目录
5. 可观察性 (Observability) 终极方案:OpenTelemetry?
1. 背景
随着应用容器化和微服务的兴起,借由 Docker 和 Kubernetes 等工具,服务的快速开发和部署成为可能,构建微服务应用变得越来越简单。但是随着大型单体应用拆分为微服务,服务之间的依赖和调用变得极为复杂,这些服务可能是不同团队开发的,可能基于不同的语言,微服务之间可能是利用 RPC、RESTful API,也可能是通过消息队列实现调用或通讯。
如何理清服务依赖调用关系、如何在这样的环境下快速 debug、追踪服务处理耗时、查找服务性能瓶颈、合理对服务的容量评估都变成一个棘手的事情。
【无分布式追踪系统】 VS 【有分布式追踪系统】对比示意图如下:
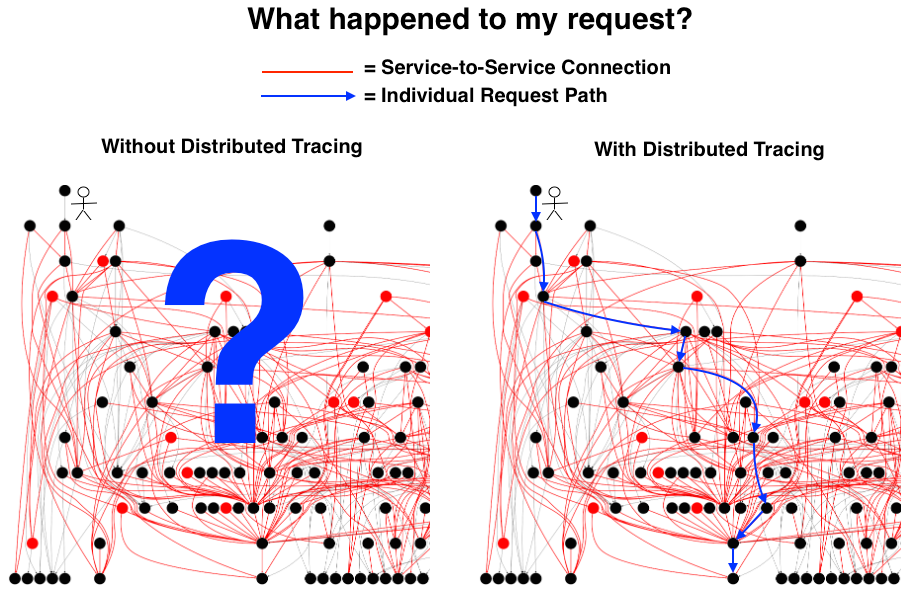
为了应对这些问题,可观察性 (Observability) 这个概念被引入软件领域。传统的监控和报警主要关注系统的异常情况和失败因素,可观察性更关注的是从系统自身出发,去展现系统的运行状况,更像是一种对系统的自我审视。一个可观察的系统中更关注应用本身的状态,而不是所处的机器或者网络这样的间接证据。我们希望直接得到应用当前的吞吐和延迟信息,为了达到这个目的,我们就需要合理主动暴露更多应用运行信息。在当前的应用开发环境下,面对复杂系统我们的关注将逐渐由点到点线面体的结合,这能让我们更好的理解系统,不仅知道 What,更能回答 Why。
可观察性目前主要包含以下三大支柱:日志 (Logging)、度量 (Metrics)、分布式追踪 (Tracing)
- 日志 (Logging):Logging 主要记录一些离散的事件,应用往往通过将定义好格式的日志信息输出到文件,然后用日志收集程序收集起来用于分析和聚合。目前已经有 ELK 这样的成熟方案, 相比之下日志记录的信息最为全面和丰富,占用的存储资源正常情况下也最多,虽然可以用时间将所有日志点事件串联起来,但是却很难展示完整的调用关系路径;
- 度量 (
Metrics):Metric往往是一些聚合的信息,相比Logging丧失了一些具体信息,但是占用的空间要比完整日志小的多,可以用于监控和报警,在这方面 Prometheus 已经基本上成为了事实上的标准; - 分布式追踪 (
Tracing):Tracing介于Logging和Metric之间, 以请求的维度,串联服务间的调用关系并记录调用耗时,即保留了必要的信息,又将分散的日志事件通过 Span 串联, 帮助我们更好的理解系统的行为、辅助调试和排查性能问题,也是本文接下来介绍的重点。
