
0.2822019.03.31 14:56:52 字数 2,799 阅读 3,665
这一节我们介绍两个使用堆或者说基于堆的思想进行排序的算法。
思路 1:一个一个地往最大堆里面放元素,然后再一个一个地取出,倒序放置于一个空数组中,就完成了元素的排序;
思路 2:一次性把整个数组复制到一个新数组,通过新数组 heapify 操作,使得新数组成为一个最大堆,然后再一个一个地取出,倒序放置于一个空数组中,就完成了元素的排序。
思路 1:一个一个放进最大堆,再一个一个地取出完成排序
我们首先要明确的是,堆排序的时间复杂度是  #alt=)
#alt=)
。
我们可以从以下几个维度进行不同算法性能的比较,对数量级是 100 万个元素的数组进行排序。
使用的排序算法维度:归并排序,快速排序,三路快速排序,堆排序(借助额外空间的堆排序)。
元素特点维度:1、随机;2、近乎有序;3、含有大量相同元素的数组。
Java 代码:
public class HeapSort1 implements ISortAlgorithm {@Overridepublic String getName() {return "第 1 个版本的堆排序算法";}@Overridepublic void sort(int[] arr) {int length = arr.length;MaxHeap maxHeap = new MaxHeap(length);for (int i = 0; i < length; i++) {maxHeap.insert(arr[i]);}for (int i = length - 1; i >= 0; i--) {arr[i] = maxHeap.extractMax();}}}
我们在上一小节,介绍了将一个元素 insert 到最大堆中,和从最大堆中取出一个元素,仅仅通过这两个操作,就可以完成排序任务。方法很简单,把待排序数组中的元素全部 insert 到最大堆里,然后再一个一个取出来,因为我们要按照升序排序,因此从后向前放置从最大堆中拿出的元素。
这个方法有一个缺点,那就是要使用和数组元素个数相等的最大堆空间,即空间复杂度是  #alt=)
#alt=)
。
而这一节我们要介绍的是一种直接使用堆排序的 sink 方法完成排序任务的方法,这种方法仅使用  #alt=)
#alt=)
的空间复杂度,用于一个临时表变量的存储。
首先,我们介绍一个操作,名为 heapify 。
思路 2:一次性复制数组元素到新的数组,新数组自我调整成最大堆
什么是 Heapify
Heapify 是尝试将一整个数组构建成一个堆的方式,即通过调整自己,交换数组中的元素,就可以把自己整理成一个最大堆。
理解 Heapify 关键的部分
1、所有的叶子结点就是一个最大堆,此时每个堆中的元素只有 1 个;
2、当我们的索引从 1 开始计数的前提下,第 1 个非叶子的结点的索引是 index/2(自己画一个图,就可以看清楚这个规律,我们可以使用数学归纳法来证明),如何让它满足堆的性质呢? Shift Down 就可以了。
思考:我们为什么不用 Shift Up?
