链表的存储结构
与数组存储结构的区别在于:
- 数组:需要一块连续的内存空间
- 链表:用指针将一组零散的内存块串联起来使用

若我们申请一个100MB大小的数组,当内存中没有连续、足够大的存储空间,即便内存剩余总可用空间大于100MB,仍会申请失败。而链表就不会有这个问题。
单链表

链表通过指针将一组零散的内存款串联在一起,其中:
- 结点:内存块(图中的data+next)。
- 后继指针(next):记录下一个结点地址的指针。
- 头结点:第一个结点,记录链表基地址,可以通过它遍历得到整条链表。
- 尾结点:指针不指向下个结点,指向空地址
NULL。
单链表各项操作时间复杂度:
- 插入、删除数据:不需要保持内存连续性,所以不需要搬移结点。仅需考虑相邻节点的指针改变,因此时间复杂度为
O(1)。 - 查找:数据非连续存储,需要通过指针一个个遍历。时间复杂度为
O(n)。

循环链表
循环链表是一种特殊的单链表。
与单链表的区别:
- 单链表的尾结点指针,指向空地址。
- 循环链表尾结点指针,指向链表的头结点。

循环链表的优点是从链尾到链头方便。
当处理的数据具有环形结构的特点时,就适合采用循环链表,如 约瑟夫问题 。
双向链表
与单链表的区别:
- 单链表是单方向的,结点只有一个 后继指针 next 指向后面的结点。
- 双向链表除了拥有后继指针,还有一个 前驱指针 prev 指向前面的结点。