事实上,目前 Logging,Metrics 和 Tracing 既各自有其专注的部分,也有相互重叠的部分,现在很多流行的 APM (应用性能管理) 系统,如 Datadog 就融合了 Tracing 和Metric 信息。这里不展开说明,感兴趣的话可以上网查下。
下面是CNCF(云原生计算基金会)**总结的当前流行的实现可观察性系统的常见软件或服务 **,Monitoring 栏中以 Prometheus 为代表,本身可以实现 Metric 的收集监控,不过结合图中其他工具可以实现更加强大和完善的监控方案。

2.分布式追踪系统 **(Tracing)** 定位及其标准
Tracing 的功能定位:
- 故障定位——可以看到请求的完整路径,相比离散的日志,更方便定位问题(由于真实线上环境会设置采样率,可以利用 debug 开关实现对特定请求的全采样);
- 依赖梳理——基于调用关系生成服务依赖图;
- 性能分析和优化——可以方便的记录统计系统链路上不同处理单元的耗时占用和占比;
- 容量规划与评估;
- 配合
Logging和Metric强化监控和报警。
最早由于 Google 的论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,让 Tracing 流行起来。而 Twitter 基于这篇论文开发了 Zipkin 并开源了这个项目。再之后业界百花齐放,诞生了一大批开源和商业 Tracing 系统。
OpenTracing 标准:
由于近年来各种链路监控产品层出不穷,当前市面上主流的工具既有像 Datadog 这样的一揽子商业监控方案,也有 AWS X-Ray 和 Google Stackdriver Trace 这样的云厂商产品,还有像 Zipkin、Jaeger 这样的开源产品。
尽管分布式追踪系统发展很快,种类繁多,但核心步骤一般有三个: 代码埋点, 数据存储、 查询展示。但在数据采集过程中,由于需要侵入用户代码,并且不同系统的 API 并不兼容,这就导致了如果您希望切换追踪系统,往往会带来较大改动,出现了痛点,就会有人解决,为了解决不同的分布式追踪系统 API 不兼容的问题,诞生了 OpenTracing 规范,Opentracing 也正是为了解决这样的痛点。
- OpenTracing 进入 CNCF,正在为全球的分布式追踪,提供统一的概念和数据标准。
- OpenTracing 通过提供平台无关、厂商无关的 API,使得开发人员能够方便的添加(或更换)追踪系统的实现。