我的思考如下:如果使用 Shift Up 的话,那就得将数组中所有的元素都 Shift Up,相比于只用一半的元素 Shift Down 而言,工作量会少很多。
3、从 index/2 递减到根(index==1 的时候)依次去完成 Shift Down,一开始就排除了 length/2 这么多元素。
heapify
使得一个数组是堆有序的操作就叫做 “heapify”。具体的做法是:从最后一个非叶子结点开始到索引为 
的位置,逐个 sink。
在上一步 “堆排序” 中,我们注意到,有这样一个操作“把待排序数组按顺序放入一个堆(入队)”,这一步得一个接着一个按照顺序放入堆中,实际上,可以通过一个称之为 heapify 的操作,让这个数组自行调整成一个最大堆,即使之 “堆有序”,而此时无需借助 #alt=)
空间就完成了最大堆的构建。事实上,只需对数组中一半的元素执行 shift down 就可以了。
以下代码还是使用了 #alt=)
空间,主要是为了说明 heapify。
heapify 如下所示:从索引的 self.count // 2 位置开始,直到索引为
的元素结束,逐个下沉,就可以让一个数组堆有序。
说明:索引的 self.count // 2 位置是从下到上第 1 个非叶子结点的索引
Python 代码:
class MaxHeap:
def __init__(self, nums):
self.capacity = len(nums)
self.data = [None] * (self.capacity + 1)
self.count = len(nums)
self.__heapify(nums)
def __heapify(self, nums):
for i in range(self.capacity):
self.data[i + 1] = nums[i]
for i in range(self.count // 2, 0, -1):
self.__sink(i)
Java 代码:
public MaxHeap(int[] arr) {
int length = arr.length;
data = new int[length + 1];
for (int i = 0; i < length; i++) {
data[i + 1] = arr[i];
}
count = length;
for (int i = length / 2; i >= 1; i--) {
shiftDown(i);
}
}
这样,我们就可以写出我们的第 2 个使用堆排序的算法了,直接把数组传到最大堆这个数据结构里面。
heapify 以后挨个取出来,倒着放回去,也可以完成排序,就不用一个一个放进去,做上浮的操作了。整体上排序会比一个一个放进去快一些。
Java 代码:通过 heapify 将数组重组成最大堆实现的排序
public class HeapSort2 implements ISortAlgorithm {
@Override
public String getName() {
return "第 2 个版本的堆排序算法";
}
@Override
public void sort(int[] arr) {
MaxHeap maxHeap = new MaxHeap(arr);
int length = arr.length;
for (int i = length - 1; i >= 0; i--) {
arr[i] = maxHeap.extractMax();
}
}
}
重要结论:堆排序在整体上的性能不如归并排序和快速排序。但是,堆这种数据结构更多的时候用于动态数据的维护。
一个数学结论:将 
个元素逐一插入到一个空堆中,时间复杂度是 #alt=)
。Heapify 的过程,时间复杂度是 #alt=)
。
HeapSort2 会快一点的原因是:一上来我们从 n/2 这个地方开始,逐一操作,排除了 n/2 个元素,所以效率肯定比第 1 种好。
可是这两种基于堆的排序算法,我们在堆排序的过程中,使用了额外的空间(即 MaxHeap 中的数组),使用了 #alt=)
的空间复杂度。那么不借助额外的空间是不是也可以完成堆排序呢?这就是我们下一节要介绍的内容——原地堆排序。