双向链表需要额外的两个空间来存储 后继结点、前驱结点 的地址。但它支持双向遍历。
因此支持 O(1) 时间复杂度的情况下找到前驱结点。
双向循环链表
循环链表与双向链表的整合,就是双向循环链表。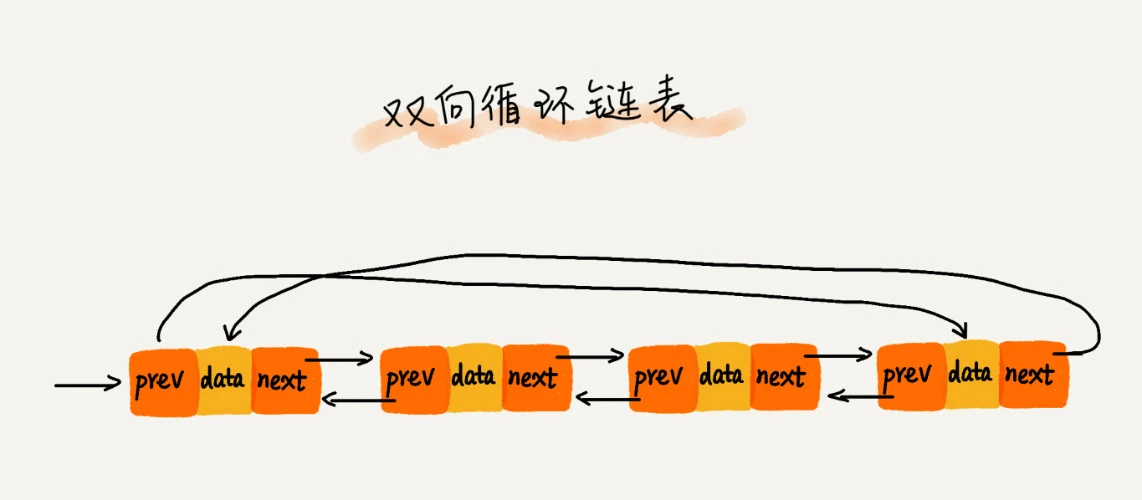
单链表与双向链表的操作区别
前面提到了单链表的插入、删除操作的时间复杂度为 O(1)。但那仅仅指 删除/插入 这个操作本身。
操作区别 - 删除
在实际开发中,从链表中删除数据有以下两种情况:
- 删除某个 “值等于某个给定值” 的结点。
- 删除 “给定指针指向” 的结点。
第一种情况:
无论单链表还是双向链表,都需要从头遍历,直到找到要删除的结点。
尽管单纯的删除时间复杂度为 O(1),但遍历查找的时间复杂度为 O(n)。
根据时间复杂度分析中的加法法则,第一种情况的总时间复杂度为 O(n)。
第二种情况:
我们已经知道要删除的结点,但删除该结点还需要知道它的前驱结点。
单链表不支持向前查找,所以还是需要从头遍历。时间复杂度为 O(n)。
双向链表支持向前查找,我们可以轻易得知前驱结点,不需要从头遍历。时间复杂度为 O(1)。
操作区别 - 查找
对于一个有序列表,双向链表的按值查询的效率也要比单链表高。
假设上次查找的结点值为 a,查一个新的值为 b。若 b < a(即 b 在 a 的前面):
单链表只能向后查找。
而双向链表可以根据 b 的大小选择往后还是往前查找,平均仅需查找一半的数据。
设计思想 - 时间、空间兑换
- 空间换时间:对于执行慢的程序,可以通过消耗更多内存来优化。例如缓存。
- 时间换空间:对于消耗内存过多的程序,可以通过消耗更多时间来降低内存消耗。例如代码跑在手机上。
链表 VS 数组性能
数组与链表的内存组织方式截然不同,因此他们操作的时间复杂度相反。
| 数组 | 链表 | |
|---|---|---|
| 访问效率 | 访问效率高。使用连续的内存空间,可以借助CPU的缓存机制。 | 访问效率一般。 非连续存储,对CPU缓存不友好。 |
| 大小 | 数组大小固定。占用整块连续内存,容易造成内存不足。 | 无大小限制,天然支持动态扩容 |
| 占用空间 | 整块连续内存。 | 每个结点需要额外空间存储指向下个结点的指针。 频繁的插入删除还会导致频繁的内存申请和释放,易造成内存碎片。 |
LRU 缓存淘汰算法
缓存策略
缓存是一种提高数据读取性能的技术,比如常见的 CPU 缓存、数据库缓存、浏览器缓存等。
缓存大小有限,当缓存用满时,哪些数据应该清理和保留?因此需要缓存策略:
- 先进先出策略 FIFO(First In, First Out)
- 最少使用策略 LFU (Least Frequently Used)
- 最近最少使用策略 LRU(Least Recently Used)
链表实现 LRU 缓存淘汰算法
其中, LRU缓存淘汰算法是链表的经典应用场景。我们如何使用链表实现一个 LRU 呢?
我们维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。
当一个新的数据被访问时,我们从链表头开始遍历:
- 若数据已经在缓存链表中,我们遍历得到这个数据对应的结点,将其从原来位置删除,插入链表头部。
- 若此数据没有在缓存链表中,分为两种情况:
- 若此时缓存未满,将此结点插入链表头部。
- 若此时缓存已满,则链表尾结点删除,将新数据插入链表头部。
至此,就用链表实现了一个LRU缓存。用此思路实现的,缓存访问的时间复杂度为 O(n)。
实际上,我们可以继续优化这个实现思路,比如引入散列表记录每个数据的位置,时间复杂度就能降为 O(1)。
如何正确写出链表代码?
1. 理解指针或引用的含义
无论是 “指针” 还是 “引用”。都是存储所指对象的内存地址。
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针。
或者说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
2. 警惕指针丢失和内存泄漏
写链表代码时,指针指来指去,很容易丢失。
如图所示,我们希望在结点 a 和相邻的结点 b 之间插入结点 x,假设当前指针 p 指向结点 a 。有如下错误示范:
p->next = x; // 将p的next指针指向x结点;x->next = p->next; // 将x的结点的next指针指向b结点;