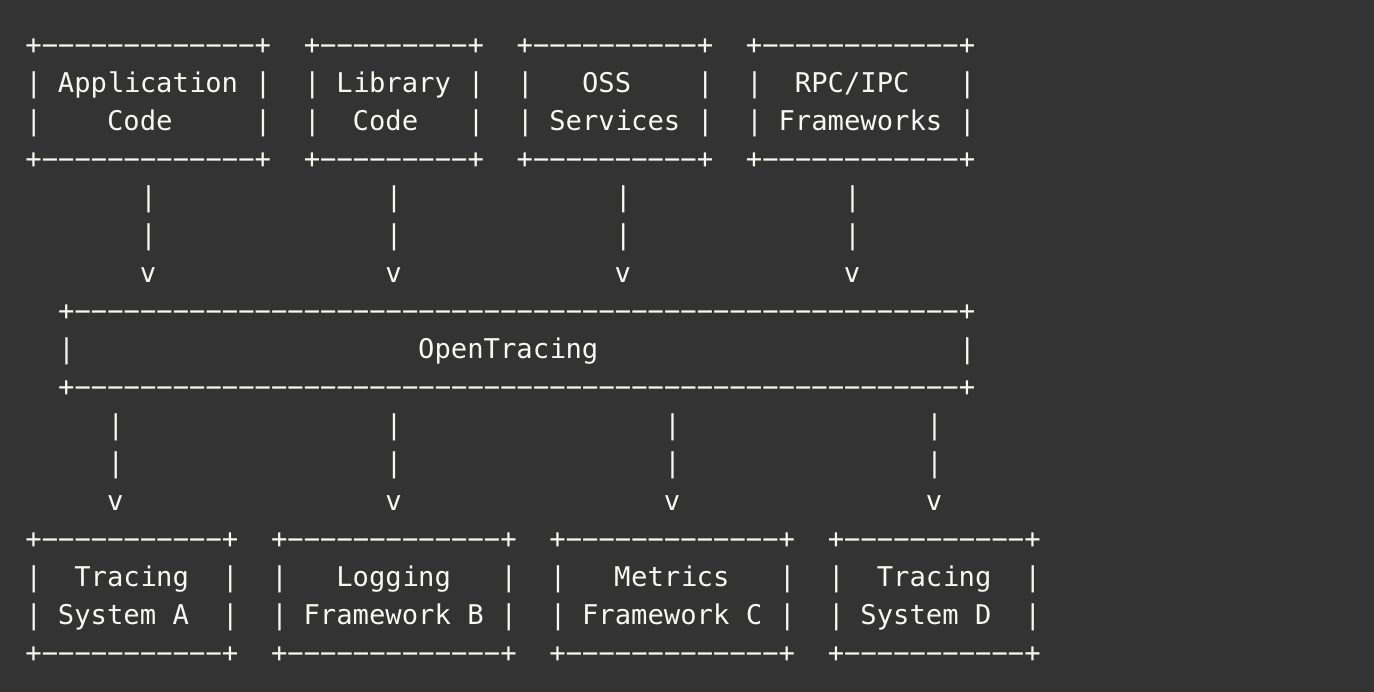
也就是说,遵从 Opentracing 的规范,就相当于在应用程序 / 类库和追踪或日志分析程序之间定义了一个轻量级的标准化层,解耦了代码和 Tracing API。
在OpenTracing中,主要定义以下基本概念:
- Trace(调用链): OpenTracing 中的 Trace(调用链)通过归属于此调用链的 Span 来隐性的定义。一条 Trace(调用链)可以被认为是一个由多个 Span 组成的有向无环图(DAG 图), Span 与 Span 的关系被命名为 References;
- Span(跨度):可以被翻译为跨度,可以被理解为一次方法调用,一个程序块的调用,或者一次 RPC / 数据库访问,只要是一个具有完整时间周期的程序访问,都可以被认为是一个 span。
单个 Trace 中,Span 间的因果关系:
[Span A] ←←←(the root span)[Span B] [Span C] ←←←(Span C 是 Span A 的孩子节点, ChildOf) [Span E] [Span F] >>> [Span G] >>> [Span H] (Span G 在 Span F 后被调用, FollowsFrom)
每个Span包含的操作名称、开始和结束时间、附加额外信息的Span Tag、可用于记录Span内特殊事件Span Log、用于传递Span上下文的SpanContext和定义Span之间关系References。
3.目前主流开源方案及对比
目前比较主流的Tracing开源方案有Jaeger、Zipkin、Apache SkyWalking、CAT、Pinpoint、Elastic APM等,这些项目源代码现在都托管在Github上。
Ps:表格整理时间为2019年6月,来自:狐友技术团队
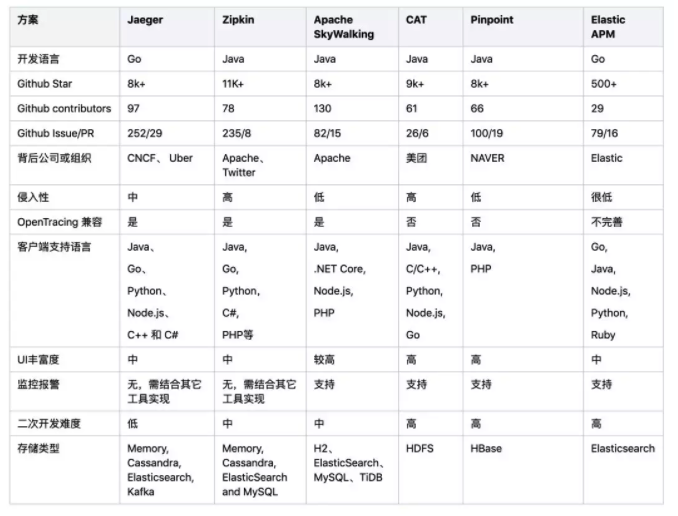
在现有系统引入时需要考虑以下因素:
- 低性能损耗
- 应用级的透明,尽量减少业务的侵入,目标是尽量少改或者不用修改代码
- 扩展性
技术方案选型时可参考:
- 如果是偏向于Java栈的应用,对跨语言和定制化需求低,可以优先考虑侵入性低的 Apache SkyWalking,该项目是国人主导,有较多的公司在使用;
