1. Buffer Pool 并发性优化
多个线程并发访问Buffer Pool,此时都是访问内存里的一些共享的数据结构,比如说缓存页、各种链表之类的,那么此时必然要进行加锁了。然后让一个线程先完成一系列的操作,比如说要加载数据页到缓存页,更新free 链表,更新lru 链表,然后释放锁,接着下一个线程在执行一系列的操作。
可以使用多个Buffer Pool 优化并发能力。一般来说如果Buffer Pool 分配的内存小于1GB, 那么最多只会给你一个Buffer Pool。
我们可以给buffer pool 设置了8GB 的总内存,然后设置4个Buffer pool, 就是说每个2GB。
[server]innodb_buffer_pool_size = 8589934592innodb_buffer_pool_instances = 4
每个Buffer Pool 负责管理一部分的缓存页和描述数据块,有自己独立的free、flush、lru 等链表。
这个时候,假设多个线程并发来访问,那么不就可以把压力分散。
所以一旦你有多个buffer pool 之后,你的多线程并发访问的性能就会得到成倍的提升,因为多个线程可以在不同的buffer pool 中加锁和执行自己的操作。
2. buffer pool动态调整大小
buffer pool 在运行期间是不能动态的调整自己的大小的, 因为动态调整buffer pool 大小,比如 buffer pool 本来8G,运行期间给你调整为16GB, 此时就是需要向操作系统申一块新的16GB的连续内存,然后把现在的 buffer pool 中的所有的缓存页、描述数据块,各种链表。都拷贝到新的16GB的内存中去,这个过程是极为耗时的,性能很低下的,是不可以接受的。所以基于这套原理,buffer pool 是绝对不能支持运行期间调整大小的。
但是MySQL实际上设计了一个chunk 机制,也就是说 buffer pool是由很多chunk 组成的,他的大小是innodb_buffer_pool_chunk_size 参数控制的,默认是128M。
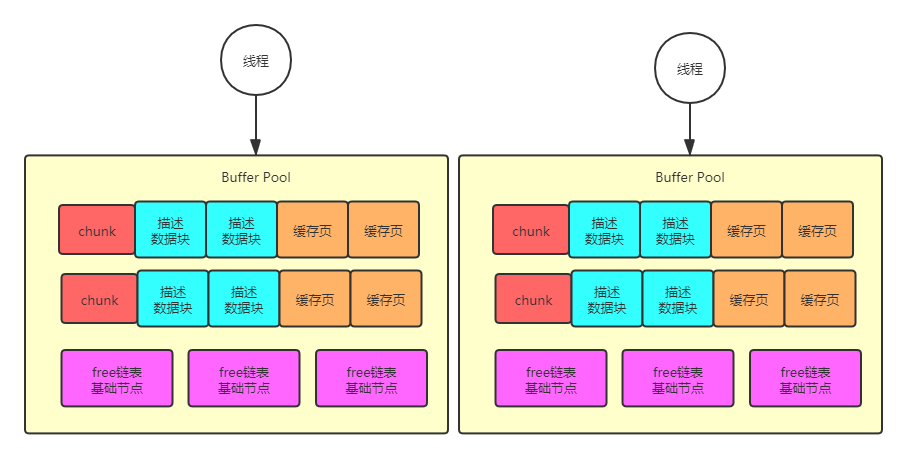
从上图可以看到, 每个chuck 就是一个系列的描述数据块和缓存页,这样的话,就是把buffer pool 按照chunk 为单位,拆分为一系列小数据块,但是每个buffer pool 是共用一套free、flush、lru 的链表的。
现在了有了chunk 机制就可以动态调整buffer pool大小了。
比如buffer pool 现在是8GB,现在动态加到16GB,那么申请一系列的128MB 大小的chuck 就可以了,只要每个chunk 是连续的128MB就行可,然后把这些申请的chunk 内存分配给buffer pool 就行了。
3. 生产环境中如何设置Buffer Pool
buffer pool 大小合理的设置是l机器内存的 50% ~ 60%左右,剩下的留给OS 和其他人使用。
确定了buffer pool 的总大小之后,怎么设置buffer pool 的个数,以及chunk 的大小呢。很关键的公式:buffer pool总大小=(chunk 大小 * buffer pool 数量)的倍数。
比如默认的chunk 大小是128MB,你打算给buffer pool 20GB的总大小,那么你可以设置buffer pool 的数量是16个。因为 chunk大小 * buffer pool 的数量 = 16 * 128MB = 2048MB , 总大小是20GB,此时buffer pool 总大小就是 2048MB 的10 倍,也就是说每个 buffer pool 可以包含 10个 chunk。
4. 查看InnoDB 参数的命令
SHOWENGINE INNODB STATUS
几个比较重要的参数:
(1)Total memory allocated, 这就是说buffer pool 最终的总大小是多少
(2)Buffer pool size,这就是说 buffer pool 一共能容纳多少个缓存页
(3)Free buffers,这就是说free 链表中一共多少个空闲的缓存页是可用的
(4)Database pages 和 Old database pages,就是说lru 链表中一共有多少个缓存页,以及冷数据区域里的缓存数量
(5)Modified db pages , 这就是flush 链表中的缓存页数量
(6)Pending reads 和 Pending writes,等待从磁盘上加载进缓存页的数量,还有就是即将从lru 链表中刷入磁盘的数量、即将从flush 链表中刷入磁盘的数量。
(7)Pages made young 和 not young , 这就是说已经 lru 冷数据区域里访问之后转移到热数据区域的缓存页的数量,以及在lru 冷数据区域里1s 内被访问了没进入热数据区域的缓存页的数量
(8)youngs/s 和 not young/s ,这就是说每秒从冷数据区域进入热数据区域的缓存页的数量,以及每秒在冷数据区域里被访问了但是不能进入热数据区域的缓存页的数量。
(9) Pages read xxxx,created xxx,written xxx, xx reads/s, xx creates/s,1xx writes/s。已经读取、创建和写入了多少缓存页,以及每秒钟读取、创建和写入的缓存页数量。
(10)Buffer pool hit rate xxx /1000,这就是说每1000次访问,有多少次直接命中了 buffer pool 里的缓存的。
(11)young-making rate xxx / 1000 not xx / 1000, 每秒1000次访问,有多少次访问让缓存页从冷数据区域移动到了热数据区域,以及没移动的缓存页数量。
(12)LRU len:这就是lru 链表里的缓存页的数量
(13)I/O sum: 最近50s 读取磁盘页的总数
(14)I/O cur: 现在正在读取磁盘页的数量

若有收获,就点个赞吧
0 人点赞