原地堆排序
通过上一节的学习,我们知道一个数组通过 heapify 操作,即通过一半的元素执行 Shift Down 的操作可以逐渐地整理成一个最大堆。
我们把 “原地堆排序” 拆解为以下 3 个部分:
1、首先,转换思维,堆从索引
开始编号;
代码很多地方都要改,好在并不复杂,正好可以帮助我们复习堆的 sink 操作,如果只是用于排序任务,不需要 swim 操作;
2、 sink 操作要设计成如下的样子,设计一个表示 end 的变量,表示待排序数组的 [0, end](注意是闭区间)范围是堆有序的。
上一节我们将一个数组通过 heapify 的方式逐渐地整理成一个最大堆。而原地堆排序的思想是非常直观的,从 shift down 的操作我们就可以得到启发,堆中最大的那个元素在数组的 0 号索引位置,我们把它与此时数组中的最后一个元素交换,那么数组中最大的元素就放在了数组的末尾,此时再对数组的第一个元素执行 shift down,那么 shift down 操作都执行完以后,数组的第 1 个元素就存放了当前数组中的第 2 大的元素。依次这样做下去,就可以将一个数组进行排序。
理解这个原理的关键之处:对堆顶元素执行了 Shift Down 操作以后,就会把这个堆中的最大的元素挪到堆顶。
此时,因为用到了索引,并且须要用到索引为
的数组元素,因此我们就要将最大堆中数组的索引从
开始计算,重新写一套堆的 API。
我们整理一下,其实这个思想跟 “选择排序” 是一样的,只不过我们每一轮选出一个当前未排定的数中最大的那个,即 “选择排序”+“堆” 就是“堆排序”。

image
“堆排序” 代码实现的注意事项:
1、此时最大堆中数组的索引从
开始计算。与之前索引从 
开始的最大堆实现比较,性质就发生了变化,但并不会不好找,我们可以自己在纸上画一个完全二叉树就可以很清晰地发现规律: %3D%5Ccfrac%7Bi-1%7D%7B2%7D#alt=)
%3D%5Ccfrac%7Bi-1%7D%7B2%7D#alt=)
, %20%3D%202%20%5Ctimes%20i%20%2B1#alt=)
%20%3D%202%20%5Ctimes%20i%20%2B1#alt=)
, %20%3D%202%20%5Ctimes%20i%20%2B2#alt=)
%20%3D%202%20%5Ctimes%20i%20%2B2#alt=)
,最后一个非叶子结点的索引是:
;
2、原地堆排序,因为索引从
号开始,相应的一些性质在索引上都发生变化了;
3、注意到我们只有 shift down 的操作,对于 shift down 的实现,一些细节就要很小心,shift down 是在一个区间内进行的,我们在设计新的 shift down 方法的实现的时候,应该设计待排序数组区间的右端点。
Python 代码:
def __sink(nums, end, k):
assert k <= end
temp = nums[k]
while 2 * k + 1 <= end:
t = 2 * k + 1
if t + 1 <= end and nums[t] < nums[t + 1]:
t += 1
if nums[t] <= temp:
break
nums[k] = nums[t]
k = t
nums[k] = temp
def __heapy(nums):
l = len(nums)
for i in range((l - 1) // 2, -1, -1):
__sink(nums, l - 1, i)
def heap_sort(nums):
l = len(nums)
__heapy(nums)
for i in range(l - 1, 0, -1):
nums[0], nums[i] = nums[i], nums[0]
__sink(nums, i - 1, 0)
Java 代码:
public class HeapSort3 implements ISortAlgorithm {
@Override
public String getName() {
return "原地堆排序";
}
@Override
public void sort(int[] arr) {