- 考虑多语言支持、定制化和高扩展,优先选用 Jaeger(Jaeger 与Zipkin 比较类似,且兼容Zipkin原始协议,相比之下Jaeger 有一定的后发优势),Jaeger 和Zipkin相对于其它方案,更专注与Tracing本身,监控功能比较弱;
- 偏向于纯Web应用,无需定制化且已经有搭建好的ELK日志系统可以考虑低成本的接入 Elastic APM;
- CAT 基于日志全量采集指标数据,对于大规模的采集有一定优势,且集成了完善的监控报警机制,国内使用的公司多,但其不支持 OpenTracing;
- Pinpoint最主要的特点是侵入性低,拥有完整的APM和调用链跟踪功能,但是当前仅支持Java和PHP,也不支持 OpenTracing标准。
4.Jaeger简单介绍与使用示例
(1)Jaeger简单介绍
Jaeger 是Uber开发的一套分布式追踪系统,实现了opentracing的规范,对Tracer与Span等接口写了自己的实现,是CNCF的开源项目,先来看看Jaeger的架构图。
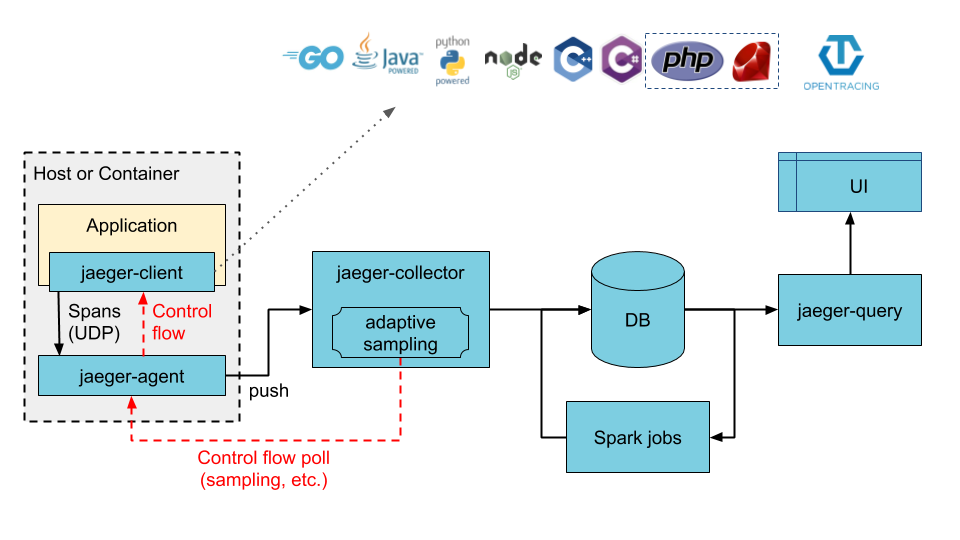
各模块作用描述如下:
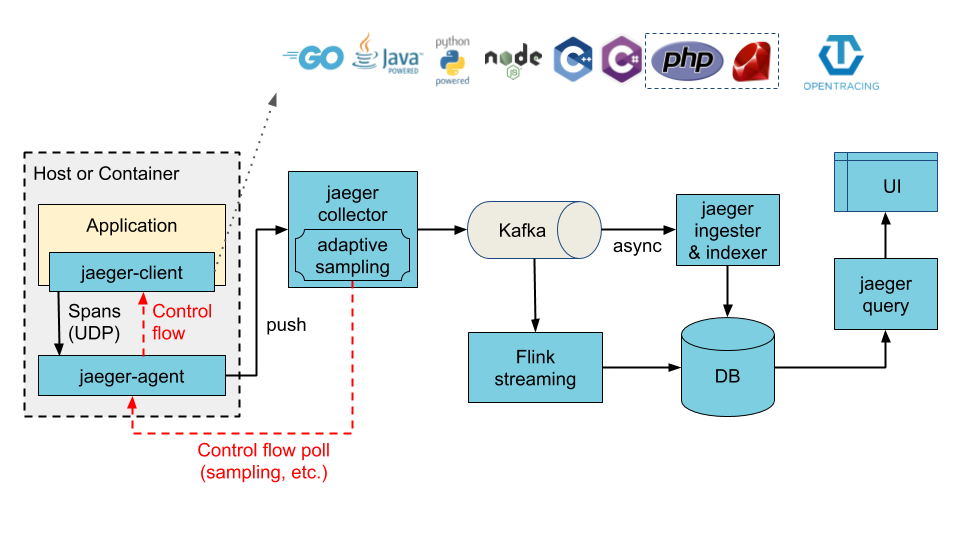
Jaeger Client - 为不同语言实现了符合 OpenTracing 标准的 SDK。应用程序通过 API 写入数据,client library 把 trace 信息按照应用程序指定的采样策略传递给 jaeger-agent。
Agent - 它是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。它被设计成一个基础组件,部署到所有的宿主机上。Agent 将 client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节。
Collector - 接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。Collector 被设计成无状态的组件,因此您可以同时运行任意数量的 jaeger-collector。
Data Store - 后端存储被设计成一个可插拔的组件,支持将数据写入elasticsearch、cassandra。
Query - 接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示。Query 是无状态的,您可以启动多个实例,把它们部署在 nginx 这样的负载均衡器后面。
