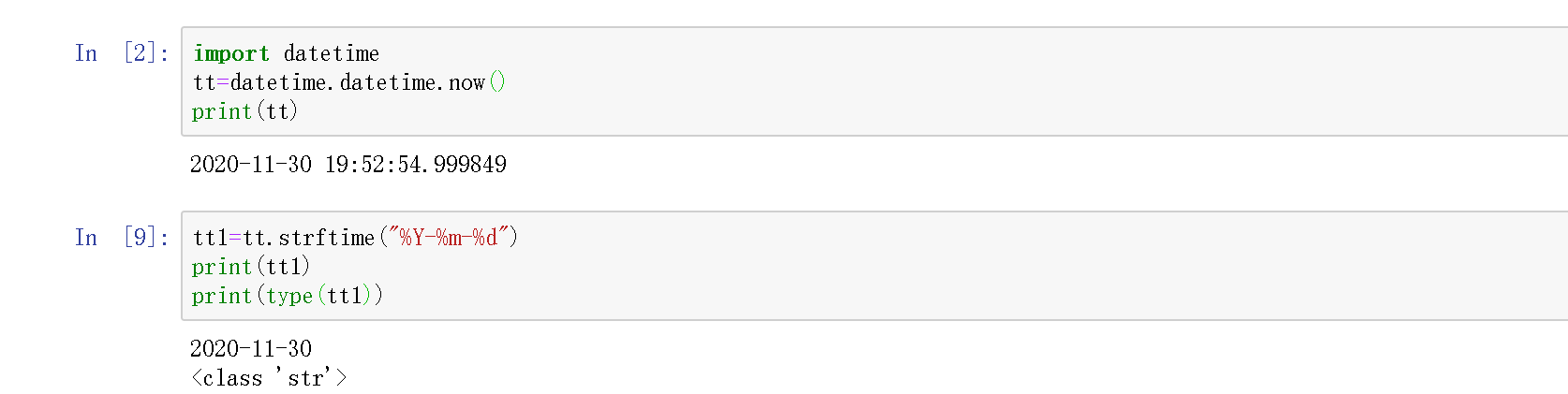
3.替换时间中年或者月或者日

4.修改时间中的日、时、分、秒等

5.显示时间中的信息
包括 哪一年 该年第几月 该月第几天 几点 几分 几秒 这个星期的星期几(注:从0开始,即星期1为0) 
4.pandas中的apply函数
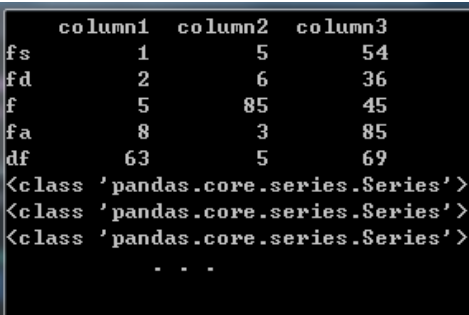
1.对列操作
import pandas as pdimport osdef f(column):print(type(column))df=pd.DataFrame({'column1':[1,2,5,8,63],'column2':[5,6,85,3,5],'column3':[54,36,45,85,69]},index=['fs','fd','f','fa','df'])print(df)df.apply(f)
import pandas as pdimport osimport numpy as npdf=pd.DataFrame({'column1':[1,2,5,8,63],'column2':[5,6,85,3,5],'column3':[54,36,45,85,69]},index=['fs','fd','f','fa','df'],dtype=np.object)print(df)def f2(x):x[3]="hello ,good boy"x[2]='hello ,good girl'df.apply(f2)print(df)
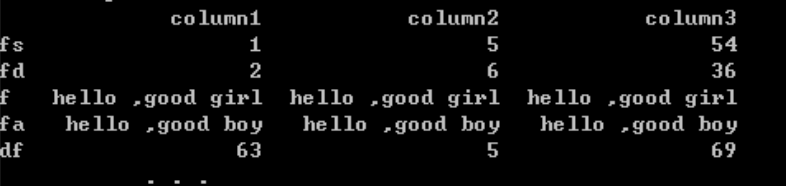
2.对行操作
def f3(x):print(type(x))print(x)df.apply(f3,axis=1)
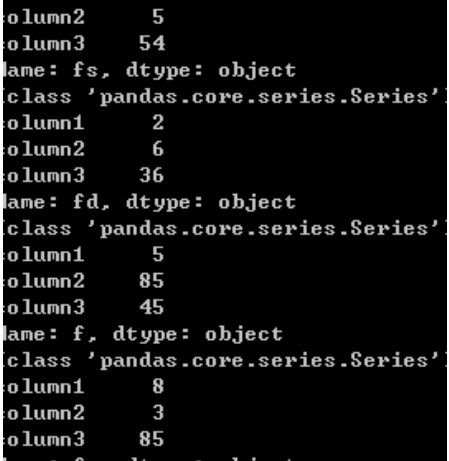
注:apply对行进行操作时,是不能对元素进行赋值的,但可以进行数据类型转换,也就是不能对行的值进行更改。
**
5.pandas中的drop与delete
1.drop函数
DataFrame.drop(labels=None, axis=0, index=None,columns=None, level=None, inplace=False, errors='raise')labels是指要删除的标签,一个或者是列表形式的多个,axis是指处哪一个轴,columns是指某一列或者多列,level是指等级,针对多重索引的情况,inplaces是否替换原来的dataframe
df = pd.DataFrame(np.arange(12).reshape(3,4),columns=['A', 'B', 'C', 'D'])df
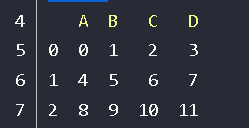
#指定删除相关的列,没有带columns,所以要指出是哪个轴上的>>> df.drop(['B', 'C'], axis=1)

#这里带有columns,所以不用加上axis参数>>> df.drop(columns=['B', 'C'])

#删除指定索引的行,这里没有axis参数,就是默认axis=0,也就是删除行>>> df.drop([0, 1])

多重索引另参考博客:链接
2.delete函数
del df['A'] # 删除A列,会就地修改
value_counts
#astype
#str.find

若有收获,就点个赞吧
0 人点赞