第 1 行完成后,p->next 指针已经不指向结点 b,而是指向结点 x。
第 2 行代码相当于将 x 赋值给了 x->next ,自己指向自己。
从此结点 b 往后的所有结点无法访问,链表断裂。
因此插入结点时,一定要注意操作的顺序。所以上述代码第 1、2 行代码顺序颠倒一下就可以了。
同理,删除链表结点时,一定要记得手动释放内存空间。否则会出现内存泄漏的问题。
3. 利用哨兵简化实现难度
链表插入
首先,先看链表插入操作的正确代码:
new_node->next = p->next;p->next = new_node;
对于插入操作,第一个结点和其他结点的插入逻辑是不一样的:
// head 表示链表的头结点if (head == null) {head = new_node;}
链表删除
单链表结点的删除操作。若要删除结点 p 的后继结点,仅需一行代码:
p->next = p->next->next;
但若是要删除链表中的最后一个结点,也需要特殊处理:
if (head->next == null) {head = null;}
从上面分析可以看出:
针对链表的插入、删除,需要对插入第一个结点和删除最后一个结点的情况进行特殊处理。这样代码实现起来会很繁琐,那么如何解决呢?
哨兵
哨兵:解决的是国家之间的边界问题,此处的哨兵也是解决“边界问题”的。
不管链表是否为空,头结点 head 指针都会一直指向这个哨兵结点。
- 带头链表:有哨兵结点的链表
- 不带头链表:无哨兵结点的链表
由于哨兵结点一直存在,所以插入、删除不管哪个结点,都能统一为相同的代码实现逻辑了。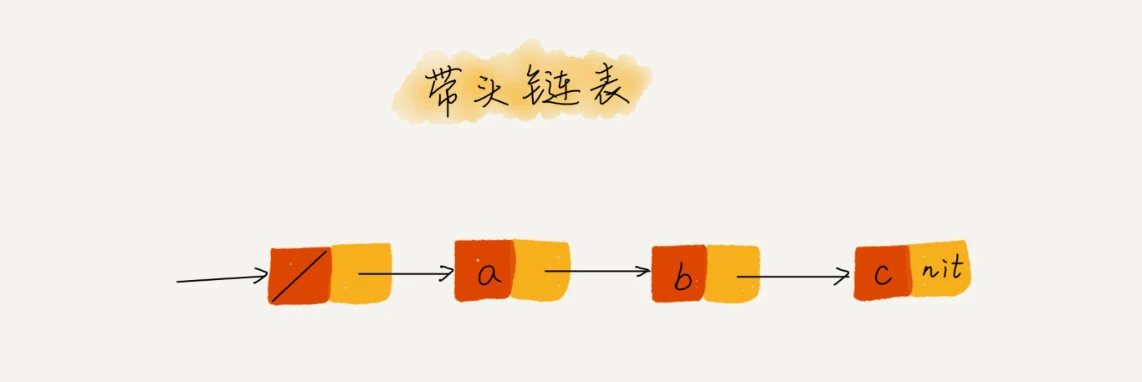
哨兵代码示例
利用哨兵简化编程难度的技巧,很多代码实现中都有用到,例如插入排序、归并排序、动态规划等。
代码一:
// 在数组a中,查找key,返回key所在的位置// 其中,n表示数组a的长度int find(char* a, int n, char key) {// 边界条件处理,如果a为空,或者n<=0,说明数组中没有数据,就不用while循环比较了if(a == null || n <= 0) {return -1;}int i = 0;// 这里有两个比较操作:i<n和a[i]==key.while (i < n) {if (a[i] == key) {return i;}++i;}return -1;}
代码二:
// 在数组a中,查找key,返回key所在的位置// 其中,n表示数组a的长度// 我举2个例子,你可以拿例子走一下代码// a = {4, 2, 3, 5, 9, 6} n=6 key = 7// a = {4, 2, 3, 5, 9, 6} n=6 key = 6int find(char* a, int n, char key) {if(a == null || n <= 0) {return -1;}// 这里因为要将a[n-1]的值替换成key,所以要特殊处理这个值if (a[n-1] == key) {return n-1;}// 把a[n-1]的值临时保存在变量tmp中,以便之后恢复。tmp=6。// 之所以这样做的目的是:希望find()代码不要改变a数组中的内容char tmp = a[n-1];// 把key的值放到a[n-1]中,此时a = {4, 2, 3, 5, 9, 7}a[n-1] = key;int i = 0;// while 循环比起代码一,少了i<n这个比较操作while (a[i] != key) {++i;}// 恢复a[n-1]原来的值,此时a= {4, 2, 3, 5, 9, 6}a[n-1] = tmp;if (i == n-1) {// 如果i == n-1说明,在0...n-2之间都没有key,所以返回-1return -1;} else {// 否则,返回i,就是等于key值的元素的下标return i;}}
对比两段代码,哪段代码运行得更快呢?答案是代码二。
执行次数最多的就是 while 循环那部分,我们通过一个哨兵 a[n-1]=key ,省掉了一个比较语句 i<n。当累积执行次数够多时,时间节省的就很明显了。
当然上述第二段代码可读性太差,此处仅举例哨兵作用,真实开发中不要这么写。
4. 重点留意边界条件处理
代码在一些边界或异常情况下,最容易产生 bug。
常用检查链表代码是否正确的边界条件如下:


若有收获,就点个赞吧
0 人点赞