当处理的数据量很大的时候,jaeger-collector就会面临着一些性能的瓶颈,无法及时存储 jaeger-agent 发送来的数据,因此官方也支持使用kafka做为缓冲区,下面是架构图:
(2)Jaeger基本使用
为了方便大家快速使用,Jaeger直接提供一个All in one的docker镜像,通过All in one的image,我们可以通过以下命令直接启动一套完整的Jaeger tracing系统,例如本地docker机器执行如下命令:
$ docker run -d -e COLLECTOR_ZIPKIN_HTTP_PORT=9411 -p 5775:5775/udp -p 6831:6831/udp -p 6832:6832/udp -p 5778:5778 -p 16686:16686 -p 14268:14268 -p 14269:14269 -p 9411:9411 jaegertracing/all-in-one:latest
一旦启动成功后,就可以去 http://localhost:16686 看到Jaeger UI了,如下所示。
Ps:在All in one模式下,Data Store使用的是内存,因此若重启dockre容器后就看不到之前的数据了。所以,该模式仅可用于前期demo或者验证,不可在生产环境中这样部署。 生产环境可以使用独立部署,用Elasticsearch、Cassandra作为存储,详细的部署方式可上网查询。
端口说明:
通过上述All in one启动方式,我们直接发现了Jaeger启动时占据了很多端口,当然,并不是所有的端口都是必需的,这儿简单列出这些端口的说明如下:
5775 UDP agent 通过兼容性Thrift协议,接收Zipkin thrift类型数据6831 UDP agent 通过兼容性Thrift协议,接收Jaeger thrift类型数据6832 UDP agent 通过二进制Thrift协议,接收Jaeger thrift类型数据16686 HTTP query 客户端前端界面展示端口14268 HTTP collector 接收客户端Zipkin thrift类型数据14267 HTTP collector 接收客户端Jaeger thrift类型数据9411 HTTP collector Zipkin兼容endpoint
当我们正是使用jager后,可以通过两种方式来进行查看数据:
根据TraceId搜索: 通过Web UI上方搜索框,可以直接键入TraceId进行某次trace的搜索。