int length = arr.length;
for (int i = (length - 1) / 2; i >= 0; i--) {
shiftDown(arr, length, i);
}
for (int i = length - 1; i > 0; i--) {
swap(arr, 0, i);
shiftDown(arr, i, 0);
}
}
private void shiftDown(int[] arr, int up, int index) {
while (2 * index + 1 < up) {
int j = 2 * index + 1;
if (j + 1 < up && arr[j] < arr[j + 1]) {
j = j + 1;
}
if (arr[index] < arr[j]) {
swap(arr, index, j);
index = j;
} else {
break;
}
}
}
private void swap(int[] arr, int index1, int index2) {
int temp = arr[index1];
arr[index1] = arr[index2];
arr[index2] = temp;
}
}
说明:首先进行一次 heapify 的过程:从索引为
的结点开始执行 Shift Down。heapify 过程的代码框架几乎是套路,一定要熟悉,只不过我们要弄清楚,我们的最大堆是从索引为
的位置开始存放元素,还是从索引为
的地方开始存放元素。
for (int i = (length - 1) / 2; i >= 0; i--) {
shiftDown(arr, length, i);
}
到此为止,堆的排序算法就已经介绍完了,下面我们对之前学习过的排序算法作一个总结。
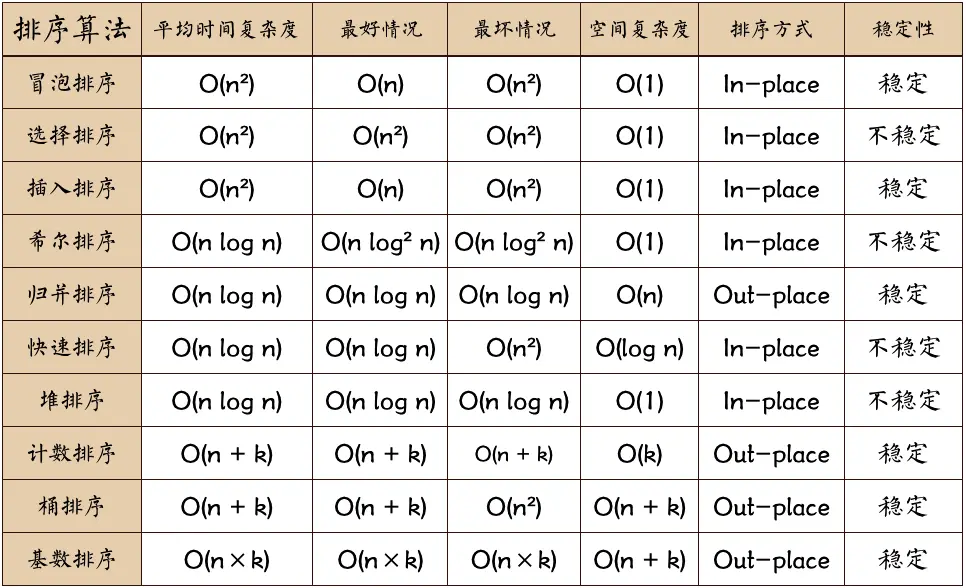
排序算法总结
平均时间复杂度
时间复杂度分为平均时间复杂度、最好时间复杂度和最坏时间复杂度。对于一个算法来说,往往有很多特殊情况,一般而言,我们所说的时间复杂度都指最坏时间复杂度。
对我们学习过的各种排序算法的总结和对比
快速排序相对会更快一些。一般系统级别的排序,是用快速实现的。如果有大量重复键值,可以使用三路快排。
排序算法的稳定性
查资料了解什么是排序算法的稳定性。可以通过自定义比较函数,让排序算法不存在稳定性问题。系统级别的排序算法,如果要求稳定性的话,一般使用归并排序。
对未来的探索
是不是存在一种神秘的排序算法?让所有指标达到最优呢。liuyubobobo 老师告诉我们,目前还没有。
本文源代码
(本节完)
更多精彩内容,就在简书 APP
“小礼物走一走,来简书关注我”
还没有人赞赏,支持一下

李威威欢迎大家关注我的公众号「算法不好玩」,我讲解的算法特别好懂。B 站:liweiwei1419。
总资产 9 共写了 27.7W 字获得 179 个赞共 262 个粉丝
推荐阅读更多精彩内容
这部分我们介绍一种新的数据结构堆(Heap),“堆”是实现 “优先队列” 的一个高效的数据结构。首先,我们来认识“优先…

李威威阅读 309 评论 0 赞 0
索引堆是一个相对于普通堆更加高级的数据结构。 为什么要引入索引堆这个数据结构? 在一些场景下,堆这个数据结构不高效…
李威威阅读 510 评论 0 赞 1
本文首发于我的个人博客:尾尾部落 排序算法是最经典的算法知识。因为其实现代码短,应该广,在面试中经常会问到排序算法…

繁著阅读 4,014 评论 3 赞 119
参考:十大经典排序算法 0、排序算法说明 0.1 排序的定义 对一序列对象根据某个关键字进行排序。 0.2 术语说明…
Tyger 回答:家长您好。英语不可能见词能读,更不可能听音能写。到目前为止,英语词汇量已经突破 100 万,试问有谁能…
写作,非特定人群的特定行为,它只是人类表达自我的方式之一。 对于写作,从小就有两件事是我百思不得其…

梁司弦阅读 288 评论 0 赞 1
思念一滴滴注入白日的碗 映出你模糊的脸 不料却被黑夜的手翻转 清晨醒来如婴儿般慵懒 就像我们刚刚遇见
https://www.jianshu.com/p/f40a0e945b58

若有收获,就点个赞吧
0 人点赞