根据服务节点查看: 通过Web UI 上方Search Tab,可以详细地进行高级搜索功能,支持服务名,操作,Tag信息(Jaeger中的tag功能,可以在context中加入tag,进行更过的标识)等。当我们确定搜索条件后,就可以查出符合条件的trace信息了。
下面给一个完整基于opentracing+jaeger+Flask实现的的分布式追踪demo示例,完整的示例代码免费下载地址:https://download.csdn.net/download/sinat_33718563/33257326(额,CSDN文章好像不能直接上传附件,这个不需要积分哈),代码结构:
代码文件启动说明如下:
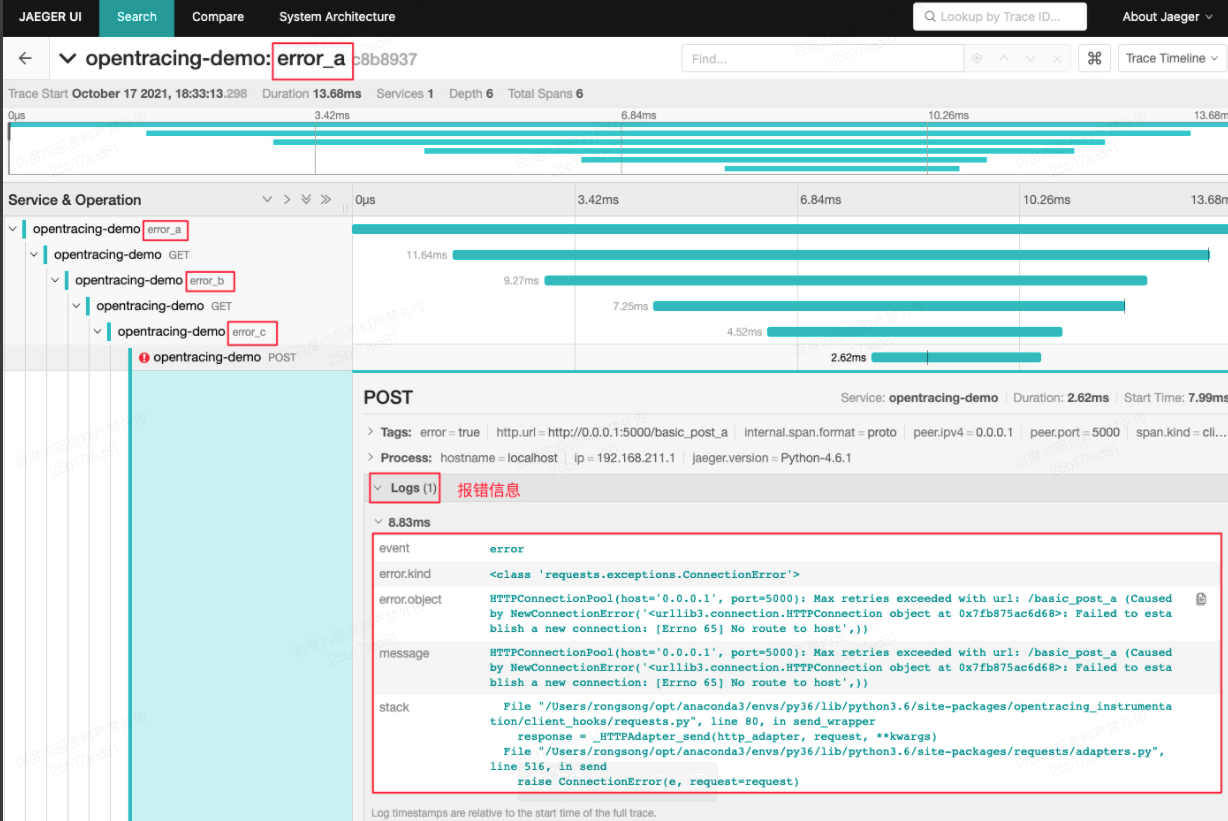
基于opentracing+jaeger+Flask的demo示例前提条件:同机已部署jaeger整个All-in-one框架,实际在Docker下一行命令即可,注意这只是个测试环境安装方式参考文档5.1处:https://cloud.tencent.com/developer/article/1160850 pip3 install -r requirements.txt(2)依次启动各个service_a、service_b、service_c测试服务 python3 flask_service_a.py python3 flask_service_b.py python3 flask_service_c.py 成功的请求,终端执行命令:curl http://0.0.0.0:5000/success_a 失败的请求,终端执行命令:curl http://0.0.0.0:5000/error_a "data": "HTTPConnectionPool(host='0.0.0.1', port=5000): Max retries exceeded with url: /basic_post_a (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7fb875ac6d68>: Failed to establish a new connection: [Errno 65] No route to host',))",(4)打开Jaeger页面,预期会有2个请求trace日志Ps:服务名字默认用的opentracing-demo,可以在./utils/jaeger_utils.py中更改
Docker环境下,jaeger整个All-in-one框架正常运行:
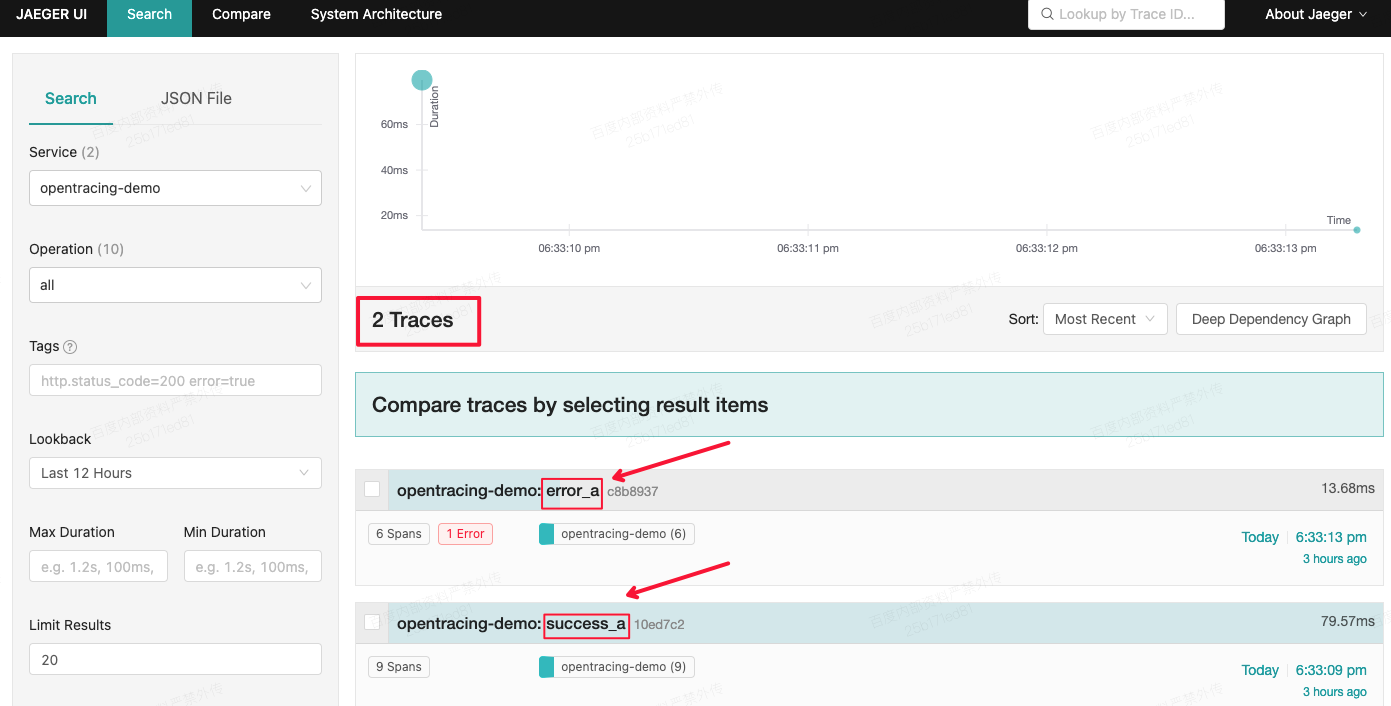
打开:http://localhost:16686/search,上述发送2个请求测试后(第三步),正常情况会有2条trace信息,如下:
- 整体情况
点击成功请求success_a的trace日志,没有打印错误日志
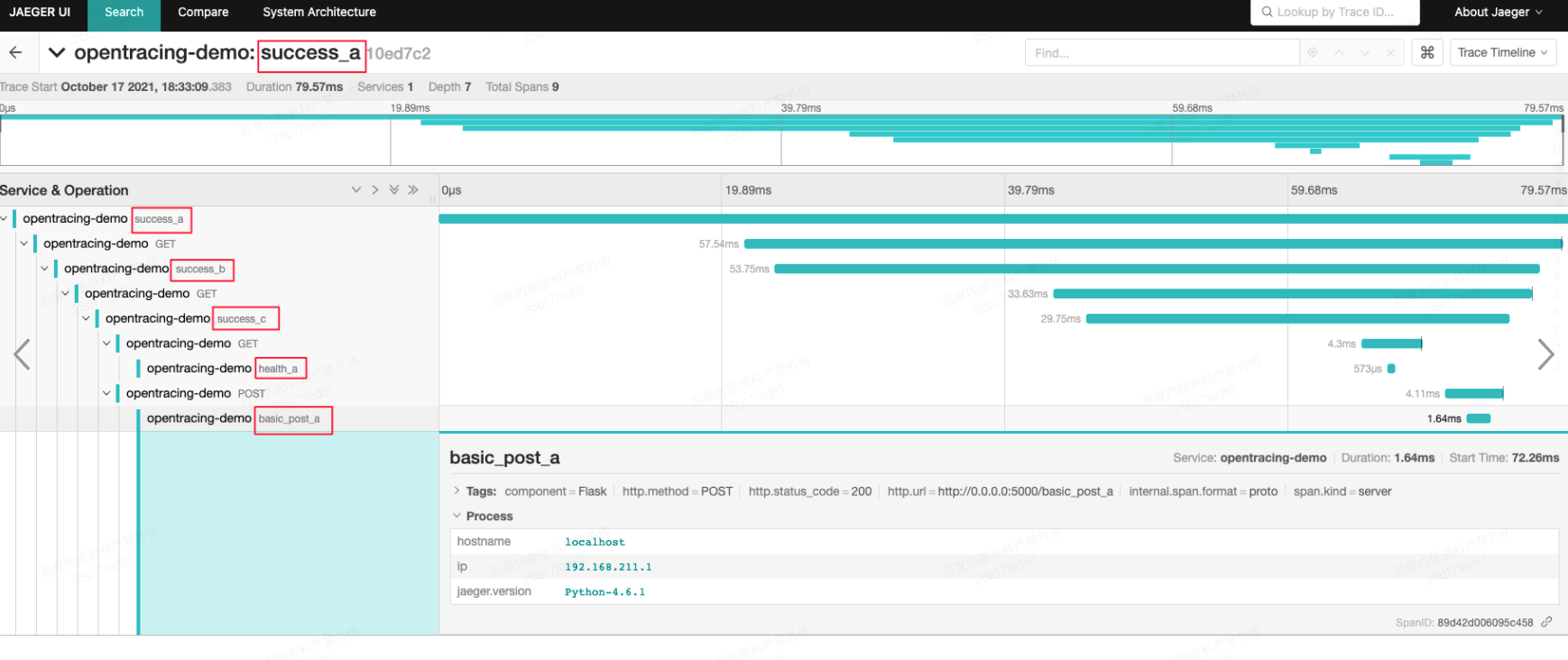
点击成功请求error_a的trace日志,有打印错误日志
(3)Jaeger官方示例—HotROD
上面的示例太简单了?那么我们一起来看下官方给的示例:HotROD,官方文档地址:jaeger/examples/hotrod at master · jaegertracing/jaeger · GitHub
在根目录下,使用源码方式启动:(当然也可以使用Docker方式启动,见上述链接)
go run ./examples/hotrod/main.go all
Linking to traces:HotROD已经很好的实现了和Jaeger UI的trace交互,即:HotROD可以追踪HotROD所有被执行的请求链路信息,本地默认Jaeger UI的启动地址为:http://localhost:16686,当然你也可以自定义指定,方式如下:
go run ./examples/hotrod/main.go all -j http:
Hot ROD本地成功启动后打开:http://127.0.0.1:8080/
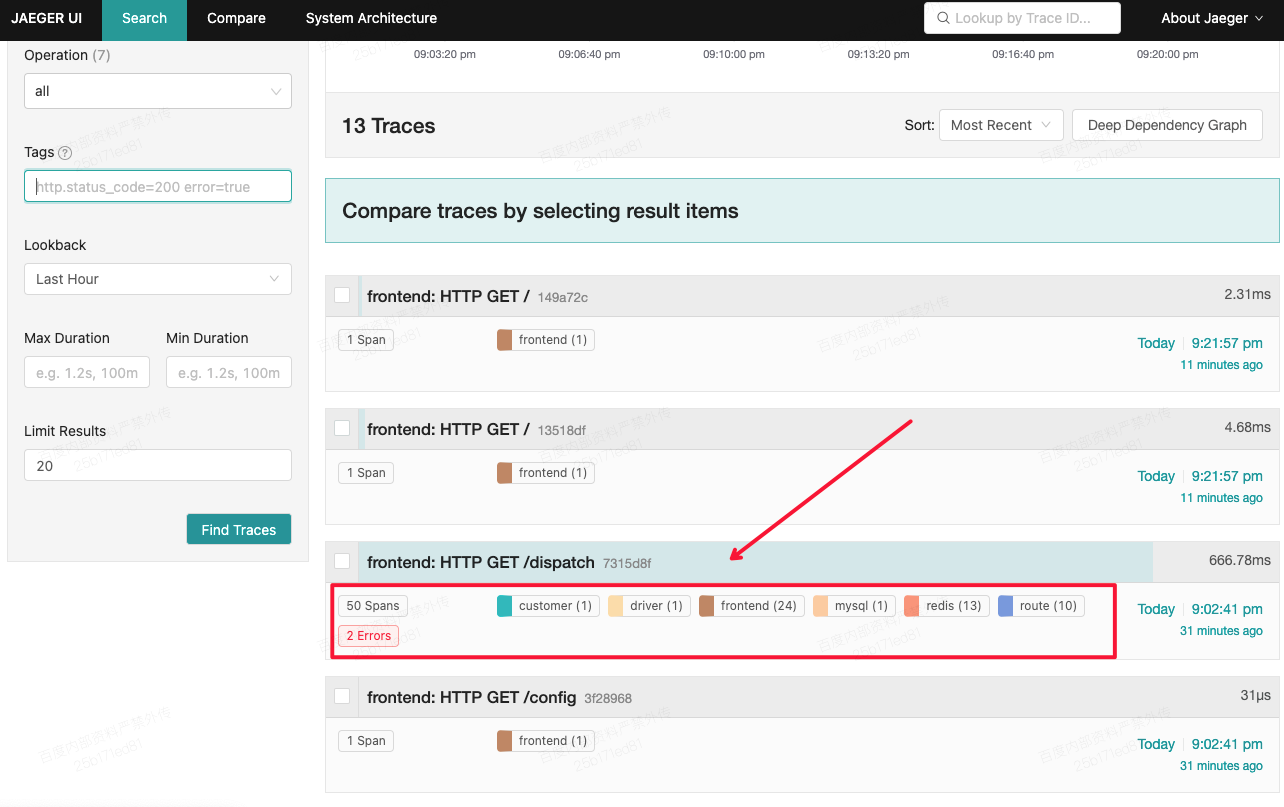
 可以在上面的页面上执行各种点击操作(发送请求),然后打开本地的Jaeger UI:http://localhost:16686,此时应该可以看到相对比较丰富的请求trace日志,示例如下所示:
可以在上面的页面上执行各种点击操作(发送请求),然后打开本地的Jaeger UI:http://localhost:16686,此时应该可以看到相对比较丰富的请求trace日志,示例如下所示:
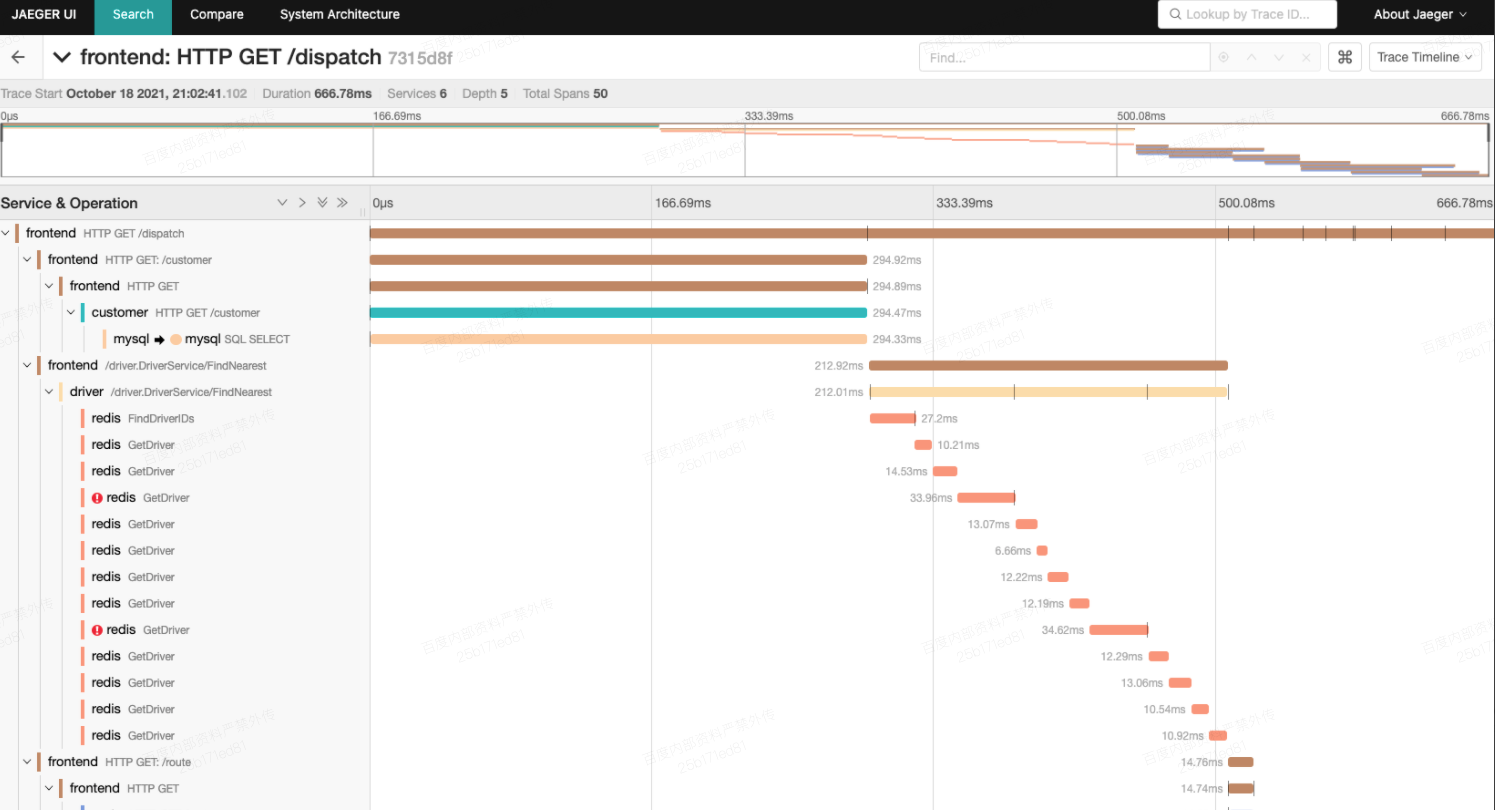
这里有很多细节说明,详情可参考:https://www.yuque.com/wangzhe0912/jaeger/cct3q2,基本来自官方文章的翻译。
5.可观察性(Observability) 终极方案:OpenTelemetry?
前面也提到了,可观察性目前主要包含以下三大支柱:日志(Logging)、度量(Metrics)、分布式追踪(Tracing)。OpenTelemetry的终极目标:实现Metrics、Tracing、Logging的融合及大一统,作为APM(Application Performance Monitoring)的数据采集终极解决方案。OpenTelemetry的诞生要归根于OpenTracing和OpenCensus这两个项目,详细的背景可以参考:OpenTelemetry-结束分布式追踪的江湖之乱,不过当前这个方案还在实验阶段,距离实际生产可用可能还需要一段时间。(当前时间2021-10-19)
OpenTelemetry的终极目标方案:
- Tracing:提供了一个请求从接收到处理完成整个生命周期的跟踪路径,一次请求通常过经过N个系统,因此也被称为分布式链路追踪
- Metrics:例如cpu、请求延迟、用户访问数等Counter、Gauge、Histogram指标
- Logging:传统的日志,提供精确的系统记录
这三者的组合可以形成大一统的APM解决方案:
- 基于Metrics告警发现异常
- 通过Tracing定位到具体的系统和方法
- 根据模块的日志最终定位到错误详情和根源
- 调整Metrics等设置,更精确的告警/发现问题
该如何融合?
在以往对APM的理解中,这三者都是完全独立的,但是随着时间的推移,人们逐步发现了三者之间的关联,例如我们可以把Tracing的TraceID打到Logging的日志中,这样可以把分布式链路跟踪和日志关联到一起,彼此数据互通,但是还存在以下问题:
- 如何把Metrics和其他两者关联起来
- 如何提供更多维度的关联,例如请求的方法名、URL、用户类型、设备类型、地理位置等
- 关联关系如何一致,且能够在分布式系统下传播
在OpenTelemetry中试图使用Context为Metrics、Logging、Tracing提供统一的上下文,三者均可以访问到这些信息,同时Context可以随着请求链路的深入,不断往下传播
- Context数据在Task/Request的执行周期中都可以被访问到
- 提供统一的存储层,用于保存Context信息,并保证在各种语言和处理模型下都可以工作(例如单线程模型、线程池模型、CallBack模型、Go Routine模型等)
- 多种维度的关联基于元信息(标签)实现,元信息由业务确定,例如:通过Env来区别是测试还是生产环境等
- 提供分布式的Context传播方式,例如通过W3C的traceparent/tracestate头、GRPC协议等
参考 :

若有收获,就点个赞吧
0 人点赞
